by Björn Hermans 
"Agents are here to stay, not least because of their diversity, their wide range of applicability and the broad spectrum of companies investing in them. As we move further and further into the information age, any information-based organization which does not invest in agent technology may be committing commercial hara-kiri." - Hyacinth S. Nwana
Table of Contents | Next Chapters
Chapter 1: Preamble
Chapter 2: Intelligent Software Agents Theory
Chapter 3: Intelligent Software Agents in Practice
Bibliography
Notes
Software agents are a rapidly developing area of research. However, to many it is unclear what agents are and what they can (and maybe cannot) do. In the first part, this thesis will provide an overview of these, and many other agent-related theoretical and practical aspects. Besides that, a model is presented which will enhance and extend agents' abilities, but will also improve the way the Internet can be used to obtain or offer information and services on it. The second part is all about trends and developments. On the basis of past and present developments of the most important, relevant and involved parties and factors, future trends and developments are extrapolated and predicted.Introduction
We are drowning in information but starved of knowledge" - John NaisbittBig changes are taking place in the area of information supply and demand. The first big change, which took place quite a while ago, is related to the form information is available in. In the past, paper was the most frequently used media for information, and it still is very popular right now. However, more and more information is available through electronic media.
Other aspects of information that have changed rapidly in the last few years are the amount that it is available in, the number of sources and the ease with which it can be obtained. Expectations are that these developments will carry on into the future.
A third important change is related to the supply and demand of information. Until recently the market for information was driven by supply, and it was fueled by a relatively small group of suppliers that were easily identifiable. At this moment this situation is changing into a market of a very large scale where it is becoming increasingly difficult to get a clear picture of all the suppliers.
All these changes have an enormous impact on the information market. One of the most important changes is the shift from it being supply-driven to it becoming demand-driven. The number of suppliers has become so high (and this number will get even higher in the future) that the question
who is supplying the information has become less important:demand for information is becoming the most important aspect of the information chain.What's more, information is playing an increasingly important role in our lives, as we are moving towards an information society [ 1 ]. Information has become an instrument, a tool that can be used to solve many problems.
Problems regarding the demand for information
Meeting information demand has become easier on one hand, but has also become more complicated and difficult on the other. Because of the emergence of information sources such as the world-wide computer network called the Internet (the source of information this thesis will focus on primarily) everyone - in principle - can have access to a sheer inexhaustible pool of information. Typically, one would expect that because of this satisfying information demand has become easier.The sheer endlessness of the information available through the Internet, which at first glance looks like its major strength, is at the same time one of its major weaknesses. The amounts of information that are at your disposal are too vast: information that is being sought is (probably) available somewhere, but often only parts of it can be retrieved, or sometimes nothing can be found at all. To put it more figuratively: the number of needles that can be found has increased, but so has the size of the haystack they are hidden in. The inquirers for information are being confronted with an information overkill.
The current, conventional search methods do not seem to be able to tackle these problems. These methods are based on the principle that it is known
which information is available (and which one is not) andwhere exactly it can be found. To make this possible, large information systems such as databases are supplied with (large) indexes to provide the user with this information. With the aid of such an index one can, at all times, look upwhether certain information can or cannot be found in the database, and - if available -where it can be found.On the Internet (but not just there [ 2 ]) this strategy fails completely, the reasons for this being:
-The dynamic nature of the Internet itself : there is no central supervision on the growth and development of Internet. Anybody who wants to use it and/or offer information or services on it, is free to do so. This has created a situation where it has become very hard to get a clear picture of the size of the Internet, let alone to make an estimation of the amount of information that is available on or through it;-
The dynamic nature of the information on Internet : information that cannot be found today, may become available tomorrow. And the reverse happens too: information that was available, may suddenly disappear without further notice, for instance because an Internet service has stopped its activities, or because information has been moved to a different, unknown location;
The information and information services on the Internet are very heterogeneous : information on the Internet is being offered in many different kinds of formats and in many different ways. This makes it very difficult to search for information automatically, because every information format and every type of information service requires a different approach.Possible Solutions: Search Engines and Agents
There are several ways to deal with the problems that have just been described. Most of the current solutions are of a strong ad hoc nature. By means of programs that roam the Internet (with flashy names like spider, worm or searchbot) meta-information [ 3 ] is being gathered about everything that is available on it. The gathered information, characterized by a number of keywords (references) and perhaps some supplementary information, is then put into a large database. Anyone who is searching for some kind of information on the Internet can then try to localize relevant information by giving one or more query terms (keywords) to such a search engine [ 4 ].Although search engines are a valuable service at this moment, they also have several disadvantages (which will become even more apparent in the future). A totally different solution for the problem as described in the previous section, is the use of so-called Intelligent Software Agents. An agent is (usually) a software program that supports a user with the accomplishment of some task or activity [ 5 ].
"In the future, it [agents] is going to be the only way to search the Internet, because no matter how much better the Internet may be organized, it can't keep pace with the growth in information..." - Bob Johnson, analyst at Dataquest Inc.
Using agents when looking for information has certain advantages compared to current methods, such as using a search engine:
Search Engine feature:
Improvement(s) Intelligent Software Agents can offer:
1.
An information search is done, based on one or more keywords given by a user. This presupposes that the user is capable of formulating the right set of keywords to retrieve the wanted information. Querying with the wrong, too many, or too little keywords will cause many irrelevant information ('noise') to be retrieved or will not retrieve (very) relevant information as it does not contain these exact keywords;
Agents are capable of searching information more intelligently, for instance because tools (such as a thesaurus) enable them to search on related terms as well, or even on concepts.
Agents will also use these tools to fine-tune, or even correct user queries (on the basis of a user model, or other user information);
2.
Information mapping is done by gathering (meta-)information about information and documents that are available on the Internet. This is a very time-consuming method that causes a lot of data traffic, it lacks efficiency (there are a lot of parties that use this method of gathering information, but they usually do not cooperate with others which means that they are reinventing the wheel many times), and it does not account very well for the dynamic nature of the Internet and the information that can be found on it;
Individual user agents can create their own knowledge base about available information sources on the Internet, which is updated and expanded after every search. When information (i.e. documents) have moved to another location, agents will be able to find them, and update their knowledge base accordingly. Furthermore, in the future agents will be able to communicate and cooperate with other agents (such as middle layer agents). This will enable them to perform tasks, such as information searches, quicker and more efficient, reducing network traffic. They will also be able to perform tasks (e.g. searches) directly at the source/service, leading to a further decrease of network traffic;
3.
The search for information is often limited to a few Internet services, such as the WWW. Finding information that is offered through other services (e.g. a 'Telnet-able' database), often means the user is left to his or her own devices;
Agents can relief their human user of the need to worry about "clerical details", such as the way the various Internet service have to operated. Instead, he or she will only have to worry about the question what exactly is being sought (instead of worrying about where certain information may be found or how it should be obtained). The user's agent will worry about the rest;
4.
Search engines cannot always be reached: the server that a service resides on may be 'down', or it may be too busy on the Internet to get a connection. Regular users of the service will then have to switch to some other search engine, which probably requires a different way to be operated and may offer different services;
As a user agent resides on a user's computer, it is always available to the user. An agent can perform one or more tasks day and night, sometimes even in parallel. As looking for information on the Internet is such a time-consuming activity, having an agent do this job has many advantages, one of them being that an agent does not mind doing it continuously. A further advantage of agents is that they can detect and avoid peak-hours on the Internet;
5.
Search engines are domain-independent in the way they treat gathered information and in the way they enable users to search in it [ 6 ]. Terms in gathered documents are lifted out of their context, and are stored as a mere list of individual keywords. A term like "information broker" is most likely stored as the two separate terms "information" and "broker" in the meta-information of the document that contains them. Someone searching for documents about an "information broker" will therefore also get documents where the words "information" and "broker" are used, but only as separate terms (e.g. as in "an introductory information text about stock brokers");
Software agents will be able to search information based on contexts. They will deduce this context from user information (i.e. a built-up user model) or by using other services, such as a thesaurus service. See the Sections on the "Three Layer Model" and "Agents Trends" for more detailed information about this;
6.
The information on Internet is very dynamic: quite often search engines refer to information that has moved to another, unknown location, or has disappeared. Search engines do not learn from these searches [ 7 ], and they do not adjust themselves to their users. Moreover, a user cannot receive information updates upon one or more topics, i.e. perform certain searches automatically at regular intervals.
Searching information this way, becomes a very time-consuming activity.
User agents can adjust themselves to the preferences and wishes of individual users. Ideally this will lead to agents that will more and more adjust themselves to what a user wants and wishes, and what he or she is (usually) looking for, by learning from performed tasks (i.e. searches) and the way users react to the results of them. Furthermore, agents are able to continuously scan the Internet for (newly available) information about topics a user is interested in.
Agents as building blocks for a new Internet
The Internet keeps on growing, and judging by reports in the media the Internet will keep on growing. The big threat this poses is that the Internet will get too big and too diverse for humans to comprehend, let alone to be able to work on it properly. And very soon even (conventional) software programs will not be able to get a good grip on it. More and more scientists, but also members of the business community, are saying that a new structure should be drawn up for the Internet which will make it more easily and conveniently to use, and which will make it possible to abstract from the various techniques that are hidden under its surface. A kind of abstraction comparable to the way in which higher programming languages relieve programmers of the need to deal with the low-level hardware of a computer (such as registers and devices).Because the thinking process with regard to these developments has started only recently, there is no clear sight yet on a generally accepted standard. However, an idea is emerging that looks very promising: a three layer structure [ 8 ]. There are quite a number of parties which, although sometimes implicitly, are studying and working on this concept. The main idea of this three layer model is to divide the structure of the Internet into three layers [ 9 ] or concepts:
1. Users; 2. Suppliers; and 3. Intermediaries.
The function and added-value of the added middle layer, and the role(s) agents play in this matter, are explained in Section on the "Three Layer Model."
Two Statements
This paper consists of two parts. For each of these two parts a separate statement will be formulated.The first part is an inventory of agent theory, agents in practice, and the three layer model. The claim for this part is:
"Intelligent Software Agents make up a promising solution for the current (threat of an) information overkill on the Internet. The functionality of agents can be maximally utilized when they are employed in the (future) three layer structure of the Internet."
The second part will be about current, near-future and future agent developments. Questions such as "how will agents be used in the near future?", "who will be offering agents (and why)?", and "which problems/needs can be expected?" will be addressed here.
Because of the nature of this part, the second statement is a prediction:
"Agents will be a highly necessary tool in the process of information supply and demand. However, agents will not yet be able to replace skilled human information intermediaries. In the forthcoming years their role will be that of a valuable personal assistant that can support all kinds of people with their information activities."
Structure of the paper
In the next chapter, the theoretical side of agents will be more deeply looked at: what are agents, what makes them different from other techniques and what is the functionality they (will) have to offer?After having looked at agents in theory in chapter two, chapter three, "Intelligent Software Agents in Practice," will give an idea of the kind of practical applications that agents and the agent technique are already being used in.
In chapter four, a three layer model will be sketched, where the agent technique is combined with the functionality offered by the various Internet services. Together they can be used to come to a Internet that offers more functionality, is more surveyable, and has a cleaner logical structure than the current (two-layer) set-up.
The second part of this thesis, comprised by the chapters five and six, is entirely about past, present and future developments, prediction and expectations. The parties and factors that have, are, or will be influencing developments are looked at in more detail.
In chapter seven, the thesis will be concluded with concluding remarks and a look at the accuracy of the two statements of the previous section.
Introduction
Intelligent software agents are a popular research object these days in such fields as psychology, sociology and computer science. Agents are most intensely studied in the discipline of Artificial Intelligence (AI). Strangely enough, it seems like the question what exactly an agent is, has only very recently been addressed seriously."It is in our best interests, as pioneers of this technology, to stratify the technology in such a way that it is readily marketable to consumers. If we utterly confuse consumers about what agent technology is (as is the case today) then we'll have a hard time fully developing the market potential." - J. Williams on the Software Agents Mailing List
Because of the fact that currently the term "agent" is used by many parties in many different ways, it has become difficult for users to make a good estimation of what the possibilities of the agent technology are. At this moment, there is every appearance that there are more definitions than there are working examples of systems that could be called agent-based.
Agent producers that make unjust use of the term agent to designate their product, cause users to draw the conclusion that agent technology as a whole has not much to offer. That is - obviously - a worrying development:
"In order to survive for the agent, there must be something that really distinguishes agents from other programs, otherwise agents will fail. Researchers, the public and companies will no longer accept things that are called agent and the market for agents will be very small or even not exist." - Wijnand van de Calseyde on the Software Agents Mailing List
On the other hand, the description of agent capabilities should not be too rose-colored either.
Not everybody is that thrilled about agents. Especially from the field of computer science, a point of criticism often heard about agents is that they are not a new technique really, and that anything that can be done with agents "can just as well be done in C". According to these critics, agents are nothing but the latest hype.
The main points of criticism can be summarized as follows:
- Mainstream AI research (expert systems, neural networks) is not as successful as many people had hoped and the new paradigm of agents is the way to escape;
- Everything that has the label "agent" sells (this also counts in research). Like the words 'plus', 'super' and 'turbo', the term 'agent' sounds very attractive, even when most people do not know the exact meaning of 'plus', 'super', 'turbo' or 'agent'. Agents are nothing more but old wine in new bottles;
- Because of the fact that in most cases current software agents have neither a very sophisticated nor a very complicated architecture, some wonder what qualifies them as "intelligent" [ 10 ].
Particularly by researchers in the field of AI, these points of criticism are refuted with the following arguments:
- What distinguishes multi-agent architectures from other architectures is that they provide acceptable solutions to certain problems at an affordable price. These are the kind of problems that cannot not be solved with available resources in reasonable time with monolithic knowledge based systems [ 11 ].
An example of this can be found in the field of integrated decision making, where systems are built where a single final diagnose is based on the diagnoses of individual worker agents.
Moreover, there are some problems in the field of AI that cannot be solved satisfactorily unless a multi-agent architecture (i.e. an architecture where independent agents are working together to accomplish all kinds of tasks) is used;
- Agents make it possible to eradicate the differences between the different kinds of networks (WAN, LAN , Internet) and to make the borders between them 'disappear'. Some researchers like to take this one step further by playing with the notion of agents that supersede AI [ 12 ].
The response of (particularly) these researchers to the pronouncement quoted earlier, that what agents can do "can just as well be done in C", can be summarized in the following points:
- It does not matter what the underlying technique of agents is. Whether that is a C program, a Perl script, or a LISP program: what it all boils down to is what the agent is and is not capable of doing. Or to be more precise: whether the agent is capable of displaying intelligent behavior. And whether the basis for that behavior is a C program, or whatever other programming language or technique, does not really matter;
- It does not always apply that everything that can be done by multiple cooperative agents may "just as well be done in C" (not even in the object oriented variant of that programming language). There are several tasks and problems for which there is scientific proof that they cannot be accomplished or solved by one single program or person. These kind of problems call for a distribution of the task or problem over multiple entities (i.e. a multi-agent architecture) because this will lead to a solution in a much shorter time, and quite often to a solution of a higher quality because it is the result of a subtle combination of the partial results of each individual entity.
The 'pros' and 'cons' with regards to agents as they are mentioned here, are by no means complete, and should be seen as merely an illustration of the general discussions about agents. What it does show is why it is necessary (in several respects) to have a definition of the concept "intelligent software agent" that is as clear and as precise as possible. It also shows that there is probably a long way to go before we arrive at such a definition - if we can come to such a definition at all.
Definition
"An agent is a software thing that knows how to do things that you could probably do yourself if you had the time."
Ted Selker of the IBM Almaden Research Center (quote taken from Janca (1995))In this section we will not come to a rock-solid formal definition of the concept "agent". Given the multiplicity of roles agents can play, this is quite impossible and even very impractical. On the Software Agents Mailing List, however, a possible informal definition of an intelligent software agent was given:
"A piece of software which performs a given task using information gleaned from its environment to act in a suitable manner so as to complete the task successfully. The software should be able to adapt itself based on changes occurring in its environment, so that a change in circumstances will still yield the intended result."
(with thanks to G. W. Lecky-Thompson for this definition)Instead of the formal definition, a list of general characteristics of agents will be given. Together these characteristics give a global impression of what an agent "is" [ 13 ].
The first group of characteristics, which will be presented in the next section, are connected to the weak notion of the concept "agent". The fact that an agent should possess most, if not all of these characteristics, is something that most scientists have agreed upon at this moment.
This is not the case, however, with the second group of characteristics, which are connected to the strong notion of the concept "agent". The characteristics that are presented in the following section on the "strong" agent are not things that go without saying for everybody.
What "intelligence" is, and what the related term "agency" means, is also explained after a discussion of these notions of "weak" and "strong" agents.
The Weak notion of the concept "agent"
Perhaps the most general way in which the term agent is used, is to denote a hardware or (more usually) software-based computer system that enjoys the following properties:
- autonomy: agents operate without the direct intervention of humans or others, and have some kind of control over their actions and internal state [ 14 ];
- social ability: agents interact with other agents and (possibly) humans via some kind of agent communication language [ 15 ];
- reactivity: agents perceive their environment (which may be the physical world, a user via a graphical user interface, a collection of other agents, the Internet, or perhaps all of these combined), and respond in a timely fashion to changes that occur in it [ 16 ]. This may entail that an agent spends most of its time in a kind of sleep state [ 17 ] from which it will awake if certain changes in its environment (like the arrival of new e-mail) give rise to it;
- proactivity: agents do not simply act in response to their environment, they are able to exhibit goal-directed behavior by taking the initiative;
- temporal continuity: agents are continuously running processes (either running active in the foreground or sleeping/passive in the background), not once-only computations or scripts that map a single input to a single output and then terminate;
- goal orientedness: an agent is capable of handling complex, high-level tasks. The decision how such a task is best split up in smaller sub-tasks, and in which order and in which way these sub-tasks should be best performed, should be made by the agent itself.
Thus, a simple way of conceptualizing an agent is as a kind of UNIX-like software process, that exhibits the properties listed above. A clear example of an agent that meets the weak notion of an agent is the so-called softbot ('software robot'). This is an agent that is active in a software environment (for instance the previously mentioned UNIX operating system).
The Strong(er) notion of the concept "agent"
For some researchers - particularly those working in the field of AI - the term agent has a stronger and more specific meaning than that sketched out in the previous section. These researchers generally mean an agent to be a computer system that, in addition to having the properties as they were previously identified, is either conceptualized or implemented using concepts that are more usually applied to humans. For example, it is quite common in AI to characterize an agent using mentalistic notions, such as knowledge, belief, intention, and obligation [ 18 ]. Some AI researchers have gone further, and considered emotional agents [ 19 ].
Another way of giving agents human-like attributes is to represent them visually by using techniques such as a cartoon-like graphical icon or an animated face [ 20 ]. Research into this matter [ 21 ] has shown that, although agents are pieces of software code, people like to deal with them as if they were dealing with other people (regardless of the type of agent interface that is being used).
Agents that fit the stronger notion of agent usually have one or more of the following characteristics [ 22 ]:
- mobility: the ability of an agent to move around an electronic network [ 23 ];
- benevolence: is the assumption that agents do not have conflicting goals, and that every agent will therefore always try to do what is asked of it [ 24 ];
- rationality: is (crudely) the assumption that an agent will act in order to achieve its goals and will not act in such a way as to prevent its goals being achieved - at least insofar as its beliefs permit [ 25 ];
- adaptivity: an agent should be able to adjust itself to the habits, working methods and preferences of its user;
- collaboration: an agent should not unthinkingly accept (and execute) instructions, but should take into account that the human user makes mistakes (e.g. give an order that contains conflicting goals), omits important information and/or provides ambiguous information. For instance, an agent should check things by asking questions to the user, or use a built-up user model to solve problems like these. An agent should even be allowed to refuse to execute certain tasks, because (for instance) they would put an unacceptable high load on the network resources or because it would cause damage to other users [ 26 ].
Although no single agent possesses all these abilities, there are several prototype agents that posses quite a lot of them (see chapter 3 for some examples). At this moment no consensus has yet been reached about the relative importance (weight) of each of these characteristics in the agent as a whole. What most scientists have come to a consensus about, is that it are these kinds of characteristics that distinguish agents from ordinary programs.
"Agency" and "Intelligence"
The degree of autonomy and authority vested in the agent, is called its agency. It can be measured at least qualitatively by the nature of the interaction between the agent and other entities in the system in which it operates.At a minimum, an agent must run a-synchronously. The degree of agency is enhanced if an agent represents a user in some way. This is one of the key values of agents. A more advanced agent can interact with other entities such as data, applications, or services. Further advanced agents collaborate and negotiate with other agents.
What exactly makes an agent "intelligent" is something that is hard to define. It has been the subject of many discussions in the field of Artificial Intelligence, and a clear answer has yet to be found. Here is one workable definition of what makes an agent intelligent [ 27 ]:
"Intelligence is the degree of reasoning and learned behavior: the agent's ability to accept the user's statement of goals and carry out the task delegated to it. At a minimum, there can be some statement of preferences, perhaps in the form of rules, with an inference engine or some other reasoning mechanism to act on these preferences. Higher levels of intelligence include a user model or some other form of understanding and reasoning about what a user wants done, and planning the means to achieve this goal. Further out on the intelligence scale are systems that learn and adapt to their environment, both in terms of the user's objectives, and in terms of the resources available to the agent. Such a system might, like a human assistant, discover new relationships, connections, or concepts independently from the human user, and exploit these in anticipating and satisfying user needs."
The User's "Definition" of Agents
"User knowledge, rather than product capability, is the principal determinant of agent-enabled application usage today. ... User need is the principal consideration in developing/executing business strategies for agent-enabled products [ 28 ]."Just like in the oncoming information society, the success and development of agents and the agent technique are driven by users really, instead of by producers or researchers [ 29 ]. So, when considering just exactly what an agent is, and which aspects of it are very important and which are less important, the ever important user factor should not be overlooked.
Users will not start to use agents because of their benevolence, proactivity or adaptivity, but because they like the way agents help and support them in doing all kinds of tasks; soon users will use all sorts of convenient (i.e. "intelligent) applications, without them realizing they are using agents by doing so.
As was pointed out at the beginning of this chapter, there is one good reason why a fairly concise definition of an agent that can meet with general approval, should be drawn up as soon as possible: clarity towards the user. By all means it should be prevented that "agent" becomes a vague, meaningless and empty term, in the way a term such as "multi-media" has lost its meaning in the course of time. Agents will be perceived as nothing but the latest marketing hype:
"Just take your old program, and add an agent to the end of your product name. Voila! You have an Object Agent, Test Agent. ... [ 30 ]"
More about (professional) user's views on agents, will follow in chapter five and six.
Summary
Today, agents are a popular research object in many scientific fields. An exact definition and exact set of characteristics (and their relative weight) are yet to be stated and chosen.Ultimately, users of agents and agent-enabled programs will be the principal determinant of how agents will look, what they will be, and what things they should and should not be able to do.
Applications of Intelligent Agents
The current applications of agents are of a rather experimental and ad hoc nature. Besides universities and research centers a considerable number of companies, like IBM and Microsoft, are doing research in the area of agents. To make sure their research projects will receive further financing, many researchers & developers of such companies (but this is also applicable on other parties, even non-commercial ones) are nowadays focusing on rather basic agent applications, as these lead to demonstrable results within a definite time.Examples of this kind of agent applications are:
- Agents who partially or fully handle someone's e-mail;
- Agents who filter and/or search through (Usenet) news articles looking for information that may be interesting for a user;
- Agents that make arrangements for gatherings such as a meeting, for instance by means of lists provided by the persons attending or based on the information (appointments) in the electronic agenda of every single participant.
The current trend in agent developments is to develop modest, low-level applications. Yet, more advanced and complicated applications are more and more being developed as well.
At this moment research is being done into separate agents, such as mail agents, news agents and search agents. These are the first step towards more integrated applications, where these single, basic agents are used as the building blocks. Expectations are that this will become the trend in the next two or three years to come. (Note that this does not mean that there will be no or little interesting developments and opportunities in the area of smaller, more low-level agent applications.)
In chapter four a model will be presented which supports this trend towards more complex, integrated systems. In this model basic agents can easily be combined to create complex structures which are able to perform high-level tasks for users, suppliers and intermediaries. The interface to this system (i.e. model) is through a single agent which delegates sub-tasks and queries to other agents.
Eight application areas have been identified where current (or in the near-future) agent technology is (or will be) used [ 31 ].
These areas are:
1. Systems and Network Management
Systems and network management is one of the earliest application areas to be enhanced using intelligent agent technology. The movement to client/server computing has intensified the complexity of systems being managed, especially in the area of LANs, and as network centric computing becomes more prevalent, this complexity further escalates. Users in this area (primarily operators and system administrators) need greatly simplified management, in the face of rising complexity. Agent architectures have existed in the systems and network management area for some time, but these agents are generally "fixed function" rather than intelligent agents. However, intelligent agents can be used to enhance systems management software. For example, they can help filter and take automatic actions at a higher level of abstraction, and can even be used to detect and react to patterns in system behavior. Further, they can be used to manage large configurations dynamically;2. Mobile Access / Management
As computing becomes more pervasive and network centric computing shifts the focus from the desktop to the network, users want to be more mobile. Not only do they want to access network resources from any location, they want to access those resources despite bandwidth limitations [ 32 ] of mobile technology such as wireless communication, and despite network volatility.Intelligent agents which (in this case) reside in the network rather than on the users' personal computers, can address these needs by persistently carrying out user requests despite network disturbances. In addition, agents can process data at its source and ship only compressed answers to the user, rather than overwhelming the network with large amounts of unprocessed data;
3. Mail and Messaging
Messaging software (such a software for e-mail) has existed for some time, and is also an area where intelligent agent function is currently being used. Users today want the ability to automatically prioritize and organize their e-mail, and in the future, they would like to do even more automatically, such as addressing mail by organizational function rather than by person.Intelligent agents can facilitate all these functions by allowing mail handling rules to be specified ahead of time, and letting intelligent agents operate on behalf of the user according to those rules. Usually it is also possible (or at least it will be) to have agents deduce these rules by observing a user's behavior and trying to find patterns in it;
4. Information Access and Management
Information access and management is an area of great activity, given the rise in popularity of the Internet and the explosion of data available to users. It is the application area that this thesis will mainly focus on. Here, intelligent agents are helping users not only with search and filtering, but also with categorization, prioritisation, selective dissemination, annotation, and (collaborative) sharing of information and documents;5. Collaboration
Collaboration is a fast-growing area in which users work together on shared documents, using personal video-conferencing, or sharing additional resources through the network. One common denominator is shared resources; another is teamwork. Both of these are driven and supported by the move to network centric computing. Not only do users in this area need an infrastructure that will allow robust, scaleable sharing of data and computing resources, they also need other functions to help them actually build and manage collaborative teams of people, and manage their work products. One of the most popular and most heard-of examples of such an application is the groupware packet called Lotus Notes;6. Workflow and Administrative Management [ 33 ]
Administrative management includes both workflow management and areas such as computer/telephony integration, where processes are defined and then automated. In these areas, users need not only to make processes more efficient, but also to reduce the cost of human agents. Much as in the messaging area, intelligent agents can be used to ascertain, then automate user wishes or business processes;7. Electronic Commerce
Electronic commerce is a growing area fueled by the popularity of the Internet. Buyers need to find sellers of products and services, they need to find product information (including technical specifications, viable configurations, etc.) that solve their problem, and they need to obtain expert advice both prior to the purchase and for service and support afterward. Sellers need to find buyers and they need to provide expert advice about their product or service as well as customer service and support. Both buyers and sellers need to automate handling of their "electronic financial affairs".Intelligent agents can assist in electronic commerce in a number of ways. Agents can "go shopping" for a user, taking specifications and returning with recommendations of purchases which meet those specifications. They can act as "salespeople" for sellers by providing product or service sales advice, and they can help troubleshoot customer problems;
8. Adaptive User Interfaces
Although the user interface was transformed by the advent of graphical user interfaces (GUIs), for many, computers remain difficult to learn and use. As capabilities and applications of computers improve, the user interface needs to accommodate the increase in complexity. As user populations grow and diversify, computer interfaces need to learn user habits and preferences and adapt to individuals.Intelligent agents (called interface agents [ 34 ]) can help with both these problems. Intelligent agent technology allows systems to monitor the user's actions, develop models of user abilities, and automatically help out when problems arise. When combined with speech technology, intelligent agents enable computer interfaces to become more human or more "social" when interacting with human users.
Examples of agent applications and entire agent systems
Because of the fact that a lot of research is being done in the field of agents, and because many like to field-test theories (i.e. implementations), a lot of agents are active on the Internet these days. Comparing them is not an easy task as their possibilities and degree of elaboration vary strongly. Add to this the fact that there still is no well-defined definition of what an agent is, and it is easy to see how difficult it is to judge whether or not a piece of software may be called an agent, and (if it is judged to be one) how good (or "intelligent") it is.Still, four examples from the broad variety of agent applications and agent systems have been selected to be given a closer look.
The two agent applications serve as examples of what is currently being done with agents in (relatively small) commercial applications. The agent systems are still more or less in the development (i.e. research) phase, but judging by what is said in their documentation, both are to be developed into full-fledged systems which may or may not become commercial products.
The chosen examples are to be seen as examples of what can be done with agents in actual practice. The choice for these specific agent implementations should not be seen as some kind of personal value judgment.
Two examples of agent applications
Open Sesame!
Open Sesame! is a software agent that learns the way users work with their Macintosh applications. "It streamlines everything you do on your desktop. It eliminates mundane, time-consuming tasks so that every minute you spend at your computer is productive". Open Sesame! uses a learning agent which observes user's activities and learns which tasks are repeated again and again. It then offers to perform those repetitive tasks for the user automatically.Open Sesame! can also automate crucial maintenance tasks the user may (easily) forget, such as rebuilding the desktop.
Some of the features of Open Sesame! are:
- It learns work patterns and generates instructions that automate tasks;
- It automatically performs tasks at specified times;
- It automatically performs two or more tasks that the user would otherwise have to perform separately;
- It gives the user shortcuts for opening or closing a related group of folders, applications and documents;
- It arranges windows of scriptable applications so the user can work with multiple applications more efficiently;
- It offers power users the option to expand Open Sesame! with AppleScript [ 35 ] applets and macro utility mini-applications.
Open Sesame! uses Apple events to learn a user's patterns and to automate them. It is not a replacement for AppleScript: while the former provides a subset of the commands (such as opening documents and applications), it also provides functionality not available in the latter. However, sometimes it can be useful to use them together as AppleScript applets can be used as applications in Open Sesame! instructions.
One big advantage of Open Sesame! over tools such as AppleScript is that it generalizes the intent of a user's actions, and does not merely record every stroke and mouse click without any inference or generalization.
Open Sesame! uses two types of triggers: time-based and event-based. Time-based triggers will execute certain instructions at a given time, whereas event-based triggers cause it to execute an instruction in response to a desktop action such as opening a folder, quitting an application, start-up, shutdown and so on.
Hoover
The second example is SandPoint's Hoover, which "provides a single user interface to multiple information media, including real-time news wires, on-line databases, field intelligence, and corporate computing resources. Hoover automatically organizes selected information according to the context of the user's need or function. Designed for groups of users, Hoover currently works with Lotus Notes. Support for other groupware solutions is under development."Hoover's applications can be divided into five areas:
- Current Awareness
Hoover has an information agent that delivers two types of current awareness: real-time news and full-text premier publications. For the first type of current awareness, Hoover can organize news in many different ways: by company, industry, government category, dateline, region, and more. Back issues of publications are stored on the Hoover server, enabling the user to review a past story or track of a certain development. The second type enables full-text word searching, enabling deep searches in news articles;
- Research
Based on the type of information the user wants, such as information on companies, people, places, and markets, Hoover's research agent will search for information based on the appropriate context. Searching through news feeds and on-line databases in real-time is a further possibility. The thus retrieved information can be updated automatically as often as necessary;
- Information Enabled Applications
Hoover offers so-called "information enabled applications" which "accelerate workflow and deliver specific information for decision making support";
- Corporate Intelligence
Some of the most valuable sources of information for a company are the people working for it. With this part of Hoover, a place can be provided for team members to contribute what they've learned for knowledge-sharing. "Volumes of important ideas and observations - an essential part of the intellectual capital of a company - will be available for everyone. And neatly integrated with authoritative external sources";
- Internal Databases
This part of Hoover unites internal and external information. It can draw from information in internal databases because of the open system architecture of the Hoover Scripting Language Tool Kit. "Now you can unite internal information with the Electronic Ocean outside ...".
Hoover is able to meet about 75% of common information needs. Additions, such as a research center, can be used for the more complex searches.
Two examples of entire agent systems
The Internet Softbot
Etzioni and Weld's list of currently available agents gives one view of what is already being done with intelligent software agents [ 36 ]. As a means of showing what the differences between the mentioned agents are, the (well-known) metaphor of the information highway is used. On this highway an intelligent agent may be a backseat driver who makes suggestions at every turn (Tour Guides), a taxi driver who takes you to your destination (Indexing Agents or FAQ-Finders), or even a concierge whose knowledge and skills make it unnecessary for a person to approach the superhighway at all.A draw-back of tour guides and indexing agents is that their actions and suggestions are based on a relatively weak model of what the user wants and what information is available at a suggested location. An attempt to change this is the Internet Softbot (developed by the University of Washington). The aim is to create an agent that attempts to determine what the user wants and understands the contents of information services.
The agents that were described in the metaphor, access unstructured or semi-structured information (such as text files). The Internet Softbot tackles a different component of information on the Internet: structured information services such as stock quote servers or library databases.
Because the information is structured, the Softbot need not rely on natural language or information retrieval techniques to "understand" the information provided by a service. Instead, the Softbot relies on a model of the service for the precise semantics associated with information provided by the service. As a result, the Softbot can answer focused queries with relatively high reliability; the chances of finding relevant information are high and the amount of non-relevant information ('noise') is (relatively) low.
The key idea behind the Softbot is reflected in its name, which is derived from software robot. Its tools consist of UNIX commands such as ftp, print, and mail. Commands like list files and Internet services such as Finger and Netfind [ 37 ] are used as a kind of sensors to find information. Internally, a least-commitment planner provides behavioral control of the Softbot. Several technical innovations were necessary, however, to make this approach successful in the complex world of the Internet.
The Internet Softbot is a prototype implementation of a high-level assistant, analogous to a hotel concierge. In contrast to systems for assisted browsing or information retrieval, the Softbot can accept high-level user goals and dynamically synthesize the appropriate sequence of Internet commands to satisfy those goals. The Softbot executes the sequence, gathering information to aid future decisions, recovering from errors, and retrying commands if necessary.
The Softbot eliminates a person's need to "drive" the information superhighway at all; the person (user) delegates that job to the Softbot. More general: the Softbot allows a user to specify what to accomplish, while it handles the decisions of how and where to accomplish it. This makes the Internet Softbot a good example of a goal-oriented agent.
The goal-orientedness of the Softbot is useful only if users find specifying requests to it easier than carrying out activities themselves. The agent has three properties which should make goal specification convenient for users:
1. An expressive goal language
The Softbot accepts goals containing complex combinations of conjunction, disjunction, negation, and nested universal and existential quantification. This allows specification of tasks such as "Get all of researcher Joe's technical reports that are not already stored locally";2. A convenient syntax and interface for formulating requests
Despite the expressive power of mathematical logic, many users are unable (or unwilling) to type long, complex, quantifier-laden sentences (something many Information Retrieval systems require). For this reason, the Softbot supplies a forms-based graphical user interface and automatically translates forms into the logical goal language. Natural language input, an alternative approach pursued by many researchers, is not yet incorporated in the Softbot;3. Mixed-initiative refinement dialogue
Even with a well-engineered interface, it is difficult to specify orders precisely. Human assistants solve this problem by asking questions to their client in order to be able to iteratively refine a given goal. The current Softbot has only limited support for in-between questions, but a new interface is being designed that will allow the Softbot to pose questions (while it continues to work) and allow the user to add information and constraints.The Softbot possesses many, but not all of the desired characteristics as they were described earlier. It is autonomous, goal-oriented, flexible and self-starting (i.e. it possesses "reactivity"). At this moment work is being done to extend the Softbot's collaborative, communicative, adaptive and personality-characteristics.
The Softbot is not mobile, but it does not really need to be that. What's more, it would entail all kinds of complicated security and privacy issues (with regard to its user).
The Info Agent
D'Aloisi and Giannini present a system that supports users in retrieving data in distributed and heterogeneous archives and repositories [ 38 ]. The architecture is based on the metaphor of software agents and incorporates techniques from other research fields such as distributed architectures, relevance feedback and active interfaces.When designing and developing the information agents for their system, the aim was to make the system suitable for different types of users with regard to local and external searches for information and data.
One single agent, called the Info Agent, is used as the interface between the system and the user. The Info Agent, in its turn, uses a so called Interface Agent for handling the communication with the user. This agent is like a personal assistant who is responsible for handling user needs, and for the connection of the user with the agent(s) that will help him solve his problem. The number of types of agents the Interface Agent has to deal with, depends on the aims of the system. As a result of the distributed and agent-based architecture of the system the whole structure of it can be easily changed or updated by adjusting the Interface Agent only.
The Interface Agent is able to reason about the user's requests and to understand what type of need he is expressing: it singles out which of the two other agents in the system is able to solve the current problem and sends to it its interpretation of the query (using KQML - the Knowledge Query and Manipulation Language). These other two agents are the Internal Services Agent and the External Retrieval Agent.
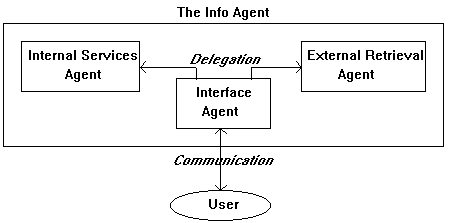
Figure 1: The Structure of the Info Agent system
The Internal Services Agent knows the structure of the archives available in a given organization: it is in charge of retrieving scientific and administrative data, performing some classes of actions (such as finding available printers) and supporting the user in compiling internal forms.The External Retrieval Agent is in charge of retrieving documents on the network. It can work in two modalities: retrieval (or query) mode and surfing mode. In the first case, it searches for a specific document following a query asked by the user: this service is activated by a direct user request. In the second case, the agent navigates the network searching for documents that, in its opinion, could interest the user. The search is driven by a user's profile built and maintained by the Interface Agent.
Refinement of this profile takes place according to how the user manages the data that the agent finds for and/or proposes him. Using the user's profile, the Interface Agent charges specialized agents to navigate through the network hunting for information that could be of some interest for the user. In this way, the user can be alerted when new data that can concern his interest area(s) appear.
Currently, both the External Retrieval Agent as well as the Internal Services Agent utilize the same software tool to perform their search: it is a public-domain software called Harvest, which is "an integrated set of tools to gather, extract, organize, search, cache and replicate relevant information across the Internet". Nevertheless it is also possible to provide the system with other search methods or systems to be used alone or along with Harvest: that is an advantage due to the modular and distributed architecture of the whole framework. The number of agents coordinated by the Interface Agent is also a part of the system that can quite easily be changed.
In a nutshell the Interface Agent has the following crucial system tasks:
- Assisting the user in performing requests and compiling his profile.
The user does not need to be aware of what is available on the network, how this information is structured and organized, where the repositories are localized, or what retrieval services are at disposal. This is the responsibility of the Interface Agent;- Deducing the user's information needs by both communicating with him and observing his "behavior".
The agent observes the user's behavior and the current state of the world to deduce what actions are to be performed and how to modify the current user's profile;- Translating the requests of the user and selecting the agent(s) able to solve his problem(s).
This allows the user to completely ignore the structure of the system he is interacting with. Moreover he can also ignore how the system works. The user interacts with a personalized interface that knows how to satisfy his requests without bothering him with all sorts of details;- Presenting and storing the retrieved data.
This avoids the user to know the different formats (such as WordPerfect, Postscript or LaTeX format) and how to manage a document to have a printable or showable version. The Info Agent deals with each retrieved document according to its format and transforms it into a form the user can utilize (e.g. convert a LaTeX document into WordPerfect format).The Info Agent resembles, in a number of ways, the Softbot. One of the differences between these two agents is that the Info Agent focuses mainly on the user, whereas the Softbot focuses mainly on the requests of the user. Another difference is that the Info Agent searches in both structured as well as unstructured information (documents), whereas the Softbot "limits" itself to structured information only.
Summary
Currently available agent-systems and agent-enabled applications are of a rather basic and ad hoc nature. However, more complex and elaborated systems are in the making.In this chapter, eight application areas of the agent-technology have been identified. From those areas, Information Access and Management, Collaboration [ 39 ] and Electronic Commerce are the ones that are most intensely studied at this moment (note that this is research that is not only into agents and agent-enabled applications, but into many other subjects as well). To give an idea of what is already possible with agents, i.e. what is already being done with the agent technology, four examples of agent-systems and agent-enabled applications were described.
Bjorn Hermans is currently working as an Internet Application Engineer at Cap Gemini B.V. in the Netherlands. This paper originally appeared as his thesis for his studies into Language & Artificial Intelligence at Tilburg University.Hermans' e-mail address is hermans@hermans.org and his Web site can be found at http://www.hermans.org
Acknowledgements
There are many persons that have contributed to the realisation of this paper, and I am very grateful to all those who did.
There are a few persons that I would especially like to thank: Jan de Vuijst (for advising me, and for supporting me with the realisation of this thesis), Peter Janca, Leslie Daigle and Dan Kuokka (for the valuable information they sent me), and Jeff Bezemer (for his many valuable remarks).
Literature
D. D'Aloisi, D. and V. Giannini, 1995. The Info Agent: an Interface for Supporting Users in Intelligent Retrieval, (November).
The High-Level Group on the Information Society. Recommendations to the European Council - Europe and the global information society (The Bangemann Report). Brussels, (May).
L. Daigle, 1995. Position Paper. ACM SigComm'95 - MiddleWare Workshop (April).
Daigle, Deutsch, Heelan, Alpaugh, and Maclachlan, 1995. Uniform Resource Agents (URAs). Internet-Draft (November).
O. Etzioni and D. S. Weld, 1994. A Softbot-Based Interface to the Internet, Communications of the ACM, vol. 37, no. 7 (July), pp 72-76.
O. Etzioni, O. and D. S. Weld, 1995. Intelligent Agents on the Internet - Fact, Fiction, and Forecast, IEEE Expert, no. 4, pp. 44-49, (August).
R. Fikes, R. Engelmore, A. Farquhar, and W. Pratt, 1995. Network-Based Information Brokers. Knowledge System Laboratory, Stanford University.
Gilbert, Aparicio, et al. The Role of Intelligent Agents in the Information Infrastructure. IBM, U. S.
IITA, Information Infrastructure Technology and Applications, 1993. Report of the IITA Task Group High Performance Computing, Communications and Information Technology Subcommittee.
P. Janca, 1995. Pragmatic Application of Information Agents. BIS Strategic Decisions, Norwell, U. S., (May).
Ted G. Lewis, 1995-1996. SpinDoctor WWW pages.
National Research Council, 1994. Realizing the Information Future - The Internet and Beyond. Washington D. C.
H. S. Nwana, 1996. Software Agents: An Overview. Intelligent Systems Research, BT Laboratories, Ipswich, U. K.
P. Resnick, R. Zeckhauser and C. Avery, 1995. Roles for Electronic Brokers, Cambridge, Mass.: MIT.
M. Rohs, 1995. WWW-Unterstützung durch intelligente Agenten. Elaborated version of a presentation given as part of the Proseminar "World-Wide-Web", Fachgebiet Verteilte Systeme des Fachbereichs Informatik der TH Darmstadt.
SRI International. Exploring the World Wide Web Population's Other Half, (June).
M. Wooldridge and N. R. Jennings, 1995. Intelligent Agents: Theory and Practice, (January).
R. H. Zakon, 1996. Hobbes' Internet Timeline v2.3a.
Information Sources on the Internet
The @gency: A WWW page by Serge Stinckwich, with some agent definitions, a list of agent projects and laboratories, and links to agent pages and other agent-related Internet resources.Agent Info: A WWW page containing a substantial bibliography on and Web Links related to Interface Agents. It does provide some information on agents in general as well.
Agent Oriented Bibliography: Note that as this project is at beta stage, response times might be slow and the output is not yet perfect. Any new submissions are warmly welcomed.
Artificial Intelligence FAQ: Mark Kantrowitz' Artificial Intelligence Frequently Asked Questions contains information about AI resources on the Internet, AI Associations and Journals, answers to some of the most frequently asked questions about AI, and much more.
Global Intelligence Ideas for Computers: A WWW page by Eric Vereerstraeten about "assistants or agents [that] are appearing in new programs, [and that] are now wandering around the web to get you informed of what is going on in the world". It tries to give an impression of what the next steps in the development of these agents will be.
Intelligent Software Agents: These pages, by Ralph Becket, are intended as a repository for information about research into fields of AI concerning intelligent software agents.
Intelligent Software Agents: This is an extensive list that subdivides the various types of intelligent software agents into a number of comprehensive categories. Per category, organisations, groups, projects and (miscellaneous) resources are listed. The information is maintained by Sverker Janson.
Personal agents: A walk on the client side: A research paper by Sharp Laboratories. It outlines "the role of agent software in personal electronics in mediating between the individual user and the available services" and it projects " a likely sequence in which personal agent-based products will be successful". Other subjects that are discussed are "various standardisation and interoperability issues affecting the practicality of agents in this role".
Project Aristotle: Automated Categorization of Web Resources: This is "a clearinghouse of projects, research, products and services that are investigating or which demonstrate the automated categorization, classification or organization of Web resources. A working bibliography of key and significant reports, papers and articles, is also provided. Projects and associated publications have been arranged by the name of the university, corporation, or other organization, with which the principal investigator of a project is affiliated". It is compiled and maintained by Gerry McKiernan.
SIFT: SIFT is an abbreviation of "Stanford Information Filtering Tool", and it is a personalised Net information filtering service. "Everyday SIFT gathers tens of thousands of new articles appearing in USENET News groups, filters them against topics specified by you, and prepares all hits into a single web page for you." SIFT is a free service, provided as a part of the Stanford Digital Library Project.
The Software Agents Mailing List FAQ: A WWW page, maintained by Marc Belgrave, containing Frequently Asked Questions about this mailing list. Questions such as "how do I join the mailing list?", but also "what is a software agent?" and "where can I find technical papers and proceedings about agents?" are answered in this document.
UMBC AgentWeb: An information service of the UMBC's Laboratory for Advanced Information Technology, maintained by Tim Finin. It contains information and resources about intelligent information agents, intentional agents, software agents, softbots, knowbots, infobots, etcetera.
1. "Information society" or "Information Age" are both terms that are very often used nowadays. The terms are used to denote the period following the "Post-Industrial Age" we are living in right now.2. Articles in professional magazines indicate that these problems are not appearing on the Internet only: large companies that own databases with gigabytes of corporate information stored in them (so-called data warehouses), are faced with similar problems. Many managers cannot be sure anymore which information is, and which is not stored in these databases. Combining the stored data to extract valuable information from it (for instance, by discovering interesting patterns in it) is becoming a task that can no longer be carried out by humans alone.
3. For example, the gathering programs that collect information for the Lycos search engine, create document abstracts which consist of the document's title, headings and subheadings, the 100 most weighty words, the first 20 lines, its size in bytes and the number of words.
4. There are many Search Engines on-line on the Internet. These search engines allow a user to search for information in many different ways, and are highly recommended web search tools for the time being.
5. There are many different kinds of software agents, ranging from Interface agents to Retrieval agents. This thesis will be mainly about agents that are used for information tasks (such as offering, finding or editing all kinds of information). Many things that are said about agents in this thesis do, however, also apply to the other kinds of agents. However (for briefness' sake), we will only concern ourselves with information agents in this paper.
6. Users do not directly search the information on the Internet itself, but the meta-information that has been gathered about it. The result of such a search, is not the meta-information itself, but pointers to the document(s) it belongs to.
7. If a document is retrieved which turns out to be no longer available, the search engine does not learn anything of this happening: it will still be retrieved in future sessions. A search engine also does not store query results, so the same query will be repeated over and over again, starting from scratch.
8. As opposed to the more or less two layer structure of the current Internet (one layer with users and another layer with suppliers).
9. The term "layers" is perhaps a bit misleading as it suggests a hierarchy that is not there: all three layers are of equal importance. Thinking of the layers in terms of concepts or entities may make things more clearer.
10. Unfortunately that question opens up the old AI can-of-worms about definitions of intelligence. E.g., does an intelligent entity necessarily have to possess emotions, self-awareness, etcetera, or is it sufficient that it performs tasks for which we currently do not possess algorithmic solutions?
11. The 'opposite' can be said as well: in many cases the individual agents of a system aren't that intelligent at all, but the combination and co-operation of them leads to the intelligence and smartness of an agent system.
12. These researchers see a paradigm shift from those who build intelligent systems and consequently grapple with problems of knowledge representation and acquisition, to those who build distributed, not particularly, intelligent systems, and hope that intelligence will emerge in some sort of Gestalt fashion. The knowledge acquisition problem gets solved by being declared to be a 'non-problem'.
13. See M. Wooldridge and N. R. Jennings, Intelligent Agents: Theory and Practice (January 1995) for a more elaborated overview of the theoretical and practical aspects of agents.
14. See C. Casterfranchi, 1995. "Guarantees for autonomy in cognitive agent architecture," In: M. Woolridge and N. R. Jennings (editors), Intelligent Agents: Theories, Architectures, and Languages (LNAI Volume 890), Springer-Verlag: Heidelberg, pp. 56-70.
15. See M. R. Genesereth and S. P. Ketchpel, 1994. "Software Agents," Communications of the ACM, vol. 37, no. 7, pp. 48-53.
16. Note that the kind of reactivity that is displayed by agents, is beyond that of so-called (UNIX) daemons. Daemons are system processes that continuously monitor system resources and activities, and become active once certain conditions (e.g. thresholds) are met. As opposed to agents, daemons react in a very straight-forward way, and they do not get better in reacting to certain conditions.
17. Analogous to the "sleep" state in a UNIX system, where a process that has no further tasks to be done, or has to wait for another process to finish, goes into a sleep state until another process wakes it up again.
18. See Y. Shoham, 1993. "Agent-oriented programming," Artificial Intelligence, vol. 60, no. 1, pp. 51-92.
19. See, for instance, J. Bates, 1994. "The Role of emotion in believable agents," Communications of the ACM, vol. 37, no. 7, pp. 122-125.
20. P. Maes, 1994. "Agents that reduce work and information overload," Communications of the ACM, vol. 37, no. 7, pp. 31-40.
21. See, for instance, D. Norman, 1994. "How Might People Interact with Agents," Communications of the ACM, (July).
22. This list is far from complete. There are many other characteristics of agents that could have been added to this list. The characteristics that are mentioned here are there for illustrative purposes and should not be interpreted as an ultimate enumeration.
23. J. E. White, 1994. Telescript technology: The foundation for the electronic marketplace. White paper, General Magic Inc.
24. J. S. Rosenschein and M. R. Genesereth, 1994. "Deals among rational agents," In: Proceedings of the Ninth International Joint Conference on Artificial Intelligence (IJCAI-85), pp. 91-99.
25. J. R. Galliers, 1994. A Theoretical Framework for Computer Models of Cooperative Dialogue, Acknowledging Multi-Agent Conflict. PhD dissertation, Open University (Great Britain), pp. 49-54.
26. D. Eichmann, 1994. " Ethical Web Agents," Proceedings of the Second International World-Wide Web Conference, Chicago (October).
27. IBM, 1995. The Role of Intelligent Agents in the Information Infrastructure.
28. P. Janca, 1995. Pragmatic Application of Information Agents. BIS Strategic Decisions, (May).
29. Users will not play that much of a very active steering-role, but user acceptance and adoption will be the ultimate test of agent's success.
31. IBM, 1995. The Role of Intelligent Agents in the Information Infrastructure.
32. Bandwidth is - in technical terms - the measure of information-carrying capability of a communication medium (such as optical fibre). An Internet service such as the World Wide Web, which makes use of graphical (and sometimes even audio or video) data, needs considerable amounts of bandwidth, whereas an Internet service such as e-mail needs only very small amounts.
33. A workflow is a system whose elements are activities, related to one another by a trigger relation and triggered by external events, which represents a business process starting with a commitment and ending with the termination of that commitment.
Workflow Management (WFM) is the computer assisted management of business processes through the execution of software whose order of execution is controlled by a computerised representation of the business processes.
34. Y. Lashkari, M. Metral, and P. Maes, 1994. Collaborative Interface Agents, Cambridge, Mass.: MIT Media Laboratory.
35. AppleScript allows a user to write small programs, or scripts, and uses Apple events to execute the program.
36. O. Etzioni and D. S. Weld, 1995. "Intelligent Agents on the Internet - Fact, Fiction, and Forecast," IEEE Expert, no. 4 (August), pp. 44-49.
37. Netfind is a tool that can help to find a person's exact email address, given their name and a reasonably close guess about the Internet name of the computer they use.
38. D. D'Aloisi and V. Giannini, 1995. The Info Agent: an Interface for Supporting Users in Intelligent Retrieval.
39. For more information about research being done into Collaboration (through the Internet), see WWW Collaboration Projects or the server dedicated to Collaborative Work.


Copyright © 1997, ƒ ¡ ® s † - m ¤ ñ d @ ¥







