Read related articles on Intelligent agents and Search engines
Read related articles on Intelligent agents and Search engines

or: Information Brokering, new Forms of Using Computers, Agency,
and Software Agents in Tomorrow's Online Marketplace:
An Assessment of Current and Future Developments
We are living in a time of increasing information overload. Many solutions have been or are being drawn up to tackle this problem. However, today's most prominent solutions - such as Information Push and Search Engines - do not seem to be able to fully handle the problem. In this paper we will look at a number of solutions which may help us deal with information overload in the online marketplace. These solutions include "agency", agent-like applications, improvements in the information chain and - most importantly - information brokering. Some of these solutions require changes in the whole groundwork underlying the online marketplace; they are about whole new ways of interfacing with the online marketplace as well as the full employment of possibly intelligent software agents.

Contents
Preamble
The Internet of Today
From Internet to Online Marketplace
An Introduction to Ubiquitous Computing, Calm Technology and Augmented Realities
Tomorrow's Internet: an Ubiquitous and Agent-serviced Online Marketplace?
An Unobtrusive Agent Application: The Remembrance Agent
Concluding Remarks
Notes
Preamble
Mid 1996, the author graduated on the basis of his thesis entitled " Intelligent S oftware Agents on the Internet". Since that time, much has happened both in the field of software agents as on the Internet. Updating the thesis seemed a good idea, since a lot of exciting developments have come to the author's attention.
The subject of this paper differs in one important aspect from the agent thesis. Where the primary subject of the thesis happened to be intelligent software agents on the Internet, this paper takes a broader approach to the problems of information retrieval. The main topic of this paper is the online marketplace for information and services. Agents will play a role in this marketplace but they will not be the only actors.
We will focus on two developments in particular - intelligent software agents, and the concepts of Ubiquitous Computing (which will be referred to as UC) and Calm Technology (CT). These concepts will play an important role in the online marketplace.
"Consumer electronics, telecommunications, the computing industry, the entertainment industry and the media industry are all entering the digital arena. All information will be digital; all information will be inside computers and computers will be everywhere. While technological innovation contributes to human progress, some people experience the world as a technopolis that causes feelings of alienation and aversion with regard to technological products.People are still people and many of them are having a hard time trying to make sense of all the information around them. They are feeling bad about it. Yet, our ability to function and survive in the future depends on our ability to relate to information. Can we interact with this cybersoup in a meaningful way? Is there an alternative for the technocratic approach?" [1]
The Internet, Internet II, intranets, extranets, information superhighway, cyberspace - these terms in one way or another have all appeared in the media. A few years ago much of this seemed to be hype; today everyone seems to recognize the basic fact that the Internet has become a part of our lives. Networked information will only become more prominent in the future.
In the subtitle of this paper, the term "online marketplace" was used instead of the expected term "Internet". The concept of online marketplace extends beyond the Internet, intranets and extranets; it denotesan all-encompassing marketplace or network (available to all like some sort of utility) which will be the vehicle for sending, receiving and using all kinds of digital data, information and services. The term used to mean more or less the same concept is the "information superhighway". Some regard the information superhighway to be in its final stage of development; the Internet and intranets could be visualised as "lanes" on it. However, the metaphor of an information superhighway can be inappropriate at times so in this paper the "online electronic marketplace" will be used instead [2].
The media seems to be quite taken with the closest approximation of the electronic marketplace, the Internet [3]. In the media, dealing with massive amounts of digital information seems to be a significant trouble. The availability of seemingly endless amounts of information creates many exciting opportunities. However, many are overwhelming by the complexity and quantity of electronic data on the Internet. A few years ago, finding information on the Internet was possible by casually "surfing" networks and servers. If you were fortuante to locate a good starting point, finding the information you needed usually was not too difficult. As information grew exponentially, new ways of finding network-based information were needed.
Search engines such as Excite and Altavista or directory services such as Yahoo, soon became popular ways of getting to information you needed. At this moment, search engines and directories are still a very popular means of finding information.
"The vast majority of Web users find, or attempt to find, information using search engines; 71% of frequent Web users use search engines to find Web sites." [4]Yet, the effectiveness of search engines is slowly decreasing. When the results of a search engine search equal a list of thousands of links (or 'hits'), we are back at square one. New means of both offering as well as retrieving information and services are needed.
The Internet of Today
Never before has an information source been available through which massive amounts of information - covering a broad range - can be gathered. This information can be obtained conveniently - at times - and at unprecedented low costs.
The same story can be told for those wanting to offer information or services through the Internet. The barriers - as well as the investments needed - are very low compared to other media. Literally anyone can secure their fifteen minutes of fame in cyberspace. This aspect of the Internet has an important downside to it. There is very little supervision over the ways in which information can be offered and there are no rules governing the form of information. Organisations such as the Internet Engineering Task Force and the World Wide Web Consortium have developed various guidelines and standards for documents but to seemingly little avail. For instance, in HTML, metatags can be added to documents. These tags can be used to indicate the author of a document, its creation date and type; keywords can be included in these tags that best describe the document's content. At this moment, only a small percentage of all documents available on the World Wide Web (WWW) use these tags.
Search engines, currently the most popular way to search for information on the Internet [5], use these tags - when available - to classify a document. But as these tags are usually missing from a document, sets of heuristics are used instead to classify it; besides standard data, such as the date of creation and URL, a document is usually classified by a list of the most frequently used terms in it or by extracting its first 50 to 100 words.
The advantage of using such heuristics is that the whole p rocess of locating, classifying and indexing documents on the Internet can be carried out automatically and fast [6] by small programs called crawlers or spiders.
Today, this methodology is showing some of its flaws. While it is possible to index thousands of documents a day, there is a price that's paid - a loss of detail and a lack of a comprehensive summary of a given document's contents. Search engines return huge results as the answer to a query, some of which happens to be irrelevant or outdated. In addition, some users do not know exactly what they are looking for, let alone which terms best describe their search topic.
"[...] The short, necessarily vague queries that most Internet search services encourage with their cramped entry forms exacerbate this problem. One way to help users describe what they want more precisely is to let them use logical operators such as AND, OR and NOT to specify which words must (or must not) be present in retrieved pages. But many users find such Boolean notation intimidating, confusing or simply unhelpful. And even experts' queries are only as good as the terms they choose.When thousands of documents match a query, giving more weight to those containing more search terms or uncommon key words (which tend to be more important) still does not guarantee that the most relevant pages will appear near the top of the list. Consequently, the user of a search engine often has no choice but to sift through the retrieved entries one by one." [7]
Suppliers of information have their own unique problems. How can they get their information to their target audiences? As information sources grow, how do you stand out from the rest? Submitting information to a promotional service - to assist in the indexing process by search engines and directories - is becoming increasingly ineffective.
Personalised information is amplifying this problem. There are numerous Web services which create specific information 'on-the-fly' (developed with up-to-date or real-time information). Sites that use dynamic documents cannot be properly indexed by indexing programs - or crawlers - that most search engines use to gather data, as there are no complete or static documents that can be indexed. The information in those documents is hidden away from, or unavailable for, indexing programs [8].
One of the latest attempts to tackle this problem of information supply and demand is called Push Technology. This concept really is not as novel as some would like you to believe; the technique of basic server push (which is what Push Technology is basically about) has been around for a number of years. It is the specific way in which server push is used now and the way in which it meets certain market demands that has brought it into prominence. Push Technology has been covered extensively by the media and has been well received by both end users and content suppliers.
Apart from a look at the development of Push Technology, in this chapter we will also look at agent-like applications and intermediary services. This chapter is meant as a prelude and introduction to the rest of the paper; it is not meant to cover all important Internet trends & developments in an equal fashion.
A Prominent Change Driver: Push Technology
An increasing number of Internet users no longer wish to spend endless hours 'surfing' the Net, looking for the information they need. Many want to be able to indicate their interest in a given topic only once about to some service, and then receive information about these topics as it becomes available.
Push Technology has promised to provide information to a user on user-specified topics at a time interval and in a medium that are most appropriate and most convenient at that moment [9]. Push Technology has been around for almost two years. It seems safe to conclude that while it has not turned into the 'be-all, end-all' solution, it has had an important influence on Web browser development and on the ways in which consumers and organisations look at - and use - the Internet as an information marketplace.
Central to Push Technology are the so-called information channels; each subject for a user (such as the latest stock quotes) has its own channel. Each channel has properties such as determining the way in which information is displayed (via a screen saver, separate viewer, SMS messages), providing notifications of new information, and the developing customised "identities" of specific documents for users (only a summary or the entire document, or only when the user asks to do so).
Push Technology offers opportunities to both information providers as well as to information consumers, such as:
- information providers can target their information much more accurately. It will only go to those genuinely interested in the information that is send to them (since they actively chose to receive it) [10];
- users can rely on qualified push sources (such as CNN or Wired) to get their content. The authority of such content providers means that users will see reliable information;
- users no longer have to check their favourite sites to see if content has changed; if information has been updated, they will automatically receive a notification;
- many push applications are easy to use and operate, especially for novices.
Yet, Push Technology has it disadvantages as well, such as:
- when users receive their information automatically - eliminating the need to use the Web to find it - they may miss valuable and relevant information. The quality of information becomes strongly dependent on the service actually "pushing" it to you;
"If there's a drawback to Push, it may be that it could turn the Web into a more passive medium. Push enough content at me [every morning] and I won't need to explore the Web to find it - which could mean I won't find new stuff, either. Will the rise of Push mean the loss of serendipity, that sweet anticipation of surprise that Web surfers cherish?" [11]
- the range of topics as covered by most push publishers is not very broad. An alternative is to use a push service or application that works with an information profile. However, to create a profile a user will have to use just the right keywords to describe an information need;
"User-generated profiles are essentially one or more search queries that are saved by the push service to filter its various data feeds or channels. Creating and maintaining these profiles can exert a huge burden on users, assuming their information needs can be expressed in those profiles. Certainly, our information needs are constant to some degree: we always want to know the weather forecast for our hometowns, and there's not much that will ever change about that information need. And those kinds of needs are often satisfied by 'infopellets'.But when a user wants to know about 'trends in retail marketing to the 55 and older age group', there'd better be a pretty sophisticated profiling system that can handle such a complex query. And if after a while the user decides that she was really interested in 'purchasing habits of senior citizens', that profiling system better be as good as that librarian at figuring out how and why that information need changed, and how to adjust its retrieval to address this change. I doubt that users of push services will be bothered to maintain such profiles, even if they were sophisticated to handle such complexity." [12]
- Push Technology consumes considerable Internet bandwidth. Dr John Graham-Cumming wrote that:
"It was surprising to discover that almost a fifth of network traffic is derived from the use of Push Technologies. [...] Of the top Internet sites that are consistently visited, standard browser home page access accounted for 12% of network traffic generated by 70% of users, while Push Technology applications accounted for over 17% of traffic generated by only 12% of total users. The small number of users connected to push technologies are generating this large amount of traffic because of the continuous and automatic nature of push technologies, according to the study." [13]
- Push Technology makes large demands of both the client as well as the supplier. On the client side, a fast and preferably permanent Internet connection is needed, as well as a computer with a fast processor and plenty of of storage and memory. On the supply side, the investments in both time and money that have to be made are high. Push Technology server software is not inexpensive but requires a powerful server, a lot of storage and a fast Internet connection.
Several solutions have been proposed to circumvent these problems. One proposal calls for electronic mail as a Push medium. E-mail is by far the most popular communication medium on the Internet and a broad range of content can be delivered through it (such as complete Web pages, including graphics and applets provided a given mail program supports these formats). Incompatibility problems are virtually non-existent since all mail programs use the same standard (Simple Mail Transfer Protocol or SMTP) to send and receive mail messages, so e-mail could be a good push medium.
Other solutions are adding agent-like functionality to push applications or setting up sophisticated intermediary services (thus making it possible to offer a broad range of information channels from very specialised information providers). We will have a look at these two solutions in the next section.
When applied in the right way, Information Push/Push Technology can offer numerous opportunities, especially to content providers. Weather forecasts, sports, and news are obvious applications, but it seems like the less obvious applications, aimed at providing specialised information, are the most viable.
For example, the Web site of the American company Rent Net provides constantly updated apartment-rental listings and relocation help for thousands of cities. Rent Net's Push channel alerts people to listings that meet their specific criteria. Subscribers can then look at floor plans and do 3-D virtual walkthroughs.
Some say that push is dead. Whether or not they are right, Push has shown that many like the idea of having the information they need sent to them at regular intervals. If they can 'outsource' this task to others (be that applications or companies) then most are more than happy to do so.
Toward Agent Applications and intermediary Services
Today, information available through the Internet should - at least in theory - be "a mouse-click away" from anyone. If you cannot find what you are looking for by casual browsing or by working with a search engine, the right information is bound to be pushed towards you. As good as this may look in theory, the reality is different. Search engines often produce unsatisfying results, and the information pushed towards you does not fully cover your needs.
It seems to be the best time to (re-)introduce a familiar concept, "intelligent software agents" [14]. Many 'agent' applications have been launched on the market; however, most do not qualify as real agents. Their functionality could better be called agent-like [15].
"Agents, it seems, have popped up overnight in all sorts of applications, leaving some of the most savvy users fuzzy about what they actually are. This confusion, as you might expect, has resulted in some vendors' using the words "agent" to describe programs that don't even come close to the true definition of an intelligent agent. [...] This fraudulent activity has given agents a bad name, for many potential users now scoff at the concept and view the technology merely as marketing hype.
But if you look harder, even beyond the agent implementation available on the PC today, you'll discover that true agent technology is exciting, feasible, and desperately struggling to find its way into the mainstream as an enabling technology." [16]
Many agree that agent - or at least agent-like [17] - applications are becoming a necessity in order to cope with the enormous amount of information on the Internet. The question no longer seem to be if there will be a considerable usage of agents, but rather when it will happen.
The frenzy around Push Technology seems to have encouraged agent development in a special way, as several producers of push applications have teamed up with developers of agents. It was obvious to some that push's information channels were too restrictive and too limited to be of practical use to an increasing number of clients.
"Just as content can be customised, so the interactive options offered to Web users can be customised. This type of customisation is more powerful and more subtle than 'push'. By using agent-enhanced services to provide finely tuned interaction choices, a Web presence [can be developed] that lures and entices users rather than pushes at them." [18]Most of the standalone agent applications that are geared to searching the Web or Usenet are based on interfaces in which keywords, concepts, or even entire questions are stated in normal sentences. Agents are also used to assist users while they work with a software package. Microsoft's Office has these sorts of agents, presented as different characters. These agents present hints and tips to users as they are working with the software [19]. The agents provide assistance by queries in normal - natural language - sentences. The context of the user in the program helps in the process of providing an answer [20].
While most agents aren't that sophisticated at the moment, they already relieve the average user of many mundane tasks. These tasks usually do not really require much intelligence, but do require a lot of time or are just plain boring for a human to do.
"You can imagine thinking of an intelligent landscape inhabited not only by humans but by smartifacts - artifacts that are intelligent enough to have some degree of autonomy. [It] will be decades and decades before we have agents or devices intelligent enough to make people nervous. But we already have devices today that are sufficiently autonomous that they do things for us that are practical." [21]Although many current agents do not really deserve the label "intelligent", they acquaint users with their capabilities, an important first step towards future increased usage and acceptance of agents by a broader range of users.
Apart from software agents, intermediary services are another emerging development satisfying information needs. These services enable you to get news and information on almost any possible topic, not just the popular ones.
InfoWizard was one kind of source, a service where users created their own search profiles. InfoWizard provided access to not only the usual, free Web sources, but also to sources which required paid access (such as several pay-per-use databases). InfoWizard presented search results not as a long list of document links, but in a report-like fashion (the result list contained not only document references, but usually the entire document text as well). InfoWizard was discontinued on October 27, 1997 based on "competition from free, ad-supported Internet services" [22].
Services like InfoWizard will evolve in the near future. Some of these services will be free - offered by information intermediaries such as libraries or government agencies - while others will require some sort of fee.
"As the Net matures, the decision to opt for a given information collection method will depend mostly on users. For which users will it then come to resemble a library, with a structured approach to building collections? And for whom will it remain anarchic, with access supplied by automated systems?"[23]Large quantities of software agents combined with electronic intermediary-like programs (such as "Matchmakers" [24]) can be used to further enhance and enlarge the information chain. The next chapter will elaborate further on these new ways to consume and convey information.
From Internet to Online Marketplace
The whole information market or information chain should be concerned about choices, over the way you want to exchange (distribute or obtain) information, the media and interface you wish to use and last - but not least - the topics of interest.
The current Internet is about choices, but they are of a different nature. A publisher, instead of making choices about specific kinds of information and services for clients, needs to be concerned about technology - which Web browser or Push medium should be used, for example. Consumers and users of information have to deal with comparable problems in order to take advantage of the latest services and content. In short, all too often, both users and suppliers are conforming to technology, whereas the ideal situation would require technology to adapt to users and information providers.
A number of projects - undertaken by both academic and commercial organisations - are currently investigating ways to improve the information exchange process, by making it more flexible. One example happens to be search engine extensions. These extensions make a search engine's answers to queries more manageable by automatically aggregating results into logical categories which are adjusted on the fly, or they offer the ability to view results via a map-like interface. There are also new tools that make it easier for publishers and other content providers to easily add metadata to their content.
Although these are the first steps in the right direction, there still are two important elements missing: coordination and prioritisation. In other words, each party should focus on its own skills, delegating tasks to others whenever possible.
To illustrate some of the problems, let us take a look at a practise in which both many suppliers and consumers are engaged. To attract as much attention as possible, suppliers are advertising information and services to as many search engines as possible. These efforts often do not go unrewarded.
"Nearly 48 percent of a cross-section of over 1,500 website owners polled depend on search engine listings for the majority of their traffic, averaging 26,000 visitors per month. Over 70 percent of all websites generate at least 20 percent of their traffic from search engine listings, with the balance coming from advertising and other forms of promotion, repeat visitors and other sources. The survey data emphasizes the importance and value of website search engine submissions, which cost the website owner pennies per visitor, less than any other form of website promotion." [25]Many programs and commercial Web sites are available which will register a site's content with numerous search engines and other, similar services. 'Counterparts' of these programs and services are available for consumers. These client-side 'meta-crawler' applications send one query in parallel to numerous search engines, after which the program retrieves, filters and aggregates the results for the user.
This example illustrates how priorities seem to be badly defined: the supplier has to guess which search engines a consumer might be querying. A consumer, in turn, has to guess which search engines should be best used in order to find all (or some fraction) of the information on a certain topic. Both parties have to guess which keywords will describe their offerings or information needs. Both parties are not particularly good at both tasks, leading to predictable results.
On the current Internet, there are two ways in which information can flow from source to consumer:
- Information Pull, where a consumer or user takes (or is given) the initiative to get information; or
- Information Push, where a supplier takes (or is given) the initiative to deliver information.
For most of the Internet's history, Information Pull has been the most dominant force in the information market. A few years ago, this meant that consumers of information would take the initiative to visit a site to get information. Sites were discovered by casual browsing or by personal recommendations. As the number of sites and services on the Internet rose dramatically, Information Pull - in this form - began to lose its appeal as it became too time-consuming and laborious. As search engines and directory services (such as Yahoo) appeared on the Internet, they were able to restore most of Information Pull's utility, but this effect is now wearing off.
Information Push in the form of Push Technology arrived on the Internet about a year ago, in the form of such applications as PointCast and BackWeb. Its promise was to offer a strong alternative to information pull, and search engines. Until today, Push Technology has not been able to live up to all of its expectations and claims. Although it is not completely "dead", Push Technology has become more of a niche product. It can be interesting for certain information seekers. Push capabilities are being built into numerous applications and services (many Web sites use it to inform their readers about changes or additions). Yet, it has not been become the dominant way of getting information online. However, Information Push, in general is quite popular, at least in the form of mailing lists. Using mailing lists only requires an e-mail program, and the information received usually does not contain a lot of noise (such as 'spam') or other irrelevant information.
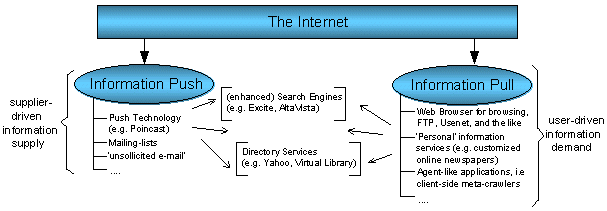
The following diagram gives a general overview of the current situation:
Diagram 1 - Current Organisation of the Online Information Chain
In this diagram we see supplier-driven Information Push on the left side, and user-driven Information Pull on the right side. The tools, services and techniques that are at the disposal of both parties are listed as well (these listings are by no means exhaustive). In the middle of the diagram are the tools and services that are used by both sides to get in touch with (or find) each other. The thin arrows pointing at the centre are meant to symbolise that there are many ways in which the parties can try to find each other. Their success is dependent on their own skills and experience. Comparing Diagram 1 with Diagram 2 explains how the current situation will compare to a possible new future organisation of the information chain.
Diagram 1 illustrates that the current situation is far from ideal. Earlier we noted that Push only seems to work for pushing 'mainstream' information (weather forecasts and stock information), coming from those sources that can afford to spend the time and money required to employ Push Technology. Many smaller suppliers still have to depend on their own creativity to reach the right users. As only about one fifth of all Internet users are using Push Technology, the majority of Internet users are still outin the cold trying to locate what they want. There are various ways in which these Information Push & Pull-related problems could be solved. In the next few sections we will look at a number of promising and interesting solutions.
Although it is not that apparent, developments in the long term in the area of information exchange, as well as with the Internet and intranets, seem to be towards increasing diversification of the entire information market. Diversification in turn enables increasing personalisation of information exchange.
This increasing diversification, and most certainly the increasing personalisation of information, could be a very logical next step. In many areas (of our lives or in an organisation's business), it is common practise to farm out certain activities or responsibilities to others. We often delegate our needs for certain kinds of information to specialists and organisations that have made this particular task their primary - or core - activity. For instance, we could visit as many bookshops as possible and subscribe to many magazines and journals. Instead, we elect to visit a library or to buy only certain magazines to relieve us from the task of gathering, selecting and editing all news and information that best fits our information needs. We make this decision because this activity or task does not belong to our core activities. Learning to do it on our own would just cost too much time and money.
Given the current state of affairs on the Internet, the need to outsource one or more Internet-related tasks and activities is growing. If the Internet is to become the basis for a future information and service marketplace, then much will have to change. Using the Internet now is time-consuming, laborious and quite often not very satisfying; many feel lost, unable to cope with seemingly endless amounts of information.
The first signs of such changes are becoming apparent in techniques and products such as Push Technology, software agent applications, and various kinds of personal (Web-enabled) current awareness services. While these are far from being perfect solutions, the general public is accepting and using them with great eagerness.
Of course, there will always be those who choose to satisfy their information needs on their own, because they are dissatisfied with selections offered by third parties (for instance through Push channels), or just because they like prefer their own control over information. However, most Internet users will happily rely on the capabilities of others to locate and filter information resources for them. There will continue to be many possibilities and alternatives available to fit individual's needs. Some will want extensive services and premium content and will be willing to pay the costs for such services. Others will use free or nearly free services such as those provided by libraries or by sites sponsored by advertising.
The bottom line of this introduction is two-fold:
- There will not be one or very few, but many ways and forms in which information can be offered and obtained, enabling each individual or organisation to choose among many ways that work efficiently;
- The whole process of offering and obtaining information and services through the electronic marketplace will be enhanced and catalysed in various ways, becoming more personal to fit personal needs and preferences. This added value and catalysing 'force' will be called agency.
In the next section the concept of "agency" will be defined and explained. It will be shown how this concept is intertwined with the two current information streams available on the market, as well as with a third, emerging one. We will then look at the concepts and techniques that play a primary role in these three trends (Information Brokering and software agents). The last part of this chapter will deal with the techniques and concepts that play a secondary role, those which are most likely to provide the necessary groundwork to make the whole system function properly.
Agency: Catalysing the Information Chain to the Next Stage
To make it possible to use the Internet and the future electronic marketplace at a higher conceptual level and in a task-oriented way, we will need some sort of 'cement' to build it. The term of "agency" is meant to be this sort of "cement". "Agency" can be described as the means (techniques, concepts, applications, etc.) to personalise, customise, elaborate, delegate, and catalyse processes in the online marketplace. The key characteristic of agency is that it does not influence the information, content or services that it helps. Agency makes processes in the information chain work more smoothly and in a more user-friendly way. It does not alter or influence the actual data.
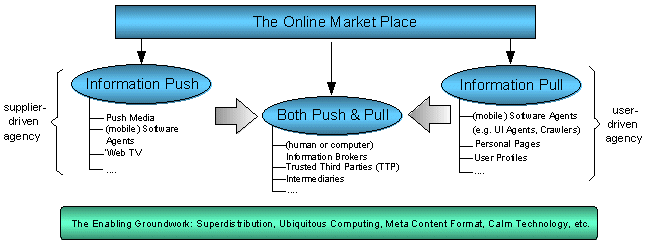
Three kinds of "agency" will emerge on the future online marketplace (see Diagram 2):
- Supplier-driven agency, which is closely related to Information Push. Current and future examples of this kind of agency are Push Media, software agents and Web-enabled television;
- User-driven agency, which is closely related to Information Pull. Current and future examples of this kind of agency are mobile software agents and personal newspapers; and
- A convergence of the two previously mentioned agencies, related to both Information Push and Information Pull. This agency involves intermediary services such as (human or computer) information brokers and their intermediaries.
Agency will enable people to focus primarily on what they want to do (which information they need, which task they would like to accomplish), and much less on how they should best do this (where to look for information or where to offer it) and which applications, services and techniques should be best used. This shift is not only necessary because it saves time and makes life easier, but also because it may be expected that many of the newcomers to the future online marketplace will be non-technical by nature and to some extent computer-illiterate. If this marketplace truly will be open and readily accessible, there should be few technological barriers. Agency will mean that information-seeking techniques will adapt to human needs, rather than individuals adapting to the parameters of specific techniques or applications.
In Diagram 2 an overview is provided of the structure of the information market as it could emerge in the near future. Next to each of the agencies, related concepts, techniques and applications are given (these serve as examples and are by no means exhaustive);
Diagram 2 - Future Organisation of the Online Information Chain
This illustration makes it clear that none of the mentioned techniques and concepts are 'be-all, end-all' solutions that will create the perfect online marketplace. Instead, the future will be about numerous possibilities for each individual to choose. Every choice will be determined by such factors as technical knowledge; familiarity with computers and computer applications; whether one wants information actively or passively; whether there are time and cost constraints; and, other elements.
In comparing Diagram 2 to Diagram 1, note the importance of a third party (or 'stream') to the information chain, which is related to both Information Push and Pull. In the next section this stream will be examined more closely. Later in this paper we will discuss two of the concepts and techniques mentioned in the diagram - Intelligent Software Agents and Ubiquitous Computing/Calm Technology/Augmented Reality. The other mentioned techniques and concepts (such as "Superdistribution") will be dealt with in the remainder of this chapter.
Information Brokering:The Information Chain's Missing Link?
"Information overload is the threat we all face, and therefore it is a huge opportunity for those who have the expertise to tame the information flow and supply it on time in the right measures." [26]The key characteristic of the concept of agency is that it 'merely' helps to enhance and improve the processes as they occur in the information market. A very special kind of agency will be a third party in the information chain. This party will enhance and catalyse the processes in it, just like the agencies of Information Push and Information Pull. It will do this by making supply and demand converge in the best possible ways. That is why this stream has been labelled "Both Push & Pull" in Diagram 2.
This third party has two very special characteristics compared to the other two parties:
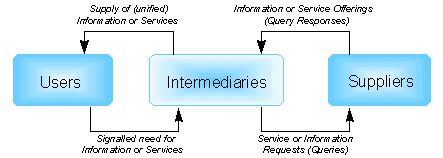
In a related concept, called "The Three Layer Model" [ 27], the Internet information chain would most likely function much better if, instead of having just two parties (or "layers"), you had three. Diagram 3 illustrates this model.
- It is supporting;
Whereas the agencies related to "Push" and "Pull" are indispensable parts of the information market, the "Push & Pull" agency is much more of a supporting nature. It offers all kinds of services - such as Trusted Third Party (TTP) services - and provides experience and expertise to others;
- Contrary to the other two parties, the information chain can (at least theoretically) still function properly when this third one is not present;
Technically and theoretically speaking, you could do without most of the services that are offered by these intermediary parties. It could be compared to the way in which a librarian assists in almost any kind of library. You could search a library's collections on your own, but you would probably save a lot of time and energy if you consulted the librarian, with the skills and experiences in finding information to fit your needs.
Diagram 3 - Overview of the Three Layer Model
Each of the individual parties is concerned with those tasks at which they excel. Each party has a matching type of agency (software agents), which supports them by relieving them of many tedious, administrative tasks which, in most cases, could be best handled by computer programs. In this way, agency enables humans to perform complex tasks better and faster.
The most prominent actors in the third 'stream' will be Intermediaries and Information Brokers [28]. Let me provide an overview of services that they could provide to other parties on the Internet.
First, let's look at how these brokers will fit into the process of information exchange. Each supplier will provide information brokers with 'advertisements' of all the information and services that a given supplier offers. The content of these advertisements will adhere to certain rules, conventions and possibly to a certain type of knowledge representation language (e.g. KIF or KQML), and it will only contain meta-information that best describes available information, documents, and so on. Advertisements will give a broker a concise, yet complete overview of all that a supplier has to offer.
When an information broker receives an information query, the broker should be able to determine (on the basis of all the advertisements it has collected) which suppliers it should direct the query to. The intermediary will not store any of the actual information offered by suppliers. Information brokers will never burden themselves with information maintenance tasks. Software-driven search engines, capable of processing thousands of pages a second, find it increasingly difficult to maintain their information base; few human or computer information brokers will pretend to be able to really accomplish this task [29].
In those cases when queries or advertisements are missing their required meta-information or context, an information broker can delegate this task to third parties such as specialised agents or thesaurus services. After a given query is sent to the appropriate sources, the information broker will eventually collect results from each source. Before these results are delivered, the broker will probably enhance the results by ranking them, removing double entries, and so on.
In short, an information broker uses input from information providers as well as from information consumers, in the form of advertisements and queries. It then may enrich this input with additional information (about appropriate/intended context, meta-information, thesaurus terms) and will then - based on the meta-information it possesses - try to resolve information requests [30].
There are advantages to this process. It greatly reduces the problem of updates for services like search engines as brokers only store meta-information about each source or service. This information tends to get stale at a much slower rate than the content itself. Meta-information is also several factors smaller in volume then most data currently stored and maintained by search engines. Finally, it is more efficient than the current situation.
What will be the main activities of Intermediaries and Information Brokers? These activities include:
- Dynamically matching Information Pull and Information Push in the best possible way.
Brokers will receive, gather and store information about both information and service needs (i.e. about the consumer domain) as well as about information and service offerings (about the supplier domain). By adding value - where and when needed - to the meta-information they receive (by adding all kinds of extra information and data such as information context), brokers will aim to make an optimal match between supply and demand.An example of this added value could be the pre-processing and refining of both consumer information queries as well as the responses from information suppliers. It may very well be that the content of a query will not exactly match a supplier's 'advertisements' (the list of offered services and information individual suppliers provide to the broker). A broker could then try to find the most appropriate match by adding extra terms to the query (based on the context of the query), or by using other means;
- Acting as a Trusted Third Party (TTP) to enable all kinds of safe (trusted) services to ensure the privacy and integrity of all parties.
To accomplish mundane and simple tasks, most probably won't have many objections to brokers and agents (intermediary agents, information agents). However, when their use leads to financial transactions or to authenticity questions, many will need a trusted and human third party.On the supply side, trusted third parties have several advantages to offer as well. For example, quite often parts of (or even entire) information sources are not indexed by search engines because the information is out of reach of a search engine's indexing facilities. Usually, this doesn't mean that the information is not available; it is just not available freely or directly, for a number of reasons. Trusted third parties can offer suppliers a sure and reliable mechanism to make information available to the public without losing control over it (that is, without the risk of leaving valuable information unprotected or losing revenues).
TTP-service brokers and intermediaries would also ensure the privacy of parties that are involved in some transaction, query, or any other activity, by relaying messages between parties without revealing their exact identity;
- Offering current awareness services; actively notifying users of information or service changes and/or the availability of new information or services that match their needs.
Many will ask intermediary persons and agents to notify them regularly, or even immediately, when a source sends in an advertisement offering information or services that match certain topics in a profile.Some controversy surrounds the question whether parties on the supply-side should be able to receive similar sorts of services. Should they see notifications when users have stated queries that match information or services they provide? Although there may be some who find this arrangement convenient, there are many that regard this process as an invasion of their privacy. Some could consider this a kind of "spamming".
- Bring parties seeking and supplying services or information together.
This activity is more or less an extension of the first function, a dynamic push and pull process. It means that users may ask an intermediary to recommend or name a supplier or source that is likely to satisfy some request of a certain kind. The actual queries then take place directly between information suppliers and the information seeking parties.Bringing in intermediary services in the information market immediately raises questions. Should you be told where and from whom requested information has been retrieved? In the case of product reviews, this information would be important. In the case of a bibliography, you may not be that interested in the individual sources that were used to compile it.
Suppliers, on the other hand, will probably desire direct contact with consumers. Unless specifically requested, it would probably not be such a good idea to fulfil this wish. It would undo an important advantage of using intermediaries: eliminating the need to interface with every individual supplier yourself.
- By using intermediaries, each party focuses on its skills and responsibilities.
No longer will it be necessary to be a "jack-of-all-trades"; by letting parties (themselves or their agents) continuously issue and retract information needs and capabilities, information (or more exactly meta-information about it) does not become stale and the flow of information is flexible and dynamic. This is particularly useful in situations where sources change rapidly;
- Using intermediaries is not required or enforced, and it does not demand the usage of proprietary techniques or software.
The choice whether or not to make use of intermediaries is not a choice between being 'compatible' or 'incompatible.' Information seekers are free to start or stop using them. Standards to state and interchange queries and 'advertisements' (such as the usage of KIF and KQML) however are necessary;
- By using this model it is no longer necessary to understand how individual Internet services operate and interface. Instead all efforts can be focused on the task at hand or the problem to be solved.
The network with its complexities can gradually descend into the background, and all of the services offered on it can become a cohesive whole. The whole online marketplace can be elevated to higher levels of sophistication and abstraction.
"Whenever people learn something sufficiently well, they cease to be aware of it. When you look at a street sign, for example, you absorb its information without consciously performing the act of reading. Computer scientist, economist, and Nobelist Herb Simon calls this phenomenon "compiling"; philosopher Michael Polanyi calls it the "tacit dimension"; psychologist TK Gibson calls it "visual invariants"; philosophers Georg Gadamer and Martin Heidegger call it "the horizon" and the "ready-to-hand", John Seely Brown at PARC calls it the "periphery". All say, in essence, that only when things disappear in this way are we freed to use them without thinking and so to focus beyond them on new goals." [31]
- Intermediaries will more easily be able to include off-line resources in their database of information sources.
While online information sources are very valuable sources for information brokers, they are not the only source of information available. Other important resources include printed materials, CD-ROM, large databases and human experts. Which of the available sources best fit a query depends on the type of information being sought, thoroughness, time and budget. 'Traditional' human information brokers already use this methodology when performing searches. For example, researchers at Find/SVP have access to the hundreds of publications that the firm receives each month, as well as more than 2,000 online databases, tens of thousands of subject and company files, hundreds of reference books, an extensive microfiche collection and computer disk sources. Using both online as well as off-line sources, Information Brokers will be able to offer information that is both more extensive as well as of a higher quality compared to the results of a query to a search engine. The owners of off-line sources (traditional publishers) will be able to extend their services to a growing online marketplace;
- As intermediaries work with meta-information instead of the content itself, higher-level services can be offered and higher-level information can be stored for all parties without excessive efforts. The responsibility for maintaining and advertising information and services remains with the source.
Brokers work with meta-information, which relates to an entire information source, instead of each individual document that a given source can supply (requiring only a fraction of the amount of space needed for complete documents). The time & energy that is saved by working with meta-information can be used to enrich metadata with additional contextual details. With these details, information queries can be executed more precisely and accurately.At the same time, suppliers of information and services will not have to deal with the traditional constraints of search engines, where only parts of their content and services are available. Instead, they will be able to supply rich and complete descriptions about the products. They can actively maintain, advertise and update this information at any moment; it's won't be necessary to wait for a search engine to visit a service to collect information about it. In addition, the source will control the meta-information that's available [32].
"Analyses of a site's purpose, history and policies are beyond the capabilities of a crawler program. Another drawback of automated indexing is that most search engines recognize text only. The intense interest in the Web, though, has come about because of the medium's ability to display images, whether graphics or video clips. [...] No program can deduce the underlying meaning and cultural significance of an image (for example, that a group of men dining represents the Last Supper)." [33]
- Intermediaries are able to offer asynchronous and priority-based query services.
In the current situation, it is usually not possible to issue a query, disconnect, and come back later to collect at the results (possibly after receiving a notification of their availability). It's also usually not possible to indicate the priority of a query; there are times when an immediate response to a query is needed. On other occasions, you wouldn't mind waiting for a query to be processed (you would be rewarded by paying lower costs [34] for the query).Intermediaries may be expected to posses personal information (e-mail addresses) of those sending queries. Personal details make it possible for brokers to offer asynchronous and priority-based services. They can also offer fee-based information and services based on usage.
The sudden potential for intermediaries, brokers and other go-between services seems quite ironic. Only a few years ago the media reported that the Internet would mean the end to information "middlemen" and intermediary services. When all the information and services you could possibly want are just a click away on the Internet, who needs brokers?
Following in the footsteps of this wave of "disintermediation" came plenty of software, cleverly labelled as "intelligent agents", giving everyone the power to fulfil every information need. Not very surprisingly, the first wave of "agent" applications has not been able to meet the expectations of users.
At this moment, it seems right to give both brokers as well as software agents a second chance. Some developments in this area show promising results, and may be expected to deliver appropriate applications which may improve daily information-seeking routines. These applications will not be technology-driven, but instead will user-driven. Amazon.com is one example of an intermediary service that has grasped this idea well. Feedback from Amazon.com's customers provides personalized recommendations for books and music based on individual purchase preferences, a kind of barter-like trade-off.
"Amazon [now] has a vast database of customers' preferences and buying patterns, tied to their e-mail and postal addresses. Publishers would kill for this stuff: they know practically nothing about their readers, and have no way of contacting them directly. That relationship has traditionally been monopolised by the bookshops, and even they rarely keep track of what individual customers like. Amazon offers publishers a more immediate link. "Ultimately, we're an information broker," says Mr Bezos. "On the left side we have lots of products, on the right side we have lots of customers. We're in the middle making the connections. The consequence is that we have two sets of customers: consumers looking for books and publishers looking for consumers. Readers find books or books find readers." [35]Amazon.com seems to have come up with the right concept at the right time - consumers appreciate the recommendations they receive as well as the contacts with other like-minded people (Amazon.com offers newsgroup facilities as well). The services seem to have struck the perfect balance between customers giving away some privacy (information about the books they like and the books they buy) and their receipt of personalised services (such as book recommendations).
"New types of middlemen will arise, based on information about the consumer that they own. [That is] less about brokering based on controlling access to product, but more about being intimate with consumers. [This] is just the sort of intermediary that online media such as the Web will enable. The trick is to fashion services that offer consumers or businesses a shortcut.Intermediaries exist in the real world for a reason, and those reasons don't go away on the Net."[36]
Services, like those of Amazon.com, have much to offer to customers as well as to suppliers but they leave one important issue untackled - how are they found? If brokering were to stop at this level, the current problems with search engines - as discussed earlier - would still exist. To develop a full-fledged third stream in the information market, higher level services will be needed. These services will provide universal access to brokering services.
It would seem most practical that when a single, central brokering service emerges, it would serve as an umbrella for all other brokering services. Both the information pull as well as information push parties would then have one single entry point that they could turn to for their information needs. Apart from the fact that this would soon lead to a colossal service (which would be difficult to maintain), the free-market spirit of the current Internet just makes this scenario unlikely. More realistically,numerous mega-brokering services and intermediaries operating side- by-side will probably develop. Multiple services will increase competition,leading to improved and more diverse services over time. Multiple options mean that individuals will be able to choose brokers that best fit their specific needs and means. Some will opt for free services, such as those offered by non-profit organisations, libraries or ad-sponsored services. Others may have a need for high-quality or speedy services, and will be perfectly willing to pay for such services.
Restricting itself to meta-information from the two other streams helps the third stream tackle a search engine's problem of keeping its information base up-to-date [37]. But there are other problems that search engines suffer from, such as their own lack of coordination and cooperation. Some brokers might be wise to adopt a supermarket-like strategy, making deals with a number of parties, which could be other more specific brokers, specific information sources, and thesaurus-like services (to improve query results). By doing so, they could cater to the broadest possible audience, providing bargain (bulk) discounts for all sorts of sources and services [38]. Parties from both information push and information pull streams can then decide whether some information need is best solved by a specialised service ( a specific 'shop') or by a larger, more general one (a 'supermarket').
A very different approach is to create dynamic networks of brokers (these networks include secondary services that aid brokers to perform their functions). Here, brokers become self-organising services, that engage in a process of continuous reconfiguration to respond to changes in their operating environment [39].
Brokering and intermediary services can be offered by both human as well as electronic intermediaries (software agents). Agent enthusiasts like to picture a world where human intermediaries are no longer needed, one where agents do all the work for you. Technological pessimists, on the other hand, think that humans will remain in the driver's seat when it comes to offering, seeking and brokering information and services in a sensible and intelligent manner.
The future situation will most likely be a mix of these two poles as electronic and human brokers have quite different, and often complementary, qualities and abilities. By combining the strengths of both, interesting forms of cooperation could be established. In the short term, this will most likely lead to a situation where a human broker takes care of the intelligence in the process, while a software counterpart (agent) will do the more laborious work, gathering and updating (mostly meta-)information about sources and seekers.
"Electronic brokers will be required to permit even reasonably efficient levels and patterns of exchanges. Their ability to handle complex, albeit mechanical, transactions, to process millions of bits of information per second, and to act in a demonstrably even-handed fashion will be critical as [the electronic marketplace] develops." [40]From that point on, these electronic 'bots will evolve from a cunning assistant to a helpful partner in the brokering process (although it will take years before we get there). This subject will be dealt with in more detail in the next section.
The most obvious users of brokering services are humans and human parties/organisations. However, brokers could also offer valuable services to software entities/parties, such as software agents. It seems logical to relieve human participants from the burden of locating certain kinds of information and services; why then, would we still want to burden software (like software agents) with the exact same task? If brokers can be of help to humans, they can very well be of help to software programs with comparable needs and problems. When brokers are able to provide up-to-date information on sources and services, agents will no longer have to keep track of which agents are (still) online or available. This will enable a given agent to issue a request without specifying a certain receiving party, since almost any party will be able to satisfy the request.
"[The Internet] is dynamic, and agents [will] presumably [be] coming online and going offline all the time. By inserting facilitators into the picture, the burden is lifted from the individual agents. Facilitators can keep track of what agents know or, as a second level of abstraction, may maintain locations of other facilitators, categorized by ontology or discipline. [In the future] commercial agent facilitators may act as brokers, striking cost-per-transaction deals with agents or other facilitators to satisfy requests or debit and credit accounts accordingly." [41]To make this kind of system work, a knowledge representation language is needed with which information and requests can be sufficiently well expressed. To keep things as open and as simple as possible, this language should become the standard for information retrieval tasks [42].
Speaking of standards, agents will also need to adhere to certain standards and protocols. It is unrealistic to make all parties in the information market account for all of the possible kinds of agents. Agents should respond and react similarly (regardless of their internal code and structure) to certain requests or questions. However, the standards or protocols used in this process will have to be flexible in order to anticipate issues and developments that are unforeseen at present.
Which broker will be the best to use in general or in some particular situation? In the short term, this will be a process of trial and error. Just as with search engines, brokers and intermediaries will ultimately be judged - and appreciated - by the results they deliver, and possibly by the price they ask for doing so. In the long run, tools might become available which will help to determine which broker to use in a certain situation, for a special task or at particular costs.
The Rebirth of Intelligent Software Agents
In media coverage on the online information market, "software agents" are frequently mentioned. This is not surprisingly, as software agents are a versatile design model for online applications and services.
The concept of "agency" is one way in which a true software agent could be put into use. It is a first step on the long road towards different kinds of software and hardware.
"The complexity of computer interfaces has accelerated recently. The prevalent view has been that a computer interface is a set of tools, each tool performing one function represented by an icon or menu selection. If we continue to add to the set of tools, we will simply run out of screen space, not to mention user tolerance. We must move from a view of the computer as a crowded toolbox to a view of the computer as an agency - one made up of a group of agents, each with its own capabilities and expertise, yet capable of working together.[...] The paradigm of thinking of software in terms of self-contained and isolated applications is becoming rapidly obsolete. Computing environments are getting more and more complex, and users are getting tired of the artificial barrier between applications. Users want to work with text, graphics, communications, programming, etc. seamlessly in an integrated environment.
Agents are seen as a way of supplying software that acts as the representative of the user's goals in the complex environment. Agent software can provide the glue between the applications, freeing the user from the complexity of dealing with the separate application environments." [43]
Integration of diverse applications, services and information via 'agentification', agent-mediated interfaces, and the like are important advantages agents can offer. Other key agent characteristics include proactivity, being able to perform social actions, autonomy and being personal [ 44]. An important remark to be made here is that agents in this respect will distinguish themselves from such techniques as Push. All agents will probably share a common design model; they will differ in the ways they assist users, in the functions and tasks on which they focus & in which they specialise. Many in today's electronic marketplace are eager to use agent-like search tools and services. Most feel they would help in finding needles in the online information haystack.
"There is nothing, to my mind, inherently creative in the process of gathering information on the Web. It is, as anyone knows who has had to do it, an arduous and boring process to drift though site after site in search of the key nugget of information amongst the piles of digital detritus. By all means let us take that process out of human hands. It is what we do with the information when we get it which is, for me, the determining factor in the debate." [45]After the time-consuming information gathering process has been completed by agents, humans can continue the process using commonsense and knowledge to extract what is exactly needed.
"Agents are not capable of synthesising the information they collect to create fresh insights, and a new understanding neither are they meant to do so. Their role is to assist and enable, not to entrap us in their own process - if they do that then they are simply badly designed." [46]In short, agents will save time and solve problems by automatically handling those tasks that are best handled by a computer program. This feat will be accomplished by adding "agency" to those applications we use on a daily basis and to the environments we work in. By functioning collectively, agents and agencies will be able to display complex and helpful behaviour which might even be considered "intelligent" [ 47]. This approach differs strongly from the individualistic and non-cooperative nature of current information agent applications. Most of them function like a meta-engine by querying the most popular search engines in parallel and performing some type of post-processing after the results have been collected. Usually they do not bring their users much closer to solving information overload, which should not come as a total surprise.
"People have been working on database query systems for decades. Smart people. Very structured data. Narrowly scoped problems. And we got SQL. Maybe some 4GLs and relational databases. Perhaps extensible to distributed databases - even heterogeneous ones.Now there is the Web with its tons of completely unstructured data, mostly in natural language, distributed randomly. So what is the new breakthrough in query technology for this much more difficult problem? So new 'intelligent agents' are going to extract information from the Web for us? Excuse me?" [48]
Enabling communication between agents and 'non-human' parties (other agents, Web servers, computer applications) - something that is not possible with current agent implementations - looks like the most promising route to circumvent this problem. With this framework in place, information searches can be distributed over a large number of specialised gathering programs (crawlers). In this way the workload is distributed over several entities and several parts of the network. It also becomes easier to coordinate the task and prevent unnecessary work from being done.
At the moment, this is still a dream; apart from the fact that stand-alone agents (let alone networked ones) haven't matured yet, there are no solid, agreed-upon standards - standards for exchanging knowledge, standards for distributed code, to name but two. Technically speaking, there are some widelyaccepted techniques for these purposes (KQML, KIF, CORBA), so the problem isn't of a technical nature. It involves instead market forces (and parties) that haven't reached an agreement on which format, language or technique to use. The widespread use of HTML points out that a widely accepted process can be developed within a few years.
The Enabling Groundwork
Information Brokering, agency and personalisation of information and services are powerful concepts, which all have one important presupposition in common: the availability of a solid (technical) basis to built upon. "Brokering", "Agency", and most of the other terms that have been introduced in this section are concepts: they say very little, or nothing at all, about the techniques that should be used to accomplish and built them or about the enabling groundwork they presuppose. We will look at techniques and methods that are readily available, or emerging today, which may substantially contribute to the realisation of this necessary foundation.
Earlier we examined the concepts of agency and intelligent software agents. Both concepts rely on code or computing that is - to a certain degree - mobile and of a ubiquitous nature. "Ubiquitous Computing" is not some vague concept for the future, but rather it is now playing a part in current work.
At first sight, mobile computing and mobile software agents may look interchangeable. In media coverage about mobile code, mobile computing and mobile agents, these terms are often interchanged even though they are really about quite different matters.
"Mobile computing" refers to ubiquitous access to information and services "anytime, anywhere", from cellular phones to desktop personal computers, from disconnected operation to fast network links. "Mobile agents" refers to itinerant programs, capable of roaming networks by migrating code and program state (thereby minimising network usage). The mobility part of both terms is of a different kind: "mobility" in the context of "mobile computing" is largely of a physical and continuous nature, whereas the mobility in "mobile agents" is more of a logical and discrete nature.
Java is an example of a technique that is closely related to, and showing the possibilities of, mobile computing [49]. Because of its platform-independence, applications can be built that do not need to pay much attention to the exact type of computer that is used to execute them. Not only does this make a programmer's job easier, it also enables the users of such applications to access and execute these applications regardless of their location (computing becomes ubiquitous). Current Web browsers show this functionality as well; you get information and services from virtually anywhere on the network as long as you have access to some device equipped with a browser or similar application [50].
In mobile computing the user will typically supervise a given activity; the main aim of mobile agents is to let them do as much of the supervision of an activity themselves. Picture the situation where a user wants to query a search engine for certain information [ 51]. The user could query a search engine but this could take a lot of time and the user would probably have to go through a long list of results. Now suppose a mobile agent interacts with a search engine, using its own search methods, instead of the ones that are normally offered as part of a human interface. This option of utilizing an agent has two major advantages: the user does not have to stay online while the agent is working on the query (so if the agent uses a search method that takes more time, the user will not be affected by this), and the agent can process the intermediate results locally on the server. The agent will only return to its user with the final results of the query, thus saving a lot of network bandwidth.
Security is an important concern often voiced over mobile agents (and to a lesser degree with regard to mobile computing).
"Although there is no shortage of potential applications for mobile agents, the technology raises a few concerns - probably the biggest being security. With an established infrastructure of mobile agent hosts that give agents access to local resources, virus writers and other rogue programmers could have a lot of fun." [52]Most of the security issues are not unsolvable. Many of these issues regarding mobile agents also apply to the Internet in general. Many other applications and techniques 'suffering' from these same security threats continue to be developed. There seems to be no valid reason to treat mobile agents differently in this regard. So, assuming the security issues surrounding mobile agents can be adequately addressed, what sort of powerful applications are available for mobile agents? In an IBM paper on mobile agents, this question is answered in the following way:
"While none of the individual advantages of mobile agents [...] is overwhelmingly strong, we believe that the aggregate advantages of mobile agents is overwhelmingly strong, because they can provide a pervasive, open, generalized framework for the development and personalization of network services. And while alternatives to mobile agents can be advanced for each of the individual advantages, there is no single alternative to all of the functionality supported by a mobile agent framework." [53]In other words, the point of mobile agents - and of mobile computing as well - may not be any individual application, each of which could alternatively be implemented using a more traditional distributed processing scheme. Rather, it may be that both have so many potential applications that it would seem most unwise to ignore them or to leave their potential unused.
Green et al. name four concepts that are vitally important to multi-agent systems: coordination, cooperation, negotiation and communication [54]. For single mobile agents, these concepts need not be of importance as they could do all the work on their own. In the context of information brokering and similar applications, their importance becomes evident; standards-based mechanisms and means to communicate and negotiate with all kinds of parties (humans, mobile agents) are at the root of such services and applications.
Trust is an important issue relative to all four concepts. As ideal as an environment of cooperative and honest participants (software agents, humans) may be, the online marketplace may be expected to be inhabited by different parties, each with their own goals in mind. Some feel that game theoretic techniques and a reliance on conventional social rules and conventions will be the best means to deal with the issue of trust.
The way we currently gather, read and process information online - and on our computers - is far from ideal. Let's look at two aspects of this process, and how they can be changed.
Although we have to wade through large amounts of information every day (especially when working online), we currently have to work with basicly a page-based, two-dimensional interface. It is tiresome to browse or skim through large amounts of information, like a group of reports or the results list of a search query. Why not present the information in a visually more attractive and more ergonomic way? Generally speaking, three-dimensional graphs, three-dimensional trees and similar visualisation techniques are much more suitable for a display of large amounts of data. Additionally, the current way of interfacing with online information and services is not very suitable for those who are not technically skilled. If the Internet will be the information medium of the future, then it should appeal to more than just a technologically facile minority.
Research on this problem has been focused on certain features of the interface, providing visual cues instead of text.Visual cues have important advantages over text: the human eye can process visual information (such as colours and graphs) quickly [55] and as a result much more information can be conveyed in a way that is less stressful to the reader. The concept of Calm Technology (CT) is centred entirely around this philosophy. Here, items of great interest are moved to the foreground, while less interesting objects (or information) are moved to the rear or to the background (called periphery in CT). Another enhancement to the interface includes the addition of three-dimensional elements. By adding a third dimension, more information can be displayed in the same or less space (enabling such possibilities as real-time delivery of complex information). An additional advantage is that it is easier to preserve a sense of context [56].
"How does anyone find anything among the millions of pages linked together in unpredictable tangles on the World Wide Web? Retrieving certain kinds of popular and crisply defined information, such as telephone numbers and stock prices, is not hard; many Web sites offer these services. What makes the Internet so exciting is its potential to transcend geography to bring information on myriad topics directly to the desktop. Yet without any consistent organization, cyberspace is growing increasingly muddled. [...]More sophisticated algorithms for ranking the relevance of search results may help, but the answer is more likely to arrive in the form of new user interfaces. [...] True, the page metaphor used by most Web sites is familiar and simple. From the perspective of user interface design, however, the page is unnecessarily restrictive." [57]
This increased awareness of virtual surroundings can make information access a more exploratory process. Information seekers will not have to worry that their curiosity will force them to lose sight of their original goal. Browsing indeed may lead to new ways of looking at digital information.
"The potential for innovative user interfaces and text analysis techniques has only begun to be tapped. [...] In the future, user interfaces may well evolve even beyond two- and three-dimensional displays, drawing on such other senses as hearing, to help [people] find their bearings and explore new vistas on the information frontier."[58]A second, remarkable trait of the way we currently process information is the strong focus on applications and techniques while working with information. Ideally, it should not matter if information is in a Microsoft Word file, a mail folder, or on a Web page; however, at this moment it does matter. It is not easy - and sometimes even impossible - to combine information from different formats and sources.
Fortunately, there are efforts to change this situation. For example, the leading Web browser developers, Netscape and Microsoft, are changing their browsers from applications that simply fetch and display Web pages into either a complete layer on top of a computer's operating system (Netscape) or as an integral part of an operating system (Microsoft).
"The browser becomes invisible by becoming ubiquitous. It submerges inside other programs, removing itself from our consciousness. The browser becomes the intellectual equivalent of a telephone switchboard. The operator who once connected your long distance call was a selection device to find the right person at the other end. Now, when your modem dials an ISP, phone company switches are still selecting, but the switchboard - once the defining experience of telephony - is gone. It becomes a historical legacy. Just as in the new networked media, the browser - now the Net's defining metaphor - is dying as the main event, to be reborn as a subsumed function and occasional option." [59]A different approach is taken with the Meta Content Format as developed by Apple Computer. Here, the goal of removing boundaries between documents is not reached by continuously extending the application (Web browser) so it can handle more types of information. Rather the structures used for organising information are standardised. Apple describes MCF as
"a rich, open, extensible language for describing information organisation structures. Information management systems that use MCF can provide many useful and interesting functionalities such as the integration of information from an open-ended list of sources (desktop, web, email, etc.) that can be viewed using different metaphors (tree views, web views, flythroughs, etc.).[...] Organizational structures for content, such as file systems, emailbox hierarchies, WWW subject categories, people directories, etc. are almost as important as content itself. The goal of the Meta Content Framework (MCF) is to provide the same benefits for these structures as HTML provided for content." [60]
The central concept of MCF is the use of rich [61], standard [62], structured [63], extensible [64], compositable [65] descriptions of information organisation structures as the core of information management systems. Information, in this way, comes first, not the application needed to process and handle it. Currently, each application has its own methods of structuring information. These structures do not say much about the information itself (the content), focusing on the organization of information ("meta content"). They are usually neither very elaborate nor very expressive.
"We claim that the lack of an expressive, open standard for representing these structures is at the root of many of our information management problems. In fact, we have become so accustomed to these problems that we hardly even regard them as problems any more." [66]The goal of MCF is to abstract and standardise the representation of the structures that are used for organising information (meta content structures) [67]. In addition to the usual benefits of open standards, MCF will also make it possible to use information utilities (viewers) that work across different types of information. Note that MCF is not some kind of technique or application that needs to be installed on a desktop or a server. It is purely an architecture that does not require specific software or hardware to be implemented. Unlike the adoption of component architectures such as OLE, where an application is either compliant or not, information managing applications can incrementally adopt and implement MCF. MCF opens up all kinds of possibilities.
"Today we use many different viewers to view different kinds of structures. [...] Ideally, the viewer used should be a function of the users preferences and properties of the data (such as the density of the graph being viewed) and not of whether one is viewing files or email messages. Furthermore, the user should be able to use multiple metaphors for viewing the data, flipping between different viewers to get a better feel for it.MCF Viewers are viewers for MCF structures. The entities in the structure might denote any kind of information object. The viewer does not care about this. When the user want to perform some action on the content, such as edit it, the viewer asks the [underlying information managing application] to perform it." [68]
Where there are multiple types of information viewers available (HTML-based viewers, domain-specific viewers) a user is no longer forced to exclusively chose one viewer over an other. Instead, the viewer that is best for that moment or on that occasion can be utilized. This could very well lead to the same kind of explosion in tools and utilities. MCF, then, acts as a lingua franca that enables the integration of different information sources.
MCF could open up many interesting possibilities in i nformation storage. When you use MCF to decouple information and information-managing applications, there is no longer a reason to store information in a format or at a location that is partially or entirely based on a given application.
To illustrate the use of MCF as a schema translation middleware, a prototype program called BabelFish has been developed. It enables a user to request data from multiple heterogeneous information sources such as databases. Normally, a user would have to be familiar with the semantics and formats of the sources (databases) to answer a question. BabelFish uses a machine understandable language (MCF) for describing the semantics and data formats of database tables [69].
Babelfish offers two important benefits. First, it can provide dynamic and distributed integration; two databases that were designed and built independently can exchange information, without any human intervention. Secondly, as the MCF Query does not contain any data source or data schema-specific information, the schemes of the back end data sources can be changed without affecting the MCF Query [70].
When you effectively want to implement brokering, a mechanism is needed where consumers can be sure that the information they receive is authentic and unaltered in any way, and where suppliers or publishers can be sure that the information they provide is supplied and distributed without any threat of copyright infringement or revenue loss. A system is needed where documents can be distributed in such a way that they cannot be altered, read, copied, printed or otherwise processed without permission. Superdistribution and digital containers offer such mechanisms.
A digital container is an envelope around a document which handles all processing of the document contained inside it. With the aid of this wrapper, the author or publisher of the document can set the operations that can or cannot [71] be performed on the document. The wrapper also acts as a certificate of authenticity, so that the recipient can be sure that the contents of the document have not been modified or altered. The electronic envelope will also make it nearly impossible to simply copy the file and distribute it to others.
What is "Superdistribution"?
"Superdistribution is an approach to distributing software in which software [or other content] is made available freely and without restriction but is protected from modifications and modes of usage not authorized by its vendor [or distributor]. [...] Superdistribution relies neither on law nor ethics to achieve these protections; instead it is achieved through a combination of electronic devices, software, and administrative arrangements [...]. By eliminating the need of vendors [or publishers] to protect their products against piracy through copy protection and similar measures, superdistribution promotes unrestricted distribution of [software or other content]." [72]The concept of superdistribution was invented by Ryoichi Mori in 1983. It was first called "software service system", hence its software-orientedness. Since then, the concept - or parts of it - have been used for various superdistribution-like mechanisms.
Superdistribution provides a mechanism that meets the demands and needs of both the suppliers (vendors) as well consumers (users) of information and software. The main idea is that content (software or information) can be distributed and forwarded to others freely. By using some kind of digital container, it is not possible to make illegal copies of the contents nor to tamper with the contents. "Passing on" digital information in the context of superdistribution means that a copy of the container is created, usually with the aid of an application, which is identical to the original and which possesses the same access restrictions that were imposed on the original. As a reward for redistributing content, some superdistribution schemes may give a direct reward or some discount on new content. This scheme creates possibilities for all kinds of value-added services that can be provided to consumers. For instance, an organisation can collect content and review it. They can then add a small fee to the total costs of every individual piece of content for this service, which they will receive from every person that gets a copy of this content (no matter how far "downstream" the content is consumed).
Other important advantages of using superdistribution and digital containers are:
- As content may be expected to be consumed and redistributed, the price per copy of the content can be kept low on the scale of micro-payments, which should be more than acceptable for the average consumer;
- As the price per copy is low, tampering with the content is discouraged as a person doing so will end up making higher costs (in terms of time and money spend) than what it would cost to just pay for a copy;
- Consumers do not have to take a subscription to get high-quality content. Subscriptions would be an overkill for someone only needing one specific article from a given magazine or journal. Another problem with subscriptions is that authors who want to link to other sites for background information will rarely opt to link to subscription sites because they will know that the majority of their readers will not be able to follow the links. Similarly, search engines are usually not able to index subscription sites.
The Internet is by nature a rather 'anarchistic' network, as it is not centrally managed nor can it be claimed by one person or organisation. Some argue that if the Internet and the online marketplace in general are to become useful, then central supervision along with rules and laws are needed.We have described a number of mechanisms and concepts which should make it clear that this statement is too black-or-white, that you can have the former without having the latter. For example, mechanisms such as superdistribution and digital containers make it possible to have a free and tamper-proof flow of content without the need for some organisation directly supervising the whole process. Agency and software agents will ensure that not just the technically skilled participate on the Internet, but that many can make use of it without the need to consult or hire others for many basic, information-seeking activities.
In the next chapter, we will have a look at three concepts that are expected to help non-technical parties utilize the Internet: Ubiquitous Computing, Calm Technology and Augmented Reality. Also, we will have a closer look at software agents; delegating tasks to agents or agent-like applications will become a necessity for both technical skilled as well as non-technical persons, as information and services continue to increase on the Internet.
An Introduction to Ubiquitous Computing, Calm Technology and Augmented Realities
Future access to the Internet and the World Wide Web may not always be through desktop computers. Common equipment, like telephones or even household appliances, will connect to the online information and service marketplace. Many may not even be aware of which appliances are actually connected. Instead of individuals actually making a connection to the network, their tools will automatically connect to it without personal intervention. This concept - as invented by Marc Weiser - is called "Ubiquitous Computing".
"The Concept of computers as things that you walk up to, sit in front of and turn on will go away. In fact, our goal is to make the computer disappear. We are moving towards a model we think of as a 'personal information cloud'. That cloud has already begun to coalesce in the form of the Internet. The Internet is the big event of the decade [...]. We'll spend the next 10 years making the Net work as it should, making it ubiquitous." [73]The goal of Ubiquitous Computing is to move computers away from the central focus of users and into cupboards, behind walls, etc. where they are used subconsciously, to enhance existing tools or communications. This whole new way of interfacing with computers and networks offers many exciting possibilities.
"It can drag interactivity away from technological fascination and wizardry into the realm of human experience and action. What is being designed is no longer a medium or a tool in the traditional sense, but something far more intangible, embedded in a continuously changing environment where everything is connected to everything else." [74]This section will examine the concept of Ubiquitous Computing (UC) as well as the concept of Calm Technology (CT). CT extends the notion of UC and uses its principles to create technology that utilises both the centre and the periphery of a user's attention. We will also examine "Augmented Reality" which makes heavy usage of the principles of UC. It enhances a user's perception of computation by enhancing physical objects (such as a desk).
We need new ways to interface with our computers and the online marketplace. We also need ways to cope with a great deal of digital and traditional information. The concepts of UC and CT seem to have the potential to deal with many issues in this area. Some, like Marc Weiser, are even convinced that Ubiquitous Computing will be the next major wave in computing.
"The defining words [for the third wave in computing] will not be "intelligent" or "agent", but rather "invisible" and "calm" and "connection".[...] The first wave of computing, from 1940 to about 1980, was dominated by many people serving one computer. The second wave, still peaking, has one person and one computer in uneasy symbiosis, staring at each other across the desktop without really inhabiting each other's worlds. The third wave, just beginning, has many computers serving each person everywhere in the world. I call this last wave 'Ubiquitous Computing'." [75]
Ubiquitous Computing (UC)
The main aim of Ubiquitous Computing (UC) is to embed many small and highly specialised devices within our everyday environment in such a way that they operate seamlessly and become transparent to the person using them. One of the analogies that Marc Weiser uses to visualise this disappearance of computers is the way in which we use such devices as servo motors. Once upon a time these motors were of considerable size and required a lot of attention. Now, servo motors are small and so common that we no longer pay much attention to them at all. When we operate a car, we do not think of all of the components of an engine and drive train that make locomotion possible.
In short, the three main aims of UC products are to be everywhere (by being portable), to be small, and to be aware (of its environment and of its user). These aims give users complete freedom of movement as well as freedom of interaction. Making computing ubiquitous will make computing more attractive to those who find the current way of interacting with computers and networks distant, foreign and not very inviting.
Although the idea of computers or computing devices being everywhere and inside everything may sound rather intimidating at first, UC could help us with the problem of 'information overload' in very special ways.
"The idea of integrating computers seamlessly into the world at large runs counter to a number of present-day trends. 'Ubiquitous Computing' in this context does not just mean computers that can be carried to the beach, jungle or airport. Even the most powerful notebook computer, with access to a world-wide information network, still focuses attention on a single box. By analogy to writing, carrying a super-laptop is like owning just one very important book. Customising this book, even writing millions of other books, does not begin to capture the real power of literacy.Furthermore, although ubiquitous computers may employ sound and video in addition to text and graphics, that does not make them 'multimedia computers.' Today's multimedia machine makes the computer screen into a demanding focus of attention rather than allowing it to fade into the background." [76]
The first phase of Ubiquitous Computing will be one where there are hundreds of computing devices ranging from the size of a memo pad to wall-size boards. In this first phase of UC there will be wireless networks (needed to connect the devices), shared meeting applications, and location-based services (telephone calls are re-routed depending on location and time). Marc Weiser envisions the future with UC as one where "imbedded computers [...] will bring other worlds to us in new ways - sometimes in ways so unobtrusive we will not even notice our increased ability for informed action." As an example Weiser describes the kind of tune in a future alarm clock: "the kind of tune [it] plays to wake me up will tell me something about my first few appointments of the day. A quick urgent tune: 8 am important meeting. Quiet, reflective music: nothing until noon". In this way, the computer "can be suggestive without being intermediating". Ubiquitous Computing would allow us to focus on those issues that are really important, interesting and challenging.
To make true UC possible, research needs to be done to develop the required techniques, hardware and software. This research will include several research areas related to such issues as [77]:
- Low Power
One of the first requirements of small, ubiquitous devices is that they are inexpensive, low-power devices. No one wants to have to change the batteries in hundreds of devices every year. Therefore a source of cheap, inexpensive power is needed as well as low-power components to match [78];
- Low Cost
Research is being done in order to create inexpensive devices which can connect to the Internet. The trend will be toward small and disposable computers;
- Mobility
Mobility is the focus of much current research. This will result in a network which can support mobile applications and devices;
- Mobile IP
Currently, the Internet Protocol (IP) assumes that the location and connection of a computer remains fixed. With Mobile IP, a computer - and its user - can roam and maintain the same IP address. Basically, Mobile IP works by assigning a home agent on the permanent network for a computer. When the mobile computer (or the 'mobile host') moves from one network to another, it notifies its home agent of its new location. The home agent then intercepts and forwards packets destined for the mobile host [79];
- Mobile Applications
Applications will need to move off of a workstation onto a tab, or perhaps the application will move with the user;
- Effective User Interfaces
Ubiquitous devices are meant to be practically invisible and casually used. That means the user interfaces must be simple, apparent and obvious as an awkward user interface could negate the whole purpose of the device.
Calm Technology (CT): Increasing Supply without Increasing Demand
If Ubiquitous Computing meant 'only' putting computers everywhere, it might still be overwhelming to deal with all of the information generated by these devices. It is for this reason that UC goes hand in hand with a special technology that enables users to retain a sense of control. This new approach is called "Calm Technology."
The greatest strength of Calm Technology lies in the fact that computers are made to conform to their users, not the other way around. Information is presented in a manner that a user determines, and it is easily accessible. The user is not distracted or slowed down by Calm Technology; more can be done with less effort.
"Designs that encalm and inform meet two human needs not usually met together. Information technology is more often the enemy of calm: pagers, cellphones, news services, the World Wide Web, email, TV, and radio bombard us frenetically." [80]What is it that makes one technology calm, whereas another technology is perceived as overwhelming or irritating? The difference is in the way technologies engage our attention. Calm Technology (CT) engages both the periphery as well as the centre of our attention and can easily move between the two. The term "periphery" is meant "to describe what we are attuned to without attending to explicitly. Computer scientist, economist and Nobelist Herb Simon calls this phenomenon "compiling"; philosopher Michael Polanyi calls it the "tacit dimension"; psychologist T. K. Gibson calls it "visual invariants"; philosophers Georg Gadamer and Martin Heidegger call it "the horizon" and the "ready-to-hand", John Seely Brown at PARC calls it the "periphery". All say, in essence, that only when things disappear in this way are we free to use them without thinking and so to focus beyond them on new goals." [81]
It should be clear that what is denoted by "periphery" is anything but trivial or unimportant. What is in the periphery at one moment may in the next moment come to be at the centre of our attention and so be crucial. Calm Technology will move easily from the periphery of our attention, to the centre, and back. This is fundamentally "encalming", for two reasons [82]:
- By placing things in the periphery we are able to attune to many more things than we could if everything had to be at the centre.
Things in the periphery are registered by our skills devoted to peripheral sensory processing. The periphery informs without causing an overload;
- By recentering something formerly in the periphery we take control of it.
Peripherally we may become aware that something is not quite right. By moving from the periphery to centre we are empowered to act.A technology can not only empower our periphery by making it easy to move from the centre of attention to the periphery and back, but also by having it enhance our so-called "peripheral reach" by bringing more details into the periphery. "An example is a video conference that, by comparison to a telephone conference, enables us to attune to nuances of body posture and facial expression that would otherwise be inaccessible. This is encalming when the enhanced peripheral reach increases our knowledge and so our ability to act without increasing information overload." [83]
The concept of Calm Technology can be summarised as becoming attuned to more by attending to it less. Augmented Reality tries to reach a similar goal (enabling a user to do more work with less effort) but quite different techniques are used.
Augmented Reality (AR)
The concept of "(Computer) Augmented Reality" is very similar to Ubiquitous Computing and Calm Technology, but it will most likely be introduced last into the online marketplace. It is strongly focused on interfacing with, and the visualisation of, information.
The environment around us provides a wealth of information that is difficult to duplicate in a computer. The aim of Augmented Reality is to circumvent these difficulties by enhancing the capabilities of the human visual system through the combination of computer-generated graphics, computer vision and advanced user interaction technology (by projecting information on physical objects). Information stored in a database or potentially derived from a computer vision system in this way can be used to provide the human viewer with additional knowledge about the scene that would not be otherwise apparent.
Although the main application areas will most likely lie in construction, design and manufacturing, there are a number of sensible applicatio ns in the context of the information processing. One example is the DigitalDesk:
"[The DigitalDesk] has three important characteristics: it projects electronic images onto the desk and onto paper documents, it responds to interaction with pens and with bare fingers, and it can read paper documents placed on the desk. The main aim of the DigitalDesk project is to make the desk more like the workstation instead of making the workstation more like the desk.Unlike Ubiquitous Computing which scatters electronic devices throughout our reality, Augmented Reality provides a computer augmented environment giving electronic capabilities to objects, and in this case, to paper." [84]
Augmented environments offer a merging of computers and common physical objects. By using projection and overlay techniques, an artificial layer is laid over the real world. The user has to permeate this digital envelope to interact with real world objects. Just like Virtual Reality (VR), a concept very similar to Augmented Reality, this can be intimidating for the user. The main difference between AR and VR, however, is the immersiveness of the system.
It is tempting to conclude that Virtual Reality is an almost total embodiment of the main aims of Ubiquitous Computing, as the computer 'virtually' disappears in such an environment. However, Virtual Reality is rather the opposite of UC.
"The basic flaw with Virtual Reality as a means of allowing the user to leave the workstation is [that] VR leaves the physical world behind by creating a simulated world inside the computer. It cuts the user off from the world in which they normally exist, introducing them to an artificial world which is much simpler than the real world; it has lower resolution, leaves out details, and is limited in behaviour and extent. This is at odds with the goal of better integrating the computer into human activities. [...] Ubiquitous Computing is based on enhancing reality. VR does not deal with this because the user leaves the real world to be surrounded by the computer. As well as this separation from reality, the other major drawback with VR is the encumbering equipment. It is fundamental that people will resist any technology that is physically uncomfortable." [85]The ultimate goal of Augmented Reality is to create a system such that the user can not tell the difference between the real world and the virtual augmentation of it. To the user of this ultimate system it would appear that he is looking at a single real scene. An important prerequisite to reach this goal is that the natural qualities of objects are preserved while augmenting its capabilities.
Summary
Ubiquitous Computing, Calm Technology and Augmented Reality each have their own merits. When combined together they can help realise "the empowerment of the user during human-computer interaction, as well as the embodiment of a sense of control" [86]. 'Feeling in control' is a key concept in the context of the oncoming information society. Information seekers should be able to get the information they need in a convenient way without feeling intimidated by the amount of information available or by technology.
Ubiquitous Computing and Calm Technology can help reach this goal by "alleviating techno-fear through careful consideration on the part that technology takes in the user's life" [87].
Tomorrow's Internet: an Ubiquitous and Agent-serviced Online Marketplace...?
We've discussed software agents, agent-like applications, a concept called "agency" and Information Brokering so far in this paper. In addition, we've brought to your attention Ubiquitous Computing (UC), Calm Technology (CT) and Augmented Reality (AR). In this section we'll look at how all these concepts may work together and explain why they are likely to play an increasingly important role in the future.
Currently, those who are technically minded are able to satisfy their information needs. But not all are sufficiently skilled to work on the Internet and similar online environments. The numbers of those with a lack of technical skills may grow in the future. Yet, there should be a way for them to take advantage of digital information and services.
New tools and techniques are needed that focus directly on information seeking tasks. As has been partially shown, UC, CT, AR and software agents are a move in the right direction. With the current surge of object-oriented, mobile and distributed applications, it is time to start looking for a solution in a whole new direction. Effort should not concentrate on one monolithic entity, but a group of tools and techniques integrated into the everyday environment. Ordinary objects and tools, for example, could extend with a certain amount of "agency". The agency of each individual tool - which could be anything from a desk, a computer to a book - will be rather minimal, but all these entities together form an environment where users can interact in a very natural way.
Agents and agent-like entities, as well as the cluster of UC, CT and AR, will each serve their own purpose in this respect. It may be expected that UC, CT and AR will be mostly used in the real world, by those that are not comfortable working with computers and similar tools. Agents and agent-like applications will most likely be used in the virtual world by those that are more comfortable with computers and applications. It is important to point out that these new tools will not just enable anyone to access services and information they need. They will also permit anyone to secure information and services that are the most appropriate at a certain time and location for a specific individual.
The Online Marketplace Meets the Real World
We will now examine how various tools and techniques already discussed can help individuals connect to and work on the online marketplace in a personalised and effective way. Very roughly speaking, these tools will allow our work to "disappear" into our environment; the online marketplace will become an information utility.
"The Internet is already the biggest machine ever constructed by humans. As common as indoor plumbing, as cheap as running water, and as pervasive as TV - this conjures up the idea of Internet-as-utility. This is not a new idea. (Indeed, the bridge to the 21st century is actually a Cisco router!) What might be new is the adoption of the Internet-as-utility metaphor to replace the desktop metaphor we currently use.This idea of integrating the Internet and similar networks into our daily environment has been the topic of numerous papers on "Intelligent Environments", "Smart Houses", and so on; some - like Marc Weiser - have taken this idea to the point where they envision a world where your refrigerator would provide you with a shopping list when you're short of milk! These imaginary environments, where computation is seamlessly integrated to enhance ordinary activity, take on tasks which have been historically outside the normal range of human-computer interaction. Applications in these environments are not spreadsheets or word processors but intelligent rooms and personal assistants.If this metaphor works out, we have to make the Internet so pervasive that it becomes invisible, essential, and totally integrated into society." [88]
"Interaction with these environments should be in terms of forms that people are naturally comfortable with. Their user-interface primitives are not menus, mice and windows but gesture, speech, context, and affect. At least in theory, it should be possible for a person to forget she is using a computer while interacting with one.Building Intelligent Environments requires a unique breadth of knowledge thatextends beyond any of the traditional boundaries of AI research areas." [89]
As "intelligence" is distributed over large numbers of objects and appliances, the problem of having one central intelligent entity to control them all - something AI has not been able to accomplish yet - becomes a non sequitur. Every individual entity only needs sufficent "intelligence" to perform its very specified task. "The real power of [this] concept comes not from any one of these devices; it emerges from the interaction of all of them. The hundreds of [devices] are not a 'user interface' like a mouse and windows, just a pleasant and effective "place" to get things done." [90]
The technology needed to embed "the computer" into our environment and to give all kinds of devices "smartness" is available today. Already there are commercial products available that can offer such functionality. There are a number of platforms and languages specifically tailored to embedded applications. Unfortunately the developers of these applications and techniques have not created general standards. Without standards, connectivity and compatibility loom as very large issues. There are also a number of other challenges such as the transparent linking of wired and wireless devices and security and privacy
Fortunately,there are a number of solutions ready to tackle this problem such as cryptographic techniques. Jim Morris of Carnegie-Mellon University has proposed an appealing general method for approaching these issues: build systems and applications to have the same privacy safeguards as the real world, but no more, so that ethical conventions will apply regardless of setting. In the physical world, for example, burglars can break through a locked door, but they leave evidence in doing so. Computers and applications built according to Morris's rule would not attempt to be utterly proof against crackers, but it would be impossible to enter without leaving the digital equivalent of fingerprints.
Ubiquitous Computing, Calm Technology and similar techniques will appeal to many. Many have been "playing around" in the online world for quite a while but this "play-time" has lost its appeal. UC and other techniques can help shift the focus from the "how" to the "what".
Intelligent Software Agents meet The World
Where techniques and concepts as Ubiquitous Computing have a strong potential for usage in the real world, software agents have most potential in the virtual world. In this world, they will relieve us from mundane tasks in the short term and may assist us in smart - and possibly truly 'intelligent' - ways in the long term. They will perform those tasks that are best done by computers (those that are laborious or boring).
Apart from technical considerations, there are other issues that arise when we massively start to work with agents and agent-like applications. There is the social side of employing agents and 'agency'. Agents will interact and collaborate with not only other agents but also with humans. This will make them part of our environment, and therefore subject (to some extent) to our social rules. Agents will become embedded in our lives, as a result of which agents will have to follow social rules.
"Work in artificial intelligence has never really addressed the problems of binding together its agents in human societies to the same degree as has the field of human-computer interaction. In AI agents are designed to form unrealistic social systems, or, rather, they take valid models of realistic social systems and interpret the models too literally and too strictly. The human components of conflict, morality, and responsibility, for instance, are all simplified out of existence and, therefore, agents have real problems in human societies, except in small niche contexts where people can accept these limitations. The result is that agents are not usually flexible enough to be able to work effectively in human societies." [91]
This means that with regard to agents and agency, there are not only technical issues that will need to be addressed but social ones. Technology will not be the most important key to success: people will judge an agent not by its programming code but by the actions it initiates and performs, by its behaviour.
Communication is another important part of social behaviour. How should agents communicate? How should they 'interface' with each other and with humans? In the eye of efficiency, agent-agent communication should best occur by a knowledge representation language like KQML or KIF, but these are languages that are very hard to understand for most humans. In agent-human interaction, the most preferred language would be natural language. Technically - for both the agents, as well as their developers - this is not easy: parsing natural language is a problem that has been studied for many years and it is not clear if it will ever be possible to make a computer fully understand natural language [92].
Note that the communication issue is not only about communication through natural language: spoken or written language is just one component of the entire communication process. Non-verbal communication is also very important. Agents could address this issue partially by using techniques such as anthropomorphic interfaces. However, enabling agents to interpret and understand non-verbal communication will be yet another huge challenge to agent designers.
These aspects are important because many that will use agents for the first time will assume that the interface is a natural and logical extension of human communication and social systems.
"This very kinship opens up an immense possibility for conflict when there is a dissonance between these expectations and reality - when the expectations from human-human collaboration conflict with the reality of human-computer interaction." [93]Sounds far fetched? Look at how people use computers and applications, and how they unconsciously attribute all kinds of human qualities and skills to computers. Humans do this naturally; for agents and agency to be accepted, they must be able to display similar behaviour and be able to reason and communicate in a similar fashion. Developing such behaviour is not something which may be expected to emerge in the next few years. In the short- and medium-term, agents will therefore possess behaviour that will be more mechanical and less human than would be hoped. Agents will be perceived as smart programs rather than smart assistants [94].
Software Agents & UC/CT: Different Focus, Different Users
Software agents and UC/CT have very different ways of working. Ubiquitous Computing and Calm Technology are meant to make the computer and all of its functionality disappear into our surroundings. Any person should be as unaware as possible of the fact that they are using a computer to get a certain task done. With Ubiquitous Computing and Calm Technology, there is not really a single unit with which to interface. Rather, there are many distributed interfaces (devices) which people use, and these devices - usually - adapt themselves to the person using them, as well as the circumstances in which they are used. Those not familiar with computers and with the services will feel comfortable working in this way. Yet, as "user-friendly" as Ubiquitous Computing may be, they require a whole new way of looking at computers, appliances, and online services that not all will be able to adopt instantaneously.
Agents, on the other hand, operate in the virtual world, and they are an explicit part of the working environment. Ideally, there will be a single interface for every individual person to interact and communicate with. There will be a greater awareness of the existence of agents. Agents will have a much harder time detecting the context of a user's implicit requests and wishes compared to ubiquitous devices (as these devices are usually employed in a context that is more or less the same every time it is used: the application of the device is the context [ 95]). Those familiar with computers and with their services will probably feel more comfortable working with an agent, as this resembles very much the way of working that they are used to (actively stating requests). They probably will not mind if they have to learn some additional techniques to use agents to their full potential. Using agents is a quite natural extension of how people currently work with computers and their software: they do not require a radical change in human working methods.
Does this mean that the application areas of both concepts are worlds apart? In some areas one will be the more prominent than the other; for example a ubiquitous device might use agents to fulfil its task but the user will probably not be aware of this fact. In many ways these techniques will complement each other; Ubiquitous Computing, Calm Technology and augmented realities will be used to bridge the gap between the user and the computer. Agents will be used to bridge the gap between the computer and specific applications, such as online services, and performing other kinds of tasks.
A good - albeit technically very modest - example of how agent-like functionality can be combined with Calm Technology-like functionality, is the Remembrance Agent which will be discussed in the next section.
An Unobtrusive Agent Application: The Remembrance Agent
Most of the current information retrieval applications concentrate on query-based searches. However, they are not useful if you do not remember sufficient details about a problem to formulate a question.
The Remembrance Agent [96] performs this continuous, associative form of recall by continuously displaying relevant information which might be useful to an individual user. However, it does not just display information, as this might be distractful and not be of much help at all! The philosophy behind the Remembrance Agent (RA) is that it should never distract from the user's tasks; it should augment them. RA accomplishes its work by suggesting information sources (deemed possibly relevant to a user's current situation) in the form of one-line summaries at the bottom of the screen or current active window. In this location, they can be easily monitored without distracting from the user's primary activity. The full text of a suggestion can be brought up with a single keystroke. Effectively, the agent thus becomes an augmentation to an individual's memory. It is important to note that - unlike most information retrieval systems - the RA runs continuously without user intervention.
How is this agent constructed?
The agent consists of two parts: a front end and a back end. The front end continuously watches what the user types and reads, and sends this information to the back end. The back end then finds archived e-mail messages, personal documents, and online documents which are relevant and in context. This information is then displayed by the front end in a way which does not distract the user. In the case of a text editor, this would lead to the information being displayed in one-line suggestions at the bottom of the editing window, along with a numeric rating indicating the relevance of the displayed document. With a simple key combination, the user can bring up the full text of a suggested document.
The power of the RA can be found in the brief details displayed - just enough for the user to get an idea of the full document being suggested but not too verbose to be obtrusive. Also, the frequency with which the front end provides new suggestions, as well as the number of suggestions, is kept low so as not to be distracting.
Currently, to find similar and relevant documents, the SMART information retrieval program is used as a back end. While SMART is not the most sophisticated system, it was chosen as it has the advantage that it requires no human pre-processing of the documents being indexed and searched.
When looking for relevant documents, the agent does not have very much information (or context) for its searches. As a result, many of the suggestions of the RA may not be that useful. However, as there are almost no "costs" to the user to see a suggestion and ignore it if deemed not useful at the time, this is not as big a problem as one might at first think. The fact that no colour cues or highlights are used when displaying suggestions, and the fact that suggestions are displayed at regular intervals, contribute to the low "costs" of scanning them. It is also important for the success of the RA that it is trivial to both access the entire suggested document and to return to the primary activity once it has been viewed.
While using the system, it became clear that suggestions are much more useful when the document being suggested only contains one "nugget" of information and when this nugget is clearly displayed on its one-line suggestion.
Using personal e-mail and locally accessible documents turned out to work well for other reasons. These files are pre-personalised to each individual user and they will automatically change as the user's interest changes. It turned out that this compensated very well for other RA shortcomings.
In future applications of the RA, it is planned to provide the back end with an algorithm which learns based on which suggestions the user actually uses. In this way, the RA can display more documents that are actually helpful and cull out those which seem to be unnecessary.
Concluding Remarks
As the Internet - or more generally: the online marketplace - keeps on growing , it is becoming clear that "things must change". Web surfing, querying search engines, and similar tools and solutions worked fine on the Internet up to 12 months ago. It is time for new concepts, new ways of getting our work done, as the old ones do not seem to be up to par anymore.
Push Technology has been one of the most recent attempts to solve these problems. As useful as it has been to some users, it has not brought much relieve for the majority. However, Push has demonstrated that most would gladly delegate the process of finding content that fits their personal information needs to others. Information Brokering - possibly combined with the employment of agency and agent-like applications - looks very promising, and has much potential to help us get our online work done.
In the future, we will not only use new methods of searching for information in the online marketplace, but that we will also develop new ways of using computers in general. Instead of thinking of a computer as something you have to physcially interact with, you will not have to think of it much at all. Computers and smart devices will be where you need them, in a form most suitable for the task at hand; they will work for even the most novice user.
Right now, many of these new ways of using, interfacing and working with computers and software may seem unusual. Information brokering, software agents and Calm Technology will not force us to learn something completely new, but rather will do the opposite - they will ask computers and applications to learn from us. They should enable us to regain a sense of control and help them cope with information overload and techno-stress.
"Technical innovation - the devising of new tools - is surely a desirable activity. But unless there is a balance between our fascination with tools and our concern for the ends they may help us achieve, the tool becomes tyrannical. What stares us in the face today is the startling fact that, not only has the balance been upset, but one of its terms has virtually disappeared.Technological innovation now proceeds for its own sake, driven by its own logic, without reference to human need. We are a society obsessed with new tools, but incapable of asking in any serious way, "what are we developing these tools for?"
It's rather as if a musician became so enamored of new instruments capable of generating novel sounds that he lost all interest in seeking the kind of disciplined musical inspiration that makes his art finally worthwhile.
[...] Our pressing need is not for more information, or faster access to information, or more connectivity. Our decisive problems arise - as many others have noted - from the lack of meaningful, value-centered contexts to which new information can be assimilated, and from those connections to other people we already have, but do not know how to deepen and make healthy. Adding new information and additional connections where these fundamental problems have not been solved only carries us further from ourselves and each other." [97]
To create an ideal online marketplace further research will have to be done in a number of areas, including: Future Research
- Tools which can help information supplying parties in the online marketplace deal with large numbers of Broker queries.
In order to satisfy a query, Brokers will send it to a number of sources or suppliers which seem most fit to answer it. Suppliers in turn will have to be able to provide an answer that is both concise as well as timely; brokers probably will only wait for a certain amount of time for sources to provide an answer. Human intervention will need software - possibly software agents - to assist in this activity.
- Expectations of software agents and search engines.
The technical aspects of search engines and software agents has been given a lot of time and thought. Only recently has another important aspect - expectations of users - been given some attention; the technical soundness of an application, and the process of using it, are two matters that are no longer seen as separate and unrelated in this field of research [98].
Acknowledgements
The author wishes to thank Steef Geenen, Hein Ragas and Milé Buurmeier for feedback and valuable comments on draft versions of this paper. He also wishes to thank Cap Gemini for all the time that has been kindly provided by the company to work on this paper.
He would also like to thank all contributors to the Software Agents Mailing List, as well as Steve Talbott (editor of the Netfuture newsletter), for providing inspiration as well as providing many pointers to useful information on the Internet.
It should be noted that this paper does not express the views of Cap Gemini but the personal perspectives of the author.
About the Author
Bjorn Hermans is currently working at Cap Gemini in the Netherlands where he is working in the fields of Internet/intranet, Information Filtering and Information Push/Pull.
Since he started working on his academic thesis on intelligent software agents on the Internet, the author has become strongly interested in the subject of software agents and related topics. Other areas of interest include information retrieval, information filtering, artificial intelligence, user interfaces and the Internet and World Wide Web in general (with particular interest for the human or "user" aspects of these media).
E-mail: hermans@hermans.org
Notes
1. From Dick Rijken, 1994. "The Future is a Direction, Not a Place." Netherlands Design Institute, Sandberg Institute, the Netherlands.
2. Using this concept seemed the most practical choice, as it avoids having to update this paper (i.e. extending the list of "**net" terms) whenever a new term or buzzword for some kind of 'Net'-concept is introduced in the media. Also note that the online marketplace is not 'limited' to information; it is about online services as well. And the stress in "marketplace" is on the aspect of a place where people meet for all kinds of activities; it is not necessary a commercial or financial marketplace.
3. In this paper the term "Internet" is used to also cover such concepts as "intranets", "extranets", and so on. Unless explicitly stated to be otherwise, whatever is said about the Internet, is valid for all those other concepts as well.
4. Figures taken from the Spring 1997 study of Internet Demographics and Electronic Commerce, as conducted by CommerceNet/Nielsen Media Research.
5. Usually, search engines are used to search for information on the Web, which is why in this section we will be talking about "documents". Yet, most search engines can be used to search for other items as well, such as files or Usenet articles. To keep things simple, we will continue to talk about (Web) documents, but what is said is in most cases just as valid for those other types of information.
6. The documents being scanned do not have to be interpreted or comprehended: merely applying the mentioned heuristics is all that needs to be done.
7. Marti A. Hearst, 1997. "Interfaces for Searching the Web," Scientific American, at http://www.sciam.com/0397i ssue/0397hearst.html
8. See Clifford Lynch, 1997. "Searching the Internet," Scientific American, at http://www.sciam.com/0397is sue/0397lynch.html
9. E.g. send a pager message when someone is currently not online, or send only the URL of a document to a user's e-mail box since the user is currently using a low bandwidth connection to the Internet (so sending the complete document would consume too much time and resources).
10. Of course it is easy to turn this 'advantage' into a disadvantage: large publishers can use Push to get their content to users who probably wouldn't normally have visited their Web site.
11. "Half a Billion Dollars Worth of Push?" at http://webreview.com/97/0 4/04/trends/index.html
12. Lou Rosenfeld, 1997. Look Before You Push: Consider the User Before Taking the Plunge," at http://www.webreview.co m/97/04/18/arch/index.html
13. John Graham-Cumming, 1997. ""Hits and Misses: A Year Watching the Web," summarized at http://www.internet-sales .com/hot/oldsize2.html
14. For more information on software agents, see Björn Hermans, 1997, "Intelligent Software Agents on the Internet," First Monday, volume 2, number 3 (March), at http://www.fi rstmonday.dk/issues/issue2_3/ch_123/index.html
15. The stress is on "like" since they do not posses vital agent characteristics, e.g. the packages do not seem to learn from user input (such as which retrieved documents are looked at first), they show little or no proactivity, and they usually are not autonomous (i.e. the user has to activate them manually).
16. Stephen W. Plain, 1997. "KQML at Your Service," Computer Shopper, http://www5.zdn et.com/cshopper/content/9703/cshp0046.html
17. In the rest of this chapter the term "agents" will be used whereas, when looking at the current state of the technique, "agent-like" would be more appropriate. As it would be rather tedious to point out this aspect over and over again, we will refrain to the former term. In later chapters, a much closer look will be taken at 'real' agents andagent applications.
18. Christine Guilfoyle, Judith Jeffcoate and Heather Stark, 1997. "Agents on the Web: Catalyst for E-Commerce," at http://www.ovum.com/
19. For instance, when they see that a user repeatedly performs a series of actions which could very well be done with a macro command, the agent will point this out to the user and will assist him - if needed - with the creation of the macro.
20. To answer user questions in the best possible way and assist them in using this suite, these agents rely on usage patterns as Microsoft has acquired them during in-house user test sessions. These tests were used to collect large amounts of statistical data about the way people usually use the software, and about the most common errors and problems (e.g. which topics are looked up the most in the suite's help files). When answering questions, agents uses these data to fine-tune the way in which they answer the question. There is a drawback to this approach for a certain group of users: those which use the suite in a way that strongly deviates from the way average users used in the user tests (e.g. expert or power users). They will find the agents assistance to be a nuisance (e.g. the agents gives them hints they already know) and "patronising".
21. Paul Saffo, 1995. "Networking Forum: December 5," an interview for the IBM Networking Forum, quote at http://www.duke.edu/~mccann/q-tech .htm
22. "Another Web Aggregator Bites the Dust; Shuts PPV Service," Media Daily, volume 5, number 177 (November 3, 1997), at http://www.mediacentral.com/Magazines/md/OldArchives/199711/1997110303.html
23. Lynch, 1997, op. cit.
24. Hermans, 1997, op. cit.
25. Information taken from a study of the importance of top search engine listings to generate website traffic, as conducted by NetGambit; quoted at http://www-agency.com/dmAug97.htm < p> 26. Gerry McGovern, 1997. http://w ww.nua.ie/newthinking/archives/newthinking222/index.html
27. Hermans, 1997, op. cit.
28. In the remaining part of this section, instead of continuously using both the term "intermediary" as well as "information broker", the term "information broker" will be used to denote both parties.
29. Even if it were possible to maintain a large information base, a lot of time and energy would be wasted checking sites which have not (or only little) changed since they were last visited. A supplier is best suited for this sort of work.
30. If no direct matches can be found for a query on the basis of available advertisements, specialised services (such as a thesaurus service) can be employed to secure related terms and/or possible contexts. Another possible way to solve this problem is to contact the user (or agent) and direct a request for more related terms or a more specific context.
31. Mark Weiser, 1991. "The Computer for the 21st Century," at http://lki-www.informatik.uni-hamburg.de/~buhr/ubicomp/ubi/SciAmDraft3.html
32. There will probably still be some checking on the intermediary side on the contents of such descriptions, to prevent sources from supplying misleading descriptions for their services. In some cases, a description may mention popular search terms which are not related to a given specific source; this trick means that it will be selected in many queries. As brokers are concerned with meta-information only, it should be very feasible to permit humansto do this part of the scanning process, as they can easily see around simpleminded tricks.
33. Lynch, 1997, op. cit.
34. The costs of issuing queries are not yet an issue on the current Internet with a great deal of free content. In the future it may be expected that micro-amounts of funds will be required for activities such as sending queries and consuming bandwidth.
35. Quote taken from "A Survey of Electronic Commerce" in The Economist at http://www.economist.com/4GzU4Qft/editorial/freeforall/14-9-97/ec3.html
36. Tim Clar, 1996. "You Say, 'D-i-s-i-n-t-e-r-m-e-d-i-a-t-i-o-n'; I Say Don't Count On It," Inter@ctive Week (April 8), at http://www.zdnet. com/intweek/print/960408/web/col2.html
37. J. Xu and J. Callan in their paper, " Effective Retrieval with Distributed Collections" (Proceedings of SIGIR 98, pp. 112-120), evaluate the retrieval effectiveness of distributed information retrieval systems in realistic environments. They outline a way in which current search engines could tackle their update problem, by switching from one, central database of sites to a distributed collection.
38. Or they can use a mechanism like superdistribution to gain extra revenue and reduce costs.
39. For a more in-depth discussion of this topic, see J. Foss, 1998. "Intermediation and Information Brokerage," presented at ISSLS'98 (International Symposium for Services and Local accesS), Venice, Italy, March 26.
40. P. Resnick, R. Zeckhauser and C. Avery, 1995. "Roles for Electronic Brokers," at http://ccs.mit.edu/CCSWP179.html
41. Stephen W. Plain, 1997. "KQML at Your Service," Computer Shopper (March), at http://www5.zdn et.com/cshopper/content/9703/cshp0046.html
42. A candidate language, specifically developed for this task, could be KQML. However, this language has yet to make it into any major commercial product. Implementations have primarily been restricted to technology demonstrations in proprietary configurations. See Plain, 1997, op. cit. for more detailed information about KQML.
43. H. Lieberman and D. Maulsby, 1996. "Instructible agents: Software that just keeps getting better," IBM Systems Journal, volume 35, numbers 3 &4, at http://www.almaden.ibm.com/journal/sj/mit/sectiond/lieberman.html
44. For more detailed information about these, and other important agent characteristics, see Hermans, 1997, op. cit.
45. Pattie Maes, 1997. "Pattie Maes on Software Agents: Humanizing the Global Computer," IEEE Internet Computing (July/August), volume 1, number 4, at http://computer.org/internet/ic1997/w4010abs.htm
46. Maes, 1997, op. cit.
47. The way in which they cooperate is similar to that of an ant colony; each ant has a very specific task which all by itself is of little value. Yet, when all the efforts of each individual ant is combined, an entity arises which seems capable of solving all kinds of problems and able to perform a variety of tasks (displaying "intelligent" behaviour).
48. Charles J. Petrie, 1997. "What's an Agent... And what's so Intelligent about it?" IEEE Internet Computing (July/August), volume 1, number 4, at http://gummo.stanford.edu/people/petrie/online/v1i4-webword.html
49. Java and mobile agents are related but the current implementation of Java is not fully capable of providing the technical basis to create real mobile agents.
50. One of Sun's latest Java innovations, Java Beans, takes this idea to the next stage: with Beans not only can the program run on virtually any machine, but the parts that make up the program (the modules or classes) can be anywhere on the network and can be called upon when necessary.
51. A "search engine" an agent may be expected to also query an information broker or similar service.
52. Quote taken from an article in JavaWorld.
53. D. Chess, C. Harrison, and A. Kershenbaum, 1997. "Mobile Agents: Are they a Good Idea?" In: Jan Vitek and Christian Tschudin (editors), Mobile Object Systems: Towards the Programmable Internet. Lecture Notes in Computer Science, volume 1222. N. Y.: Springer-Verlag, and at http://www.research.ibm.com/ massive/mobag.ps
54. S. Green, L. Hurst, B. Nangle, P. Cunningham, F. Somers, and R. Evans, 1997. "Software Agents: A Review," Trinity College Dublin and Broadcom Éireann Research Ltd. (May 27), at http://www.cs .tcd.ie/research_groups/aig/iag/toplevel2.html
55. Processing visual information is a more natural activity than reading text; we can't process text at the blink of an eye. For instance, compare the speed with which the information in a pie chart can be read with the time needed to get that same information from a table or list. Additionally, the human brain has a much wider array of senses and skills to process visual information.
56. When browsing a Web site, links are followed to find information. If a hyperlink moves to a different Web server, you usually will have lost sense of your original context. This situation is caused by the fact that much of the current information on the Web is embedded in pages. Usually, the only means of getting an overview of your path of context is the "back" button. By using three dimensional techniques, a tree or a 3-D Hyperbolic Tree (an invention of InXight), would you be able to preserve context.
57. Hearst, 1997, op. cit.
58. Hearst, 1997, op. cit.
59. Kevin Kelly and Gary Wolf, 1997. "Push! Kiss your browser goodbye: The radical future of media beyond the Web," Wired, volume 5, number 3 (March), cover and pp. 12-23, and at http://www.wired.co m/wired/5.03/features/ff_push.html
60. R. V. Guha, "Meta Content Framework: A Whitepaper," at http://www.xspace.net/hotsauce/wp. html
61. MCF allows for semantically rich descriptions of content and its relationship to objects such as people, organisations and events.
62. MCF descriptions are standardised at two levels. MCF provides a standard language for accessing and manipulating meta content descriptions just like SQL provides a standard query language for relational databases. In addition, MCF also provides a standardised vocabulary so that different sources/programs use the same terms (such as "author", "fileSize", etc.) to refer to the same concepts.
63. The distinction between structured and unstructured descriptions is the same as the distinction between a relational database and a text file. Structured descriptions take more work in creating, but support sophisticated queries and analysis.
64. In addition to the standard terms, programs can introduce new terms to express new kinds of meta content. This extension can happen dynamically and apply to older objects as well.
65. It is possible to have multiple layers of descriptions, each adding to or modifying lower layers.
66. Guha, op. cit.
67. Note that no assumptions are made about the encoding of the content itself. The actual files, email messages, etc. can be in HTML, Word or any other content encoding; the focus is on the meta content.
68. Guha, op. cit.
69. There are some important points to note about these descriptions. Firstly, they capture not just format information (field A1 is an integer) but the semantics of the table ("field A1 has the social security number of the person whose address is in field A2"). Secondly, the descriptions have to be provided only once per table and not once per query, thus they have to be changed only when the schema of the table changes. Thirdly, the MCF descriptions of different tables can be generated independently, without any central coordination. The central coordination is provided in effect by the use of a common vocabulary.
70. For further information on Babelfish, see Guha, op. cit.
71. Where "cannot" can mean "not at all" and also "not until you have paid a certain amount of money via a payment mechanism that is part of the container".
72. Ryoichi Mori and Masaji Kawahara, 1990. "Superdistribution: The Concept and the Architecture," Transactions of the IEICE, volume E73, number 7 (July), and at http://www.virtualschool.edu/mon/ElectronicProperty/MoriSuperdist.html
73. Frank Casanova, formerly Director of Apple Computer Inc.'s Advanced Prototyping Lab and Director of Apple's Advanced Systems Group, now Vice President of Product Management and Design for MetaCreations.
74. Rijken, 1994, op. cit.
75. Marc Weiser, 1996, at http://www .itp.tsoa.nyu.edu/~review/current/focus2/open00.html
76. Weiser, 1991, op. cit.
77. A list of research projects related to mobility, active networks, and similar concepts, can be found at http://www.tns.lcs.mit.edu/~le hman/active/.
78. An interesting article on power for low power devices is "Los Alamos Physicist Creates New Energy Source for Cellular Phones, Other Portable Electronics," TechMall.
79. A tutorial on Mobile IP, as well as numerous links to sites on this subject, can be found at http://www.computer.org /internet/v2n1/perkins.htm.
80. Marc Weiser and John Seely Brown, 1995. "Designing Calm Technology," http://www.ubi q.com/hypertext/weiser/calmtech/calmtech.htm
81. Weiser, 1991, op. cit.
82. This information is largely quoted from Weiser and Brown, 1995, op. cit.
83. Weiser and Brown, 1995, op. cit.
84. Bronagh McMullen, http://helix.infm.uls t.ac.uk:80/~mcmullan/ecom.html
85. McMullen, op. cit.
86. McMullen, op. cit.
87. McMullen, op. cit.
88. Ted Lewis, 1997. "Internet as Metaphor," IEEE Internet Computing, volume 1, number 2 (March/April), p. 94.
89. Quote taken from the Software Agents Mailing List
90. Weiser, 1991, op. cit.
91. Stuart Watt, 1996. "Artificial societies and psychological agents," KMI-TR-33 (September), Knowledge Media Institute and Department of Psychology, Open University, Walton Hall, Milton Keynes.
92. On the Software Agents Mailing List, an intriguing future was envisioned, where agents (or rather software-based artificial life forms) had been created that used a communication language which was optimal for agents to communicate, but totally incomprehensible for most humans. Soon, the agents were able to communicate and exchange messages and knowledge at such a high rate, that they were living in a world of their own. In this scenario, the agents find it very hard to find a reason to communicate with humans, as the agents find our natural language too inexpressive and clumsy to communicate.
93. Watt, 1996, op. cit.
94. Note that this view on agents is different from that of AI in general, in a sense that the aim is not to build progressively more complex agents, but to build progressively more human agents.
95. The context is important when an agent gets ambiguous, incomplete, and possibly conflicting messages or tasks from a user; the context of such request can be of great aid to find out what a user means.
96. B. J. Rhodes and T. Starner, 1996. "Remembrance Agent, a continuously running automated information retrieval system," at http://rhodes.www.media.mit.edu/~rhodes/Papers/remembrance.html
97. Steve Talbott, (editor). Netfuture, at http://www.ora.com/peop le/staff/stevet/netfuture/
98. See proceedings of the workshop "Query Input and User Expectations," held in conjunction with the 21st Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, 28 August 1998.


Copyright © 1998, ƒ ¡ ® s † - m ¤ ñ d @ ¥