Web pages cited with personal author identification in 12 longer Web bibliographies and a collection of 19 shorter Web bibliographies were investigated. With one exception, the personal author names could be matched in the visible text of the great majority of pages. Metatags (both for authors and for descriptions) and page titles rarely added any author information. In some cases, frames or inline graphics appeared to be the sources used. Somewhat more frequent probable sources were linked pages, such as home pages.Contents
Introduction
Methodology
Results
Discussion and conclusion
Introduction
One way or the other, titles can be identified for the great majority of Web pages. Around 88 to 96 percent of pages have been found to contain a title element (Craven, 2003). Apparent titles (titles as they would appear to be from viewing the beginning of the page in the browser, often coded as h1 elements) are almost as common as tagged titles; and a recent study of 16 Web bibliographies (Craven, 2002), found that the latter were almost always preferred in citations.
Other constituents of conventional bibliographic description, however, may be considerably harder to determine. For example, the date is often not indicated on a page, or an indicated date does not correspond to the actual date of the contents; examining the HTTP header may, or may not, yield a date for the file, depending on the configuration of the server.
Authorship or responsibility is also often unclear. Even when authorship may be deduced, the context in which an author is named is quite unpredictable. A metatag may be employed for this purpose, but this technique is not widely known, and common experience suggests that it is rarely applied. Authorship information is sometimes included in the title element. Sometimes, the responsible party may be inferred from a mailing address. What is most commonly recommended is for a phrase indicating responsibility to be included in the footer of the page, along with a date and contact information. Beginners are advised to look at the top or bottom of the page for author information (Savage, 2003). If the author is named nowhere on a page, it may be possible to deduce an answer by examining related pages on the same site; for example, by following a "Home" or "About us" link.
If the advice of Estivill and Urbano (1997) is followed, one should look first for authorship information, as for other bibliographic information, at the main rendering of the page and only if nothing is found there proceed to other sources, such as the title element, metatags, or other pages.
Land (1998) suggests allowing nicknames and e–mail addresses as Web page authors, but only when other sources of information, such as following links, have been exhausted. A previous study was concerned with quantifying, in a preliminary way, the extent to which pages can be assigned possible authors using either normal browsing procedures or browsing assisted by simple automatic extraction of likely candidates. Personal authors were apparent manually from about 16 percent of pages, and 4.5 percent could be added by reference to external sources (linked pages).
The present study addresses a related question, that of the actual practice of compilers of Web bibliographies in identifying personal authors of pages. To what extent do they limit themselves to information visible on the rendered form of the page, and to what extent do they derived personal author information from other sources; specifically, from metatags, page titles, inline elements (such as images and frames), and linked pages (such as home pages)?
Methodology
Two existing lists of Web bibliographies were used, one compiled in 2001 for a study of title in citations (Craven, 2002) and a second compiled for a follow–up study in 2003. Bibliographies that could no longer be located were eliminated, as were those giving essentially no personal author information for entries. If the number of eligible entries greatly exceeded 300, a systematic subset of around 300 was chosen. An entry was considered eligible if one or more personal authors appeared to be identified and if it had a link that appeared to be to a Web page (URLs ending with obvious non–HTML extensions such as .ps, .pdf, .doc, .txt, .gz, and .zip were eliminated, as were any for non–HTTP protocols, specifically FTP). The linked page might be an abstract, on the assumption that it would then have been written by the author, but could not appear to be a review or some other derivative. Duplicate URLs were eliminated, as were links to pages on the same site.
For each eligible entry, the personal author information and the URL were recorded. A previously developed software package was then used to attempt to access each URL and record information on matches between the given author data and page contents.
Pages that could not be accessed on either of two run–throughs ("rotten" links) were noted, together with the category of error. They were then eliminated from further analysis.
The longer bibliographies (with at least 50 remaining entries each) were treated separately, while the shorter bibliographies (each with fewer than 50 remaining entries) were combined into a single "short" compound bibliography.
Entries were then categorized as follows, on the basis of availability of author information:
v: in visible text (that is, in the body of the HTML file outside of any tags);
m: not v, but present in an author–indicative metatag (name or http–equiv attribute equal to "author," "owner," or "copyright");
d: not v or m, but present in a description in a metatag (name or http–equiv attribute equal to "description");
t: not v, m, or d, but in the title element;
f: none of the above, but present in a frame, image, or other inline object and so visible in a graphical browser;
h: none of the above, but on a clearly linked home page or other obvious linked page (such as an "About us" page);
b: none of the above, but clearly a bad link (that is, one to an error page, a page on a different subject, a page by a different author, or the like);
x: other (surname, nickname, or e–mail address only; no link to home page, even if one exists).Where the logged data were insufficient for the purposes of categorization, the pages were visited using a conventional graphical Web browser (Netscape Navigator 7.1) and appropriate links followed as necessary. In deciding whether author names matched, minor spelling errors were discounted.
Two specific subcategories of the v category were determined by semi–automatic means. The automatic component involved extracting of candidate author–identifying strings for each category; this was followed by manual determination of match with author names given in the bibliographies.
Candidate strings for the first subcategory were derived by looking for text sequences that looked like mailing addresses. These sequences were identified by looking for address cues ("box," "p.o.," "street," etc.) in conjunction with numerals; the immediately preceding text was then extracted, stripped of multiple spaces, punctuation, and copyright phrasing, and made into the candidate string. Candidate strings for the second subcategory were a product of searching for copyright–like statements. A passage was identified as copyright–like if it contained a strong copyright cue (the copyright symbol) or if it contained a weak copyright cue ("copyright," "(c)," or "[c]") combined with a number in the range 1900–2100. Text following such a cue was stripped and made into the candidate string.
Results
Out of a starting total of 50, three bibliographies were not available and another 13 were eliminated on the grounds of lack of personal author information. Three of those remaining had moved and were accessed at their new addresses. One more had been deleted from its original site following the compiler’s death, but was still available at a mirror site.
Twelve bibliographies ended up in the "long" class, with the number of referenced pages accessed ranging from 59 to 322. Nineteen were combined in the "short" class, with a total of 407 pages accessed.
The proportion of "rotten" links varied considerably, from a low of 1.8 percent to a high of 31.5 percent among the long bibliographies. The proportion was high for the short bibliographies, at 31.1 percent. By far the most common error types were socket errors (typically meaning the server could not be contacted) and "not found" errors for the specific files. Other error types encountered included URLs that returned a non–HTML format, connections closed gracefully, and access forbidden.
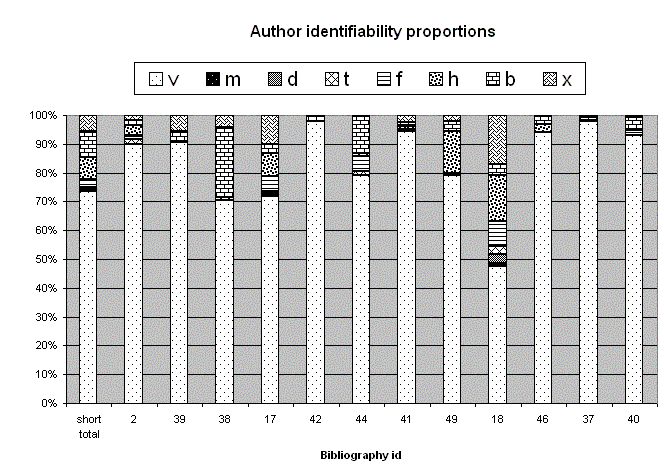
Proportions of the various author–match categories in the accessible pages are shown in Figure 1. It can be seen that, with the exception of bibliography 18, matching author names were generally to be found in the visible body text in at least 70 percent of pages referenced. Bibliography 18 stands out somewhat, with the highest proportions of author names derivable from inline objects or linked pages, or not readily determinable. The subject matter of this bibliography was Tai Chi, and it pointed almost entirely at sites of individual instructors and schools.
Figure 1: Author identifiability proportions.Metatags and title elements provided additional information on authorship in very few cases throughout.
The proportion of bad (b) links was generally quite low, below five percent for all but two of the long bibliographies, and below 10 percent for the short bibliographies. The two exceptions were bibliographies 38 and 44. Bibliography 38, on the novelist Richard Powers, with nearly 25 percent bad links, was relatively short, at 98 URLs, and included a number of references to newspaper articles. Bibliography 44, on cyberspace law, with only about 13 percent bad links, was somewhat longer, at 153 URLs; its bad links showed less of a pattern, but included a number to the Emory Law Journal site, some of which were bad. Both bibliographies also scored high (around 25 percent) on rotten links, but other bibliographies with high rotten–link counts did not show high proportions of bad links.
The indeterminate (x) category was represented most strongly in Bibliography 18. After that, it was most prominent in Bibliography 17, on sites related to semiotics, where some of the authors could, in fact, be verified by various truncations of the URLs.
The dividing line between the b and x categories was, at times, somewhat arbitrary. For example, a link for a specific journal article that instead called up the home page of the journal might be categorized as b if an editor or another author (say, of a featured article) was named on it, but as x if no such information was present.
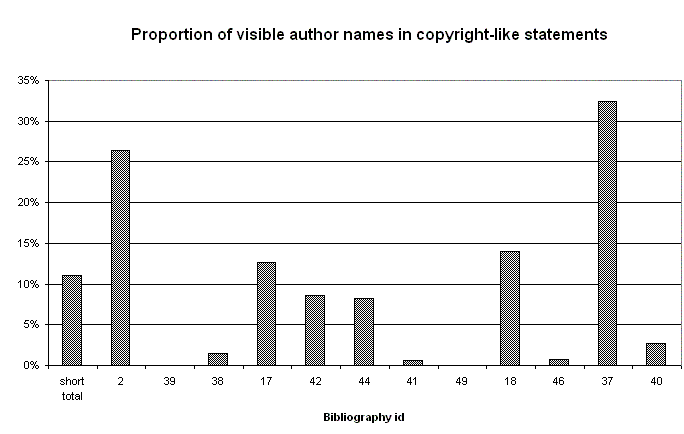
Author names were almost never identified from address–like passages in any of the pages. As is clear from Figure 2, the extent to which copyright–like statements yielded correct author names varied considerably from one bibliography to another. Standing out with particularly low rates are bibliographies 39, 38, 41, 49, 46, and 40, which represent a variety of topics. At the other extreme are bibliographies 2 and 37. Bibliography 2 gives links to bibliographies for anthropological research. The topic of Bibliography 37 is scholarly electronic publishing.
Figure 2: Proportion of visible author names in copyright–like statements.A few spelling errors were encountered (for example, "Egerston" for "Egertson" in short Bibliography 14 and "Benardo" for "Bernardo" in long Bibliography 17), but these were very rare. There were a few other odd cases where a match was allowed in spite of some imperfection; for example, where the bibliographer cited the author as "MCMULLIN, Finbarr (Barry) V." but the page itself said simply "Barry McMullin".
Discussion and conclusion
From the sample data, it appears that, in the great majority of cases, compilers of Web bibliographies take author information from the visible text of the pages that the bibliographies cover. Assuming that the compilers use graphical browsers, it would also be natural for them to look, where necessary, to inline objects such as images and frames, though this is apparently relatively rarely the case. There is little evidence of compilers’ making use of the title element or of metatags, and, indeed, the latter are more often than not missing in any case.
The labelling of links to useful related pages varies somewhat with subject matter, and different compilers may have different skills and patience in finding such links. Home page links are often hidden in graphics. Particular subject matter may call for looking for particular labels; for example, in the Tai Chi pages, an author could not infrequently be discovered by following links for instructional staff and picking the principal instructor of the school.
In a few instances treated as undetermined (x) in this study, authorship could, in fact, be verified by following a link to a file in some other format, such as a thesis available as a PDF file. Not systematically pursued were the possibilities inherent in trying truncated forms of the URL. While bibliography compilers may utilize this method rarely, they may, on the other hand, have come at the pages that they list from higher up the site hierarchy, where they may already have noted authorship information.
If authors are encouraged to contribute entries, author information may, in fact, come from sources that are not themselves on the Web. This is perhaps a more likely scenario in a commercial environment and might account, for example, for a number of the entries in the Tai Chi bibliography (Bibliography 18), though the compiler does not explicitly solicit new entries on the site.
Automatic extraction of copyright–like passages would presumably be of use for certain types of bibliographies, especially those that cite a good deal of self–published material. For many bibliographical tasks, however, it will doubtless prove of little or no value. Few copyright–like passages may, in fact, occur, or those that do may specify corporate bodies to which the authors have transferred rights.
Other automatic extraction methods might be of value for specific types of pages. The results of the present study do not suggest that looking for address–like passages would be helpful. On the other hand, in pages taking the form of scholarly papers or articles, author names are often given near the beginning of the text, typically centred.
Moreover, it was noted that some bibliographies tended to cite many items from the same Web–based journal. For example, Bibliography 37, on scholarly electronic publishing, cited numerous articles from D–Lib Magazine ( http://www.dlib.org/). Although article format was not uniform throughout this magazine, there appeared to be some common features of layout and content that might serve to mark author information for recognition.
About the author
Timothy C. Craven is a Professor in the Faculty of Information and Media Studies, The University of Western Ontario. He has published more than 60 articles in the areas of Web page description and computer–assisted indexing, abstracting, and thesaurus construction. He currently teaches courses in the graduate Library and Information Science program in Web design and architecture and in subject analysis and thesaurus construction.
E–mail: craven [at] uwo [dot] ca
References
T.C. Craven, 2003. "HTML tags as extraction cues for Web page description construction," Informing Science Journal, volume 6, pp. 1–12, at http://inform.nu/Articles/Vol6/v6p001-012.pdf, accessed 3 September 2004.
T.C. Craven, 2002. "What is the title of a Web page? A study of Webography practice," Information Research, volume 7, number 3, at http://InformationR.net/ir/7-3/paper130.html, accessed 3 September 2004.
A. Estivill and B. Urbano, 1997. "Cómo citar recursos electrónicos," at http://www.ub.es/biblio/citae-e.htm, accessed 3 September 2004.
T. Land, 1998. "Web extension to American Psychological Association style (WEAPAS) (Rev. 1.6)," at http://www.beadsland.com/weapas/, accessed 3 September 2004.
A. Savage, 2003. "TekMom's citation page," at http://www.tekmom.com/cite/, accessed 3 September 2004.
Editorial history
Paper received 7 September 2004; accepted 11 March 2005.


Copyright ©2005, First Monday
Copyright ©2005, Timothy C. Craven
Where does Web bibliographies' author information come from? by Timothy C. Craven
First Monday, volume 10, number 4 (April 2005),
URL: http://firstmonday.org/issues/issue10_4/craven/index.html