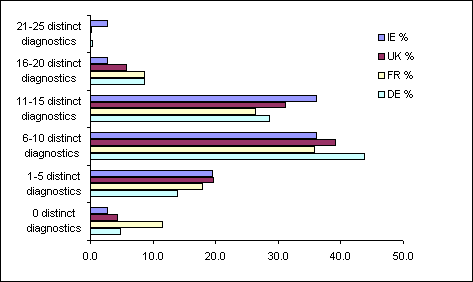A comparative assessment of Web accessibility and technical standards conformance in four EU states by Carmen Marincu and Barry McMullinThe Internet is playing a progressively more important part in our day–to–day life, through its power of making information universally available. People with disabilities have particular opportunities to benefit. Using the Internet in conjunction with dedicated assistive technologies, tasks that were very difficult if not impossible to achieve for people with various types of disability can now be made fully accessible — at least, in principle. However, in practice, many online resources and services are still poorly accessible to those with disability due to unsatisfactory Web content design.
Design of accessible Web content is codified in standards and guidelines of the World Wide Web Consortium (W3C). Conformance with W3C’s Web Content Accessibility Guidelines 1.0 (WCAG) (and/or similar, derivative guidelines) is now the subject of considerable activity, both legal and technical, in many different jurisdictions.
This paper presents results of a comparative survey of Web accessibility guidelines and HTML standards conformance for samples of Web sites drawn from Ireland, the United Kingdom, France and Germany. It also gives some recommendations on how to improve the accessibility level of Web content.
A particular conclusion of the study is that the general level of Web accessibility guidelines and HTML standards conformance in all of the samples studied is very poor; and that the pattern of failure is strikingly consistent in the four samples. Although considerable efforts are being made to promote Web accessibility for users with disabilities, this is certainly not yet manifesting itself in improving Web accessibility and HTML validity.
Contents
Introduction
Web sampling methodology
Web accessibility conformance
HTML technical standards conformance
Discussion
Conclusions
Introduction
The significant benefits brought to our society by the Internet are well–known. It reduces barriers of distance and time, and creates a society in which — in principle — anyone can have access to products and services all over the world at any time.
The people who could, arguably, benefit most dramatically from the Internet are those who, because of some disability, have restricted access to information and services in the physical world. Instead, they can have access to online versions of desired services, using dedicated assistive technologies (hardware or software which adapts a conventional system for use by a person with a disability). For example, a blind user can "read" — using a Braille display or speech synthesizer — the online version of the daily edition of her favorite newspaper or her bank statement. A user with restricted mobility can visit virtual stores from the comfort of his home. A student with cognitive disability can take her own time in understanding a lesson (Brewer, 2001). Depending on the specific disability the Internet user has, the assistive technologies will differ, from slow keys and an on–screen keyboard to Braille displays and screen readers (Brewer, 2001).
The typical practice of many Web content developers is to test Web site functionality only against a small number of "popular" Web browser platforms in "normal" configurations. Although the content might seem to be rendered correctly in these tests, this does not guarantee that it is designed correctly. By definition, users of specialized assistive technologies are not using "popular" platforms — or at least, not using them in "normal" configurations. Rather, they must depend on equipment tailored to their particular needs. As a result, it frequently happens that sites are poorly accessible, or completely inaccessible, to such users.
This situation would be quite different if sites were designed keeping in mind "write once, read everywhere," which can be achieved by designing Web content to meet appropriate guidelines and technical standards for interoperability. Provided both the server side and the client side conform to such guidelines and standards, the client platform can be tailored to individual user needs, and still interoperate effectively with all conforming servers.
An important source for accessible Web design resources is the W3C’s Web Accessibility Initiative. In May 1999, the Initiative published the Web Content Accessibility Guidelines (WCAG 1.0) (World Wide Web Consortium (W3C), 1999b). These Guidelines are now a reference point in achieving Web accessibility in many of the E.U.’s member states (European Commission, 2000a; 2000b). In Ireland, the Irish National Disability Authority (NDA) adopted WCAG 1.0 into the national "Guidelines for Web Accessibility" (Irish National Disability Authority, 2001). WCAG 1.0 is also a source for the "Guidelines for UK Governmental Web sites" (Office of the e–Envoy, 2002), published by the U.K. Cabinet Office in May 2002; the French "Government circular of 7 October 1999 concerning Internet sites by state public establishments and services" (French Government, 1999) and the German "Barrierefreie Informationstechnik–Verordnung" (German Government, 2002).
In the summer of 2002 a detailed accessibility study (McMullin, 2002) of Web sites operated by Irish organizations was conducted in the eAccess lab of the Research Institute for Networks and Computer Engineering at Dublin City University, Ireland. The main objective of the study was primarily to inform and promote Web accessibility policy in Ireland.
Prompted by efforts to promote Web accessibility in other EU member states, a similar but comparative study regarding the WCAG 1.0 conformance and HTML validity of a sample of Irish, U.K., French and German Web sites was conducted in May 2003. This paper presents the techniques used, the key results, and an analysis of the most common WCAG 1.0 checkpoints failures and HTML markup defects encountered in this study.
Web sampling methodology
Country–specific Web sampling
Selecting a representative sample of Web sites corresponding to a certain country is not a simple process. For the purpose of this survey it was considered that an open directory would provide a good basis. The information provided by the Open Directory Project ( ODP) is structured in a hierarchical tree of categories where each site is assigned to a specific category, representing the subject of the site as closely as possible.
The main ODP catalog is for U.S. and foreign sites in English, with descriptions also in English. The regional branch in the ODP hierarchy contains sites that provide information about a specific region, and/or when the site is directly relevant to a population within a specific geographic area in English. For example, Regional/Europe/Germany would list sites about Germany. All sites containing non–English language content are listed under the respective language under World. For example, World/Deutsch/Regional/Europa/Deutschland would list German language sites about Germany with descriptions in German.
Since the official language in Ireland and the U.K. is English, sites relevant to the population of the two countries are in English, leading to Web sites in the Regional/Europe/Ireland and Regional/Europe/United_Kingdom categories and their sub–categories. In the case of the French and the German Web samples, the sites relevant to the population of the two countries were considered to be the ones with French and German content, leading therefore to sites in the World/Français/Régional/Europe/France and World/Deutsch/Regional/Europa/Deutschland/ categories and their sub–categories.
Online resources for each category used in this study are shown in Table 1. It should be kept in mind that ODP content changes constantly so it is most likely that the content available at the date of sampling (February 2003) has altered.
Table 1: ODP categories considered in the sampling process.
Category Code URL Ireland IE http://dmoz.org/Regional/Europe/Ireland United Kingdom UK http://dmoz.org/Regional/Europe/United_Kingdom France FR http://dmoz.org/World/Français/Régional/Europe/France/ Germany DE http://dmoz.org/World/Deutsch/Regional/Europa/Deutschland
Considering the significant difference in the number of sites available in the four categories, it was decided that the number of sites in each sample would be a fixed fraction or percentage of the category total. On the basis of resources available for this study, this was set at five percent. The exact figures corresponding to each country sample can be seen in Table 2.
Table 2: Details on the ODP content considered in the sampling process.
Country Web sites available in ODP Web sites in sample IE 5,509 272 UK 114,044 5,702 FR 30,892 1,545 DE 84,860 4,250
These country samples were selected primarily from the following ODP sub–categories:
- Arts and entertainment
- Business and economy
- Education
- Government
- Health
- News and media
- Recreation and sports
- Science and the environment
- Society and culture
- Transportation
Web content retrieval
Web content for each site considered in the Web samples was retrieved and stored for conformance tests and further references.
Due to the fact that sites vary significantly in size and the type of media in which resources are offered, each site’s content was subject to sampling, using the Web content mirroring robot pavuk, on the following basis:
- Only HTML resources were captured (due to the specific nature of the study).
- The maximum link depth of the pages to be retrieved was set to three. This assumes that the most significant pages should be reasonably closely linked to the main ("home") page.
- The maximum amount of data captured from a single site was set to 225KB. It is considered that defects found within such a sample are likely to be repeated over the site’s content.
- A page is considered as part of a Web site only if it uses the same URL "prefix" as the "root" or "home" page of the site.
Table 3 presents statistics regarding the mirroring process. It was considered that, in order for the survey’s results to be reasonably representative of a site, each site content sample should have at least three Web pages and at least 100KB of data. Less than half of the number of Web sites considered in the four Web samples passed this test, qualifying for the conformance tests, with small differences between the four Web samples, percentages varying from 38 percent (German sample) to 48 percent (French sample).
Although the four Web samples differ considerably regarding the number of sites considered, the statistics are remarkably similar. Still, some small differences can be noticed.
The French sample had the largest percentage (almost double compared to the Irish sample) of sites for which no data could be retrieved, showing that it was a problem connecting to the Web site (ODP data obsolete, Web server not found, network disruption, server downtime). But the situation changes regarding the percentage of sites for which only the main page ("home") was retrieved, with the highest percentage in the Irish Web sample.This could show that there were problems accessing Web pages that were linked from the main page (for example, the main page links to other pages with links created using scripts — Multimedia Flash or Javascript).
Table 3: Details regarding the mirroring process.
IE UK FR DE Sites in sample 272 5,702 1,545 4,250 Total pages retrieved 3,319 67,598 22,319 58,278 Total data retrieved (MB) 28.61 552 166.86 377.36 Sites with no data (% of total) 3.3 4.5 6.9 3.5 Sites with only one page (% of total) 33.5 29.3 21.2 27.3 Sites qualified for tests 123 2,380 747 1,627 Sites qualified for tests (% of total) 45.2 41.7 48.4 38.5 Pages qualified for tests (% of total) 68.9 67.8 73.1 65.3
The results obtained in the mirroring process could be considered as crude "accessibility indicators" since one definition of an accessible Web site is actually being able to retrieve content from it.
Web accessibility conformance
Methodology
The key in designing accessible Web sites is to facilitate — rather than obstruct — access by groups of people with disabilities. The basic requirements have been internationally codified in the Web Content Accessibility Guidelines (WCAG) 1.0, published in 1999 by the World Wide Web Consortium (World Wide Web Consortium (W3C), 1999b).
WCAG 1.0 consists of 14 separate guidelines, each of which has an associated set of one or more individual checkpoints.There are a total of 65 checkpoints which are classified into three priority levels (1–3):
- [Priority 1] A Web content developer must satisfy this checkpoint. Otherwise, one or more groups will find it impossible to access information in the document. Satisfying this checkpoint is a basic requirement for some groups to be able to use Web documents.
- [Priority 2] A Web content developer should satisfy this checkpoint. Otherwise, one or more groups will find it difficult to access information in the document. Satisfying this checkpoint will remove significant barriers to accessing Web documents.
- [Priority 3] A Web content developer may address this checkpoint. Otherwise, one or more groups will find it somewhat difficult to access information in the document. Satisfying this checkpoint will improve access to Web documents.
Based on these priority levels, three levels of conformance to the WCAG 1.0 can be achieved:
- WCAG–A: All priority 1 checkpoints are satisfied. This is a minimum standard which a site must meet to be considered accessible for any significant disability groups.
- WCAG–AA: All priority 1 and 2 checkpoints are satisfied. This is a "professional practice" standard, which a site should meet to be accessible to a broad range of disability groups.
- WCAG–AAA: All checkpoints (at all priorities) are satisfied. This is a "gold standard" of maximum accessibility which some sites may choose to aim for — for example, sites with a particular remit to serve disability communities.
There are a number of software products now available to carry out automated assessments against (subsets of) the WCAG 1.0 guidelines. These have a variety of strengths and weaknesses, but are functionally very similar (by definition, as they are largely driven by the WCAG 1.0 guidelines themselves). For the purposes of this study we chose to adopt one of the more widely deployed of these products, Bobby Worldwide (Core v4.0), originally developed by the Center for Applied Special Technology (CAST), and now distributed and maintained by Watchfire Corporation. The use of Bobby in this study does not imply an endorsement by the study’s authors of this particular product or its producer or provider.
Bobby implements 91 distinct tests or diagnostics, each of which maps onto a specific WCAG 1.0 checkpoint. A number of Bobby diagnostics map onto (different aspects of) the same WCAG 1.0 checkpoint.
The Bobby diagnostics are classified into a number of different "support" categories, as follows:
- Full: Bobby automatically detects violations.
- Partial/Partial Once: Bobby performs some partial automatic checking, but this requires manual verification.
- Ask Once/Summary Ask Once: Bobby does not do any checking, the diagnostic is presented only as a reminder to perform manual checking.
For all categories other than Full, further evaluation would be required by a human assessor to determine WCAG 1.0 conformance. Accordingly, in the work presented here, Bobby is restricted to implementing just those diagnostics with Full support. There are 25 such diagnostics, which map onto (aspects of) 20 distinct WCAG 1.0 checkpoints, including some at all three priority levels, as follows (in order of priority, then WCAG 1.0 checkpoint):
Table 4: Mapping the Bobby diagnostics onto WCAG checkpoints.
Bobby ID Description WCAG priority WCAG checkpoint g9 Provide alternative text for all images 1 1.1 g21 Provide alternative text for each APPLET 1 1.1 g20 Provide alternative content for each object 1 1.1 g10 Provide alternative text for all image–type buttons in forms 1 1.1 g240 Provide alternative text for all image map hot–spots (AREAs) 1 1.1 g38 Each FRAME must reference an HTML file 1 6.2 g39 Give each frame a title 1 12.1 g271 Use a public text identifier in a DOC–TYPE statement 2 3.2 g104 Use relative sizing and positioning (percent values) rather than absolute (pixels) 2 3.2 g2 Nest headings properly 2 3.5 g37 Provide a NOFRAMES section when using FRAMEs 2 6.5 g4 Avoid blinking text created with the BLINK element 2 7.2 g5 Avoid scrolling text created with the MARQUEE element 2 7.3 g33 Do not cause a page to refresh automatically 2 7.4 g254 Do not cause a page to redirect to a new URL 2 7.5 g269 Make sure event handlers do not require use of a mouse 2 9.3 g41 Explicitly associate form controls and their labels with the LABEL element 2 12.4 g34 Create link phrases that make sense when read out of context 2 13.1 g265 Do not use the same link phrase more than once when the links point to different URLs 2 13.1 g273 Include a document TITLE 2 13.2 g14 Client side image map contains a link not presented elsewhere on the page 3 1.5 g125 Identify the language of the text 3 4.3 g31 Provide a summary for tables 3 5.5 g109 Include default, place–holding characters in edit boxes and text areas 3 10.4 g35 Separate adjacent links with more than white space 3 10.5
Each one of the Bobby diagnostics are explained in the Bobby Report Explanation File.
Given that evaluation is limited to only a subset of the WCAG 1.0 guidelines, and is applied to only a sample of the content of any given site, it cannot determine that any site positively satisfies the guidelines. However, failure on any of these tests definitively demonstrates failure against the guidelines.
Bobby did not function properly for a number of Web sites. These failures were manifested in two ways:
- Bobby terminated with an abnormal status code: these failures could be triggered by invalid HTML coding on the server (for example the use of invalid characters, such as spaces, in URLs). It is also possible that some of these failures actually indicate defects in Bobby itself. It should be noted that Bobby is not distributed in source form; this makes further investigation in cases such as this problematic.
- Bobby appeared to "lock up": that is, execution was continuing for a much longer period that normal and appeared as if it would continue indefinitely. Again, these failures may be symptomatic of either invalid HTML or defects in Bobby itself. The pragmatic resolution was to terminate Bobby forcibly after a fixed timeout (set at a multiple of three of the maximum time otherwise recorded for successful completion in preliminary testing).
In general, when analyzing the results, it was considered that if one diagnostic is triggered in at least one Web page of a site sample, the site should be counted in statistics regarding the specific diagnostic. It could be argued that this interpretation will make the overall results look very strict. However, only a relatively small Web content sample was taken from each site. We assumed that the technologies and implementations used across a site are similar, so, if the reported defect appeared at least once, it is quite probable that it will appear again elsewhere on the site.
Table 5: Statistics regarding Bobby runs.
IE UK FR DE Sites considered 123 2,380 747 1,627 Sites with Bobby abnormally terminated (% of total) 2.4 5.8 8.4 6.3 Sites where Bobby "locked up" (% of total) 4.9 3.9 6 4.7 Sites with Bobby successfully terminated 92.7 90.4 85.5 88.9
Key results
- 94.0 percent of the Irish sites, 94.5 percent of the U.K. sites, 95.6 percent of the German sites and 98.6 percent of the French sites failed Bobby at the minimal accessibility level (WCAG–A)
- 99 percent of U.K. sites and 100 percent of the Irish, French and German sites failed Bobby at the professional accessibility level (WCAG–AA)
- All (100 percent) of the sites failed Bobby at the maximum accessibility level (WCAG–AAA)
Representative Priority 1 defects
As explained earlier, all of the WCAG 1.0 Priority 1 checkpoints must be satisfied in order to accommodate use of a Web site by any significant disability groups.
The incidence of Priority 1 defects encountered by Bobby are listed in Table 6. The most common of these defects are then discussed in more detail.
Table 6: Priority 1 defects.
ID Description IE
(% of total)UK
(% of total)FR
(% of total)DE
(% of total)Overall
(% of total)g9 Provide alternative text for all images 93 92.5 97.9 92.5 93.3 g39 Give each frame a title 21.9 26.9 41.2 50.9 36.8 g38 Each FRAME must reference an HTML file 21.1 25.5 39.3 50.4 35.7 g240 Provide alternative text for all image map hot–spots (AREAs) 21.9 19.9 37.7 18.5 22.1 g10 Provide alternative text for all image–type buttons in forms 7.9 8.5 12.8 8.9 9.3 g21 Provide alternative text for each APPLET 8.8 7.4 7.0 7.5 7.4 g20 Provide alternative content for each object 0.0 0.2 0.5 0.2 0.3
Provide alternative text
- g9: Provide alternative text for all images
- g240: Provide alternative text for all image map hot–spots (AREAs)
- g10: Provide alternative text for all image–type buttons in forms
The Web is, as a whole, a "graphical" environment, which has to be translated into an alternative representation when used with non–graphical browsers and technologies, such as screen readers and braille displays. This issue is specifically addressed in Web accessibility by the general recommendation of "providing alternative content."
HTML makes a provision for attaching "alternative" — or ALT — text to images. This "alternative" text is generally hidden if the image is displayed or visible to the user but it can be picked up and spoken by a speech synthesizer, or other alternative output device, for a blind or visually impaired user. The extra design effort involved is minimal, but dramatically improves the usability of the site for certain users.
As can be seen in Table 6, the incidence of images without alternative text is large in all samples, but even more noticeable in the French Web sample. Note that Bobby can check only that some alternative text is provided with each image. It cannot verify that the alternative text is appropriate (that is, that it effectively represents, or is an appropriate functional alternative to, the image).
Frames give rise to a wide variety of problems both for general usability and specifically for accessibility by users with disabilities. The functionality provided by frames can be achieved with alternative HTML technologies, properly engineered and with good browser support and accessibility. It is our view that frames should be regarded as obsolete technology, and should be avoided wherever possible. However, as long as frames are still in use, then it is essential that the special accessibility issues which they raise are adequately addressed (Engelfriet, 1997).
The particular diagnostic discussed here addresses the need for each HTML frame element to have an associated, textual, title attribute, which will be displayed in browsers with no frames support. This serves to provide critical orientating information about the frame organization for users who cannot directly perceive the visual layout or configuration of frames.
The percentage of sites triggering this diagnostic is quite similar in the Irish and U.K. samples (around 25 percent) and substantially higher in the French and the German Web samples (41.2 percent and 50.9 percent).
It might be assumed that frames are better implemented in Irish and U.K. sites than on German and French ones, but this is not necessarily true. It may mean simply that the incidence of sites using frames is double in the French and the German Web samples than in the Irish or U.K. samples. More refined testing and analysis would be necessary to distinguish these two cases.
When frames are pointing directly to content with intrinsic accessibility barriers (such as images), an alternative content cannot be provided. The Web content should, instead, be embedded in an HTML file so that appropriate alternative content can be included too. Again, the incidence of sites triggering this diagnostic is noticeably higher in the German and French samples.
The APPLET HTML element normally introduces Java applets — programs that are automatically downloaded and run on a client’s machine. Applets raise potential problems for accessibility, especially when they implement navigation or when they add presentation to content — such as moving text. Alternative content (that would implement the same functionality) should be provided, since it is needed to provide the same functionality for a browser not capable of handling Java code, or when the user has disabled the browser’s capability to interpret Java.
The incidence of sites that triggered this diagnostic is not that high, although this may mainly reflect the raw incidence of APPLET use on the Web (as opposed to the relative proportion of sites using applets which specifically violate APPLET–related accessibility guidelines). In any case, it should be kept in mind that even one applet wrongly implemented can create serious accessibility problems for the whole site since it might obstruct navigation from the home page or hide key information from a user’s browser which cannot handle Java.
Representative Priority 2 defects
If a Web site satisfies not only all the WCAG 1.0 Priority 1 checkpoints but also the WCAG 1.0 Priority 2 checkpoints, its content should be accessible to a broad range of disability groups. The site can claim WCAG–AA level conformance.
The incidence of Priority 2 defects encountered by Bobby are listed in Table 7. The most common of these are then discussed in more detail.
Table 7: Priority 2 defects.
ID Description IE
(% of total)UK
(% of total)FR
(% of total)DE
(% of total)Overall
(% of total)g104 Use relative sizing and positioning (percent values) rather than absolute (pixels) 98.3 98.2 98.1 98.9 98.4 g271 Use a public text identifier in a DOCTYPE statement 87.7 82.5 94.2 76.2 82.2 g265 Do not use the same link phrase more than once when the links point to different URLs 79.0 70.4 68.2 71.0 70.5 g269 Make sure event handlers do not require use of a mouse 74.6 65.3 72.6 63.1 65.9 g41 Explicitly associate form controls and their labels with the LABEL element 62.3 63.6 64.5 57.7 61.7 g34 Create link phrases that make sense when read out of context 36.0 39.1 2.4 1.2 21.0 g2 Nest headings properly 14.9 13.9 8.8 10.6 12.0 g273 Include a document TITLE 15.8 8.9 10.6 12.8 10.6 g5 Avoid scrolling text created with the MARQUEE element 7.9 8.3 10.8 8.3 8.6 g37 Provide a NOFRAMES section when using FRAMEs 2.6 2.1 4.7 15.3 6.9 g4 Avoid blinking text created with the BLINK element 1.8 2.6 5.8 5.5 4.0 g254 Do not cause a page to redirect to a new URL 3.5 2.9 3.0 5.4 3.8 g33 Do not cause a page to refresh automatically 0.9 1.6 1.4 2.4 1.8
The visual position and size of various elements can be specified in HTML — for example, font size for text, widths of tables, or individual table cells. In general, HTML allows such positions and sizes to be specified in either "relative" units (scaled according to some norm which the user’s browser already has) or "absolute" units (not scalable). The effect of using relative units is that the browser can very flexibly adjust the visual presentation according to available visual space on a user’s device, as well as user’s preferences and capabilities.
The overall incidence of this defect type in the Web samples studied is 98 percent. This is significant since it is a defect that can be easily corrected with important consequences for the large category of intermediate visually impaired users. Users with intermediate visual disability are not blind, but require some facilitation, particularly in the use of larger font sizes. This is already a large category of disability; furthermore, as its incidence is significantly age–related, and the relative population of seniors is growing, its importance is, if anything, increasing (European Commission, 2001).
This defect type also illustrates the general concept of universal design — designing to include the widest possible variety of users. In the current case, by designing a site that uses only relative positioning and sizes, it can automatically adapt to changing user technologies and needs — such as the growing use of Internet–enabled televisions, personal digital assistants (PDAs), etc., which have a much wider variety of visual display capabilities than standard computer terminals.
Properly formatted HTML pages should conform to a set of strict technical specifications, to ensure compatibility between Web sites and Web browsers (Zeldman, 2001). This is true as a general principle, but is especially crucial to ensuring compatibility with a wide variety of special–purpose Web browsers and assistive technologies that are necessary to address the diverse needs of users with disabilities.
In order for a Web browser to render a HTML page as intended by its author, it needs to know how the document is constructed, according to which technical standard. A "Document Type Definition" (DTD) specifies the elements (and their attributes) that can be used according to a particular technical standard, and what is their intended purpose and structure. The particular DTD — according to which a Web page is constructed — is specified using DOCTYPE construction. When this information is mis–constructed or missing, the Web browser is challenged to properly render an unknown markup structure.
In most cases, assistive technology is an interface that a user with a disability invokes to browse the Web. The behavior of this assistive technology depends on output provided by conventional Web browsers. If a conventional Web browser is challenged in rendering Web content, the challenge will be passed along. Hence, some Web content may perform in unpredictable ways and may be unusable.
The highest incidence of sites that triggered this Bobby diagnostic is in the French Web sample (94 percent) whilst the smallest is in the German sample (76 percent).
Bobby thus gives an indication of the remarkably high incidence of sites that do not have any DOCTYPE information specified. However, if DOCTYPE information is specified, Bobby cannot check whether it is properly constructed; additional analysis is required. As will be shown below, when this analysis is conducted, the incidence of Web sites that had an absent or mis–constructed DOCTYPE statement is significantly larger.
A "link phrase" is the (usually short) fragment of text in a Web page that is hypertext–linked to another Web resource. For users of visual browsers, link phrases are normally visually highlighted in some way, perhaps by color or underlining. "Clicking" within the link phrase causes the browser to load a linked resource. Users can generally scan Web pages visually very quickly to pick out link phrases and can easily read surrounding text if they need more context to understand the logic of a particular link.
For users of non–visual browsers (say using screen readers, or braille output devices) "scanning" a Web page is generally slower and more cumbersome. One common technique to aid scanning in such cases is to simply skip from link to link. In these cases, only the link phrases are directly rendered to the user, and access to surrounding text (for additional context) will be relatively slow (i.e., it will undermine the very utility of this form of scanning).
Access for such users can be significantly improved if a little care is taken in the selection of link phrases. Conversely, poor selection of link phrases can create a significant, and generally quite unnecessary, obstacle to users. More specifically, if the same link phrase is used multiple times, in the same page, but linked to different resources, this difference will not be apparent to a user who is scanning only link phrases.
Various HTML coding techniques (commonly using client side scripting) rely on certain kinds of interaction with the user. However, depending on their individual capabilities and preferences, users may adopt a wide variety of interaction devices. In particular, the use of a conventional mouse, or even of some adapted form of screen–pointing device, may be difficult or impossible for some users. Thus, if a page is coded in such a way that certain functionality or features can be accessed only by using a particular form of interface device — such as a mouse — then functionality will be unavailable to users with certain disabilities. Worse still, such users may not even be aware that such functionalities exist.
In the visual presentation of a Web page, there can often be important relationships between different components of the page which are expressed only implicitly by their juxtaposition in the display. A common example arises in the case of HTML–based forms. A form generally consists of information explaining to the user what has to be filled in, interspersed with "form controls" — text entry boxes, radio buttons, drop down lists — which the user can interact with. Typically, the relative positions in the visual display make it reasonably easy for a visual user to identify which text is associated with which control.
However: for users who are unable to use a visual display in the manner assumed by the site designer (due to visual impairment) it will generally not be possible to directly perceive these implicit, but critical, relationships. To address this, HTML provides facilities whereby a particular form control can be explicitly marked as associated with a particular text (the corresponding "label"). This coding can then be used by a suitably configured browser to help a user with a disability to recognize correct relationships. Furthermore, coding these explicit relationships can improve general form usability. For example, the browser can associate clicks on a label as intending to activate a form control, thus providing a larger target for selection with a pointer. This may be particularly helpful to users with motor impairment which limits fine pointer manipulation, but will generally be of benefit to all users, illustrating the applicability of universal design.
When link phrases like "click here" or "more" are used, no information regarding the document referenced is provided to users of non–visual browsers, who, in some cases can "scan" through a list of links contained in a document ("click here to do what?").
The results of the survey regarding this diagnostic are quite interesting. The figures show a high incidence of incorrect link phrases in the Irish sample (34 percent) and the U.K. sample (39 percent), whereas the incidence is considerably smaller in the German sample (1.2 percent) and the French sample (2.4 percent).
Does this mean that the sites in the French and German samples provide properly formed link phrases? Or is this difference due to a limitation in Bobby’s capability of "matching" only link phrases in English while the German and French equivalent of "click here" ("Cliquez ici" and "Click hier") are ignored? Ideally this could be resolved through Bobby’s documentation or examination of its source code. However, no clarification was found in the documentation. As Bobby is not available in source form, source code inspection was not possible. Some controlled tests of this specific point were carried out. The results were consistent with the second conjecture above: it appears that, indeed, in triggering this diagnostic, Bobby only matches some pre–programmed repertoire of English language phrases (even when correct information as to the natural language of the page is present).
One of the core principles in designing accessible Web content is separating structure from presentation — in order to facilitate, as much as possible, adaptation of presentation to suit the particular needs and capabilities of individual users. That means that the HTML elements should be used always and only for their intended structural purpose, and not for assumed presentational "side effects" — which are not consistent or reliable anyway.
Users of assistive technologies often use headings as a mean of navigation within a single Web page, since scanning the contents of an entire page can be difficult and time–consuming (for example when using a non–visual browser). Thus, it is important not only that HTML heading elements are used (and not implied, for example, via font effects), but also that they are nested properly, in order to make explicit the structure of the page.
- g273: Include a document TITLE
The TITLE element should provide a brief summary or indication of the content of a page. This information is usually displayed in the title bar of the window rendering the Web content, or otherwise made available on user request. It is also used in creating bookmarks. It provides important orientation information, which is useful to all users (universal design) but particularly useful to users with a variety of disabilities.
The first problem with the MARQUEE element is that it is not recognized by any HTML technical standard, so Web content using this element will fail the WCAG 1.0 Checkpoint 3.2: "Create documents that validate to published formal grammars." The importance of using technical standards conformant Web content is outlined below.
The second problem is that the scrolling text effect created with MARQUEE can cause problem for a variety of individuals with different disabilities. There are some screen readers that can’t handle scrolling text. People with cognitive disabilities can’t comprehend the text at the speed of the scrolling, or the motion is distracting them from other, non–scrolling text.
The NOFRAMES HTML element introduces alternative content for frames, content to be rendered when the Web browser does not support frames. As noted earlier, the difference between the percentage of sites that triggered this diagnostic in the Irish and U.K. sample and the German and French samples may be explained by a different proportion of sites actually using FRAMES. This proportion should be reflected in the number of sites that use the NOFRAMES element.
Again, the first problem with the BLINK element is that it is not recognized by any HTML technical standard.
The second problem is that the blinking text effect created with BLINK can cause malfunctions with some screen readers — which can get stuck and repeat the same text over and over. Some individuals with dyslexia can be affected by blinking text and those with with low vision can have problems reading it. Others with cognitive disabilities may be distracted from the actual text by the blinking effect.
The actual WCAG 1.0 checkpoint referred by this diagnostic is "do not use markup to redirect pages automatically. Instead, configure the server to perform redirects." When the server is configured to handle a page redirection, the process is transparent to the user and causes no problems. But when the redirection is implemented on the client side — using markup — it can disorient the user. The user may be surprised and his screen reader may be interrupted.
Content developers sometimes create pages that automatically refresh (change) periodically their content. The user should be allowed to decide how long she wants to browse the content of a page. If the content is automatically refreshed too soon, she might not have read or understand the content yet and in some cases become confused, not knowing that the content changed.
Conclusions of the WCAG 1.0 conformance tests
The WCAG 1.0 conformance level of the Web sites studied is clearly alarmingly low.
The highest percentage of sites that failed the selected Bobby tests at the minimum standard of accessibility was in the French sample at 98.6 percent. The lowest percentage was in the Irish sample, but this was still at a level of 94.0 percent, which can hardly be considered as substantially better. Note also that, as explained earlier, Bobby can automatically report only certain limited checkpoint violations. Thus, it should not be inferred, even for the Irish sample, that the balance of sites (6.0 percent) are necessarily conformant with WCAG–A. Rather it is likely that many, if not all, of these remaining sites may fail other WCAG priority 1 checkpoints that could not be automatically tested by Bobby.
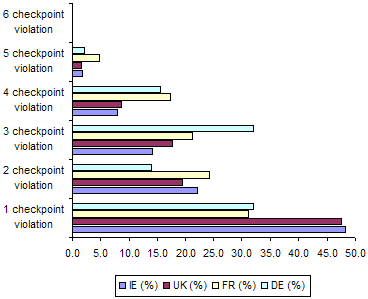
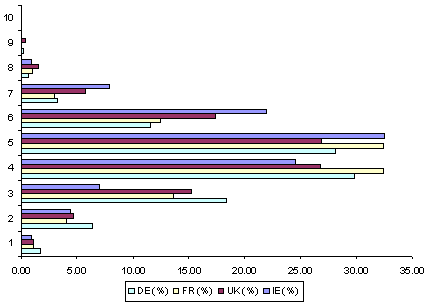
The frequency distribution of distinct bobby diagnostics, at WCAG Priority 1, is presented in Table 8. This same data is presented in chart form in Figure 1. Similarly, the frequency distribution of distinct Bobby diagnostics, at WCAG Priority 2, is presented in Table 9, and as a chart in Figure 2. As will be seen from this data, most sites in the four samples triggered between 1 and 3 distinct WCAG 1.0 Priority 1 Bobby diagnostics and between 4 and 6 distinct WCAG 1.0 Priority 2 Bobby diagnostics. Thus, particularly at the WCAG–AA conformance level, the failures were generally not due to violation of any single isolated checkpoint, but to a pattern of violation of multiple checkpoints.
Table 8: Frequency of WCAG 1.0 Priority 1 Bobby diagnostic violations.
Number of distinct diagnostics IE
(% of total)UK
(% of total)FR
(% of total)DE
(% of total)1 48.2 47.5 31.1 32.0 2 21.9 19.3 24.3 13.9 3 14.0 17.5 21.1 32.1 4 7.9 8.6 17.2 15.2 5 1.8 1.5 4.7 2.3 6 0.0 0.0 0.2 0.1
Figure 1: Frequency chart of WCAG 1.0 Priority 1 Bobby diagnostic violations..
Table 9: Frequency of WCAG 1.0 Priority 2 Bobby diagnostic violations.
Number of distinct diagnostics IE
(% of total)UK
(% of total)FR
(% of total)DE
(% of total)1 0.9 1.0 1.1 1.7 2 4.4 4.6 4.1 6.4 3 7.0 15.3 13.6 18.4 4 24.6 26.8 32.4 29.9 5 32.5 26.8 32.4 28.1 6 21.9 17.4 12.5 1.6 7 7.9 5.8 3.0 3.3 8 0.9 1.6 0.9 0.6 9 0.0 0.4 0.0 0.1
Figure 2: Frequency chart of WCAG 1.0 Priority 2 Bobby diagnostic violations..
HTML technical standards conformance
A major step in achieving Web accessibility is to use markup for its intended purpose when designing Web content, and, in particular, conforming to relevant technical standards. WCAG 1.0 Checkpoint 3.2 (Priority 2) expresses this thus:
"Create documents that validate to published formal grammars."An HTML page is properly built when its markup conforms to a standard technical specification. Each standard is specified by a Document Type Definition (DTD) document which contains descriptions of the entities, elements and attributes that can be part of an HTML document, and how they can be interrelated. Because most of the existing Web browsers are able to render — to at least some extent — Web pages which don’t conform to a DTD, many of the failures in the HTML code can pass unnoticed by most users. But such code defects can be a real impediment in access for users with disabilities, helped by special–purpose Web browsers and dedicated assistive technologies. They also complicate, and therefore inhibit, ongoing development of such niche technologies.
Methodology
There are different tools that can be used in order to validate HTML code against its description in the corresponding DTD. The output is usually a list of problems encountered (diagnostics) with suggestions to fix them. A list of such tools can be seen on the Web Accessibility Initiative’s (WAI) Web site.
The tool chosen for the HTML conformance tests in this study is onsgmls. onsgmls is a parser and validator of SGML/XML files (HTML and XHTML), part of the OpenSP collection of SGML/XML processing tools.
onsgmls implements 438 individual diagnostics which can be triggered when an element or attribute in the HTML content is not used according to its specification in the HTML page’s DTD.
Each diagnostic is assigned a "severity level" as follows:
- error (318 distinct diagnostics): triggered when there is a clear non–conformance between the HTML content and its specification in the DTD.
- warning (94 distinct diagnostics): triggered when the validator encounters the use of an HTML entity, element or attribute, which is technically valid but unlikely to be intended in normal markup.
- quantity error (26 distinct diagnostics): triggered when a document characteristic is not in conformance with a quantitative limit considered by onsgmls reasonable for HTML documents.
The study presented in this paper will discuss only the onsgmls diagnostics with an "error" severity level, showing clear non–conformance between the HTML content and its specification in the DTD.
As already explained, the validation process involves comparing the use of each component in an HTML document with its specification in the DTD of the HTML standard used in the document. Thus, in order to generate consistent validation results, onsgmls needs a properly specified DTD, normally identified via a DOCTYPE declaration in the beginning of the HTML page (World Wide Web Consortium (W3C), 1999a, Section 7.2).
Accordingly, if the DOCTYPE declaration is missing or unrecognized, the Web page will immediately and automatically fail the validation test. It would be possible to configure onsgmls to assume a default DTD against which the document could be tested further in such cases. However, this approach was not adopted in this study as it would seriously confound or distort the results otherwise obtained (since we could not then distinguish between defects which were due to genuinely incorrect markup in a target document and apparent defects due only to a mismatch between the document and the arbitrarily selected default DTD).
In summary, it was found that over 82 percent of all pages retrieved had missing or otherwise unusable document type information. Over 98 percent of all sites considered had at least one such page. This is a striking result in itself. However, it also makes it difficult to extract any further, more detailed information since, in the absence of a usable DOCTYPE declaration, no further validation is possible.
Recall that, in the analysis of the Bobby (Web accessibility guidelines) conformance test results, it was considered that if a given diagnostic is triggered in at least one page of a site, the site should be counted in statistics regarding that diagnostic. The same general approach was adopted in the analysis of the HTML technical standards conformance test results. However, given the extremely high proportion of sites having at least one page without a usable DOCTYPE, this was subject to further refinement. For the purposes of presenting and ranking the detailed HTML validation results, the site samples were reduced by:
- Eliminating all pages which lacked usable DOCTYPE declarations.
- Eliminating all sites which now failed the original sampling criteria (i.e., at least 100KB of data distributed across at least three distinct pages).
The effect of this is discussed further below, and summarized in Table 10.
Key results
- Only four U.K. sites (less than 0.2 percent) and six German sites (less than 0.4 percent) had completely valid HTML markup. No Irish or French sites had completely valid markup. By "completely valid" we mean that all of the pages retrieved in the original content mirroring process had a usable DOCTYPE declaration and had no HTML markup defects detected by onsgmls. The percentages here are relative to the numbers of sites initially retrieved (before filtering for usable DOCTYPE declarations).
- Additionally, even after reducing the samples on the basis of usable DOCTYPE information, just one Irish site (3 percent), 29 U.K. sites (4 percent), 16 French sites (4 percent) and 29 German sites (2 percent) had valid HTML markup in the remaining pages, as determined by onsgmls. The percentage figures here are relative to the reduced site samples (after filtering for usable DOCTYPE declarations).
Representative defects
As already indicated, for the sample as a whole, by far the most common HTML markup defect was a missing or unusable DOCTYPE declaration, as summarized in Table 10.
A correctly specified document type declaration is obviously crucial in the validation process of a Web page. But more importantly, when the document type information is correctly specified in an HTML document, the Web browser knows how the document is constructed and its content and functionality can therefore be rendered consistently and as intended. An HTML document without a usable DTD is a challenge to Web browsers because the markup structure is unpredictable.
Starting with Internet Explorer 5.0 for the Apple Macintosh (released in March 2000) there is now a trend for mainstream browsers to more strictly implement standards–conformant behavior. This means that the way that the Web content is rendered by the browser depends on the precise document type which is declared — using a correctly structured DOCTYPE declaration. For backwards compatibility, a feature called "DOCTYPE switching" is sometimes implemented. In this case, even when a correctly structured DOCTYPE declaration is present in the Web page, the content may be rendered either according to the HTML standard specified — "standards mode" — or in a backwards compatibility way — "quirks mode" — in which the behavior is unpredictable for an arbitrary browser and operating system. In addition, the "DOCTYPE switch" feature is not guaranteed to be kept for long. It seems likely that future browser implementations will progressively drop it in favor of the "standards mode" only rendering behavior.
Table 10: Incidence of missing or unusable DOCTYPE declaration.
IE UK FR DE Pages processed by onsgmls 2,288 45,857 16,312 38,062 Pages with missing or unusable DOCTYPE 1,774 (77.5%) 35,529 (77.5%) 14,264 (87.4%) 26,950 (70.8%) Sites processed by onsgmls 123 2,380 747 1,636 Sites with missing or unusable DOCTYPE on at least one page 121 (98.4%) 2,345 (98.5%) 746 (99.9%) 1,584 (96.8%) Sites considered for further analysis (having at least 3 pages/100KB with usable DOCTYPE) 36 (29.3%) 663 (27.9%) 140 (18.7%) 603 (36.9%)
As mentioned before, in the absence of a usable DOCTYPE declaration, the validation results are not consistent or meaningful, and the Web pages that triggered this diagnostic were therefore removed from further, more detailed analysis. Given this, and to ensure that the results generated by a Web site are in some sense representative, each site was required to have to have at least three pages with a usable DOCTYPE declaration, including at least 100KB of data, in order to qualify for more detailed evaluation. The number and the percentage of sites — from the ones considered by onsgmls in the first stage — are shown in Table 10.
Due to the specific hierarchical structure of HTML documents, defects in markup will usually influence the validation process of elements within the element with incorrect markup. In the end, the diagnostics triggered by onsgmls during a validation process are closely interrelated, such that if one defect is repaired and the validation process repeated, the validation results can be significantly different.
The HTML conformance tests triggered 35 distinct diagnostics in the Irish sample, 48 distinct diagnostics in the U.K. sample, 45 distinct diagnostics in the French sample and 52 distinct diagnostics in the German sample. Although the distinct diagnostics triggered by the four samples therefore varies, the most common ten diagnostics (as measured by the proportion of sites triggering them at least once) are the same for all the four samples. Further, the ranking of these by relative site incidence varies with an average of just three places between the four samples, with the most common three diagnostics having the same rank ordering in all four samples. There is therefore considerable underlying consistency in the pattern of defects across all the samples.
The ten most common markup defects are listed in Table 11 (starting with the most frequent). Each of these will now be discussed in more detail.
Table 11: Representative markup defects.
Note that this table is based on the number of sites triggering each diagnostic at least once. Percentages are relative to the reduced site samples (after filtering for usable DOCTYPE declarations, per Table 10).
Diagnostic IE
(%)UK
(%)FR
(%)DE
(%)Overall
(%)Undefined attribute 92 91 83 91 89 Element not allowed by document type 81 77 72 80 76 End tag for not opened element 75 74 60 69 69 Required attribute not specified 53 75 73 77 69 Missing required end tag 56 53 46 54 52 Non–SGML character number 56 41 47 44 47 General entity not defined and no default entity 47 49 41 45 45 Attribute value must be literal 44 38 39 35 39 End tag for element not finished 31 38 37 46 38 Attribute value not allowed 28 39 42 36 36
Undefined attribute
In HTML each element can be described by specific attributes specified in the element’s DTD declaration. The "undefined attribute" diagnostic is triggered when, during the validation, an element appears as being described by an attribute that is not specified in the element’s DTD declaration. Some situations in which this diagnostic can be triggered are:
- The attribute is completely undefined or unknown — it is not valid for any element in any identifiable HTML version. Typically this might arise from a simple mistyping of the attribute name in a manually authored page.
- The attribute is valid for use with some elements (per the specified DTD), but is not valid for use with the particular element where it has been detected in the target document.
- The attribute is valid for the particular element in some HTML DTD(s), but is not valid for the particular DTD specified in the target document. Typically, the attribute might have been introduced for this element in a later HTML version than that specified by the document DTD.
- The attribute is used with an element that is itself not defined (per the specified DTD). This is then a propagated defect arising from the fact that the element is undefined.
Element not allowed by the document type
An element can be used in a HTML document within another element, but there can be misinterpretations according to the DTD. These defects are usually due to a misconstruction of nested elements, for example a list item element (LI) used directly within a paragraph element (P) when it should only be used directly within a list element (OL or UL).
End tag for element not opened
The content of an HTML element is delimited by a "start tag" and an "end tag;" the way that the elements can nest is described in the DTD. If onsgmls encounters improperly nested elements, it considers that the outer element is implicitly closed before the start tag of the inner element and it triggers a "missing end tag" diagnostic if the end tag is required in the structure of the outer element. Later, in the content of the document, when the original end tag of the outer element is encountered, onsgmls considers it as belonging to no opened element.
Required attribute not specified
This signals that the DTD declares that a certain attribute is required on some element, but it is not present. Some specific features addressing Web accessibility for users with disabilities are implemented with the help of compulsory attrbutes, providing details on the content of an element when the element can’t be rendered effectively or directly for a particular user. Thus, this defect is particularly likely to be directly correlated with accessibility problems.
Whilst this diagnostic’s incidence is quite similar in the U.K., French and German Web samples (around 75 percent), it is considerably smaller in the Irish Web sample at 53 percent.
Missing required end tag
This diagnostic is triggered when the DTD declaration specifies that the end tag is required for a particular element, but it is missing from the HTML code in the Web page. Some situations in which this diagnostic can be triggered are:
- XHTML: Both the start tag and the end tag are required for XHTML (as opposed to HTML) elements, including "empty" elements such as HR.
- In the case of improperly nested elements, onsgmls considers that the outer element is implicitly closed before the start tag of the inner element and it triggers a "Missing end tag" diagnostic if the end tag is required in the structure of the outer element. Later, in the content of the document, if the original end tag of the outer element is encountered, onsgmls considers it as belonging to no opened element and triggers an "End tag for element not opened" diagnostic.
This diagnostic’s incidence is quite similar in the U.K., Irish and German samples (around 54 percent of the sites considered for further analysis) and smaller in the French Web sample (46 percent).
Non–SGML character number
In general, authoring tools may encode HTML documents in the character encoding of their choice, providing the encoding is correctly labelled. The information about the character encoding of a document can be specified via HTTP headers and/or using an embedded META http–equiv element. However, due to the implementation characteristics of the system used in this survey, character encodings specified via HTTP headers are lost after the mirroring process discussed earlier.
This diagnostic appears to be commonly triggered when the authoring tool which generated the Web page uses a character encoding of its own choice but the information regarding the character encoding is not made available in HTML. As a result, in order to validate the document, onsgmls will have to use heuristics to determine the character encoding. Although this practice is standards conforming (World Wide Web Consortium (W3C), 1999a, Section 5.2.2), its results are necessarily unpredictable.
From the point of view of practical browsing, if the character encoding is not reliably communicated, then the rendering of specific characters will be unpredictable, and may be incorrect. This would potentially slow down and confuse comprehension. This can impact all users, but may have a disproportionate effect on some disability groups. For maximum accessibility, it is recommended that an open standard character encoding be used (such as ASCII, UTF–8, ISO–Latin–9, etc.) and that this should be explicitly declared via both HTTP headers and an embedded META http–equiv element.
General entity not defined and no default entity
A given character encoding (method of converting a sequence of bytes into a sequence of characters) may not be able to express all characters of the document character set (a set of abstract characters used in a document and their integer references; World Wide Web Consortium (W3C), 1999a, Section 5). For such encodings, or when hardware or software configurations do not allow users to input some document characters directly, authors may use SGML character references.
The & (ampersand) character is a special character in SGML, marking the start of a character reference. When the & is used as such in an HTML document as part of a text (e.g., "Smith&Sons") onsgmls will look in the document character set for the abstract character represented by the "&Sons" character reference. It won’t find it so it will trigger the above diagnostic. This should be avoided by "escaping" literal use of the & character — that is, by using the character reference & everywhere in the HTML document where the & character is not intended as the start of a character reference.
The issue of & character used as such instead of its character reference & arises especially in URLs. When Web content is generated dynamically (using a server side application), options for specific Web pages may be embedded in URLs separated from each other with & characters. Links to such URLs should escape the & character as discussed before.
Attribute value must be literal
By default, SGML requires that all attribute values be delimited using either double quotation marks (ASCII decimal 34) or single quotation marks (ASCII decimal 39). Still, some "relaxed" standards allow attribute values not included in quotation marks, provided that they follow some rules.
This diagnostic is triggered when the value of an attribute is not included between "double quotation marks" although it should be because the specific use wouldn’t qualify for the exception rules (e.g., <table width=90%> instead of <table width="90%">).
End tag for element not finished
This diagnostic is triggered when an end tag is found for an element when one or more of its inner elements are still open. In most cases this appears to be an error propagated from other HTML defects already detected by onsgmls, as discussed previously.
Attribute value not allowed
This diagnostic is triggered usually when the value of an attribute is not one of the values permitted for that attribute in the specified DTD.
Conclusions of the HTML technical standards conformance tests
The level of conformance to HTML technical standards of Web content considered for tests is alarmingly low (almost nonexistent) in all the four Web samples.
Most of the HTML defects on the sites studied are probably not apparent to the majority of Web users because, presumably, the developers have specifically tested them against some (small) selection of "popular" browser platforms. However, because they do not conform to technical standards for interoperability, their rendering is — at best — unpredictable. This is likely to have a disproportionate affect on users who rely on specialized, tailored, client technologies — specifically, users with disabilities. Content may thus fail to be rendered, may be garbled, or may be otherwise inaccessible to such users. Worse, precious development effort in individualizing assistive technologies may have to be spent on attempting to compensate for these server side defects, rather than improving the client side functionality that the user really needs. In the worst case, this effort may have to be wasted repeatedly for each different client accessing each different (non–conformant) server. Obviously, conformance to technical interoperability would substantially reduce or eliminate this waste.
On the sites that had usable document type information, the lowest number of distinct HTML standard violations was triggered by the sites in the Irish Web sample (35) and the highest one in the German Web sample (52). The sites in the French sample triggered 45 distinct HTML standard violations while the sites in the U.K. Web sample triggered four distinct HTML standard violations. Although the number of distinct diagnostics triggered by the four samples varies, the most common 10 diagnostics are the same for all the four samples, and their ranking by relative incidence varies with an average of just three places, the most common three diagnostics being the same.
The frequency of distinct HTML standard violations detected by onsgmls is shown in Table 12. This same data is presented in chart form in Figure 3. In this data the percentage is calculated in relation to the total number of sites that had usable document type information a shown in Table 10.
Most sites in the four samples had up to 15 distinct HTML standard violations detected by onsgmls. But the majority of these defects could be repaired relatively easily. Although it might seem that it would involve a considerable amount of work, many of the detected defects are interrelated — so that correcting one substantive HTML code defect could eliminate a number of reported diagnostics.
Table 12: Frequency of HTML standard violations detected by onsgmls on Web content with usable document type information.
Number of distinct diagnostics IE
(%)UK
(%)FR
(%)DE
(%)0 2.8 4.4 11.4 4.8 1–5 19.4 19.6 17.9 13.9 6–10 36.1 39.1 35.7 43.8 11–15 36.1 31.1 26.4 28.5 16–20 2.8 5.7 8.6 8.6 21–25 2.8 0.2 0.0 0.3
Figure 3: Frequency chart of HTML standard violations detected by onsgmls on Web content with usable document type information..Web content authors should become familiar with HTML standard technical specifications and integrate in their publishing routines one of the existing HTML validation tools in order to ensure that their Web content is valid before it becomes public. These tools not only list defects encountered but also give references as to how these defects might be repaired. One such tool is the W3C’s online HTML Validator which is easy to use, doesn’t require local installation and can validate either online or uploaded Web content.
Many Web page authors use HTML authoring tools or content management systems. With some of these tools, HTML markup may be hidden from an author. If some of the HTML markup is invalid, some authors may become discouraged from providing valid HTML code. They may not understand HTML specifications, so they will not know how to repair the code (even if the authoring tools allow such intervention — and some do not). In these cases, authors should raise this accessibility issue with the developers or vendors of their Web content authoring tools.
Discussion
This section provides a brief critical review of the study, and of the tools and methodology adopted.
First, this project has demonstrated that this sort of largely automated survey of selected accessibility indicators is technically fesible. Once the appropriate tools have been developed and integrated, the technical resources to carry out such a survey are comparatively modest. This contrasts with surveying approaches that rely on significant manual intervention.
However, the project has also identified a number of limitations and open issues, many of which will require further research.
- A fundamental issue in the study is the effect of limiting it to those accessibility indicators that can be measured by purely automatic means. On the one hand, these means allowed the surveying of a comparatively large number of feasible sites. On the other hand, it runs a real risk of focusing corrective action solely on these automatically detectable defects, to the exclusion of action on other — potentially much more significant — accessibility barriers.
- The work reported here is based on a snapshot taken at one point in time. Much of the real value of the work would be in exploiting the same machinery to repeat the survey automatically at regular intervals, and track any trends or significant changes.
- An open question is the relationship between WCAG conformance and the actual experience of real users. By its nature, that is not amenable to automated testing.
- The sampling techniques used in the study are intrinsically qualitative; the sites selected are not "statistically representative," and the results cannot be directly extrapolated by statistical means. This is a non–trivial problem. It is not apparent that it is even possible — in principle — to carry out a statistically representative sampling for these particular purposes.
- A quite separate issue is the strategy for delimiting and sampling individual sites. We conjecture that the key results presented here are not strongly sensitive to this internal site sampling strategy (above some minimal sample size: realized in the current case by requiring that more than three Web pages be successfully retrieved from any given site). However, it would be feasible and desirable to carry out a further study in which a substantially larger sample was taken (or at least attempted) of each site in order to test this conjecture explicitly.
- The site capture mechanism used in this study suffers from significant limitations with respect to sites which require user "registration." More generally, automated evaluation of "interactive" sites is fundamentally problematic. This is particularly important given the growing number and diverse roles of such sites. A special issue relates to those sites that allow users to "personalize" site appearance or behavior. In those cases, it might be argued that such a site’s content can be tailored to the needs of each user, and is therefore fully accessible even though this may be invisible to an automated mirroring robot. However, since a user needs to access the default Web presentation in order to "personalize" it in the first place, the default configuration — the one that would be automatically retrieved — should be conform to WCAG 1.0.
Conclusions
Although the number of sites in each sample was very different, the results of the survey were remarkably similar.
We conjecture that this similarity may be largely due to defects in common Web authoring tools or content management systems. However, the poor conformance to Web accessibility guidelines is presumably due to a lack of information and a misunderstanding of their importance on the part of content designers and authors. It seems that the "write once, read everywhere" concept is still quite far from reality, even though significant efforts in promoting Web accessibility are being invested in the studied countries.
The results of this survey do not represent the "exact" level of Web accessibility on Irish, U.K., French or German Web sites, but they demonstrate a widespread lack of concern with accessibility guidelines and technical interoperability. These results are similar to those from an earlier survey of Irish sites, using similar technologies (McMullin, 2002). While it may be argued that the results are still generated based on a sample of sites, the fact that samples generated essentially the same results is suggestive that this situation is probably typical of the Web as a whole in these countries. This is disappointing because it means that the Web is still not living up to its potential in offering significant improvements in service and opportunities for users with disabilities.
This study signals that, despite very laudable goals in documents such as the E–Europe Action Plan (European Commission, 2001), the current commitment to accessibility of the Irish, U.K., French and German Web for users with disabilities is, at best, aspirational — and, at worst, cynically inadequate.
This is doubly unfortunate. It is not just that Web technology is not being applied — as it could be — positively to improve opportunities and capabilities for users with disabilities. On the contrary, as Web services become more pervasive and essential, it means that those with disabilities in our society will increasingly suffer further disadvantages in accessing information and online services.
It is hoped that the results of this study will serve to highlight these issues, and to further encourage many agencies and organizations who are already actively promoting and supporting voluntary improvements in Web accessibility around the EU. Ultimately however, there must surely also be a role for compulsion — legislation and regulation — to fully guarantee and vindicate the rights of all citizens to equal treatment in a digital democracy.
About the authors
Ms. Carmen Marincu is currently completing her Ph.D. research studies at the eAccessibility Lab of the Research Centre for Networks and Communications Engineering (RINCE) at Dublin City University (DCU).
Dr. Barry McMullin is a senior lecturer in the School of Electronic Engineering of Dublin City University (DCU), and directs the eAccessibility Lab.
E–mail: Barry.McMullin@rince.ie.
Acknowledgments
The work described here received financial support provided from AIB PLC. The work was carried out in the Research Institute for Networks and Communications Engineering (RINCE), established at DCU under the Programme for Research in Third Level Institutions operated by the Irish Higher Education Authority.
References
J. Brewer, 2001. "How people with disabilities Use the Web," at http://www.w3.org/WAI/EO/Drafts/PWD-Use-Web/, accessed 15 October 2003.
A. Engelfriet, 1997. "Using frames and accessible Web sites," at http://www.htmlhelp.com/design/frames/, accessed 18 September 2003.
European Commission, 2001. "eEurope 2002: Accessibility of public Web sites and their content: communication from the Commission to the Council, the European Parliament, the Economic and Social Committee, and the Committee of Regions," at http://europa.eu.int/information_society/topics/citizens/accessibility/web/wai_2002/cec_com_web_wai_2001/text_en.htm, accessed 22 September 2003.
European Commission, 2000a. "eEurope: An Information Society For all," at http://europa.eu.int/information_society/eeurope/2005/text_en.htm, accessed 21 October 2003.
European Commission, 2000b. "eEurope targets 2001/2002," at http://europa.eu.int/information_society/eeurope/2002/action_plan/eaccess/eu/targets_2001_2002/text_en.htm, accessed 16 July 2004.
French Government, 1999. "Circulaire du 7 octobre 1999 relative aux sites internet des services et des établissements publics de l’Etat," at http://www.admi.net/jo/19991012/PRMX9903708C.html, accessed 16 July 2004.
German Government, 2002. "Barrierefreie Informationstechnik–Verordnung," at http://www.webforall-heidelberg.de/html/deutsch/bitv.php, accessed 12 November 2003.
Irish National Disability Authority (NDA), 2001. "Guidelines for Web accessibility," at http://accessit.nda.ie/, accessed 7 July 2003.B. McMullin, 2002. "Users with disability need not apply? Web accessibility in Ireland, 2002," First Monday, volume 7, number 12 (December), at http://firstmonday.org/issues/issue7_12/mcmullin/, accessed 12 November 2003.
Office of the e–Envoy, 2002. "Web guidelines," at http://e-government.cabinetoffice.gov.uk/Resources/WebGuidelines/fs/en, accessed 12 November 2003.
World Wide Web Consortium (W3C), 1999a. "HTML 4.01 specification," at http://www.w3.org/TR/html401, accessed 21 October 2003.
World Wide Web Consortium (W3C), 1999b. "Web content accessibility guidelines 1.0 (WCAG 1.0)," at http://www.w3c.org/TR/WCAG10/, accessed 7 August 2003.
J. Zeldman, 2001. "To hell with bad browsers!" A List Apart, issue number 99 (16 February), at http://www.alistapart.com/stories/tohell/, accessed 18 September 2003.
Editorial history
Paper received 16 April 2004; accepted 15 June 2004.


Copyright ©2004, First Monday
Copyright ©2004, Carmen Marincu and Barry McMullin
A comparative assessment of Web accessibility and technical standards conformance in four EU states by Carmen Marincu and Barry McMullin
First Monday, volume 9, number 7 (July 2004),
URL: http://firstmonday.org/issues/issue9_7/marincu/index.html