Finders, keepers? The present and future perfect in support of personal information management by William JonesTo keep or not to keep? People continually face variations of this decision as they encounter information. A large percentage of information encountered is clearly useless — junk e–mail, for example. Another portion of encountered information can be "used up" and disposed of in a single read — the weather report or a sports score, for example. That leaves a great deal of information in a middle ground. The information might be useful somewhere at sometime in the future. Decisions concerning whether and how to keep this information are an essential part of personal information management. Bad decisions either way can be costly. Information not kept or not kept properly may be unavailable later when it is needed. But keeping too much information can also be costly. The wrong information competes for attention and may obscure information more appropriate to the current task. These are the logical costs of a signal detection task. From this perspective, one approach in tool support is to try to decrease the costs of a false positive (keeping useless information) and a miss (not keeping useful information). But this reduction in the costs of keeping mistakes is likely to be bounded by fundamental limitations in the human ability to remember and to attend. A second approach suggested by the theory of signal detectability is relatively less explored: Develop tools that decrease the likelihood that "keeping" mistakes are made in the first place.
Contents
Introduction
Present PIM tools to the rescue? The problem of information fragmentation
The keeping decision as a signal detection task
Future perfect vision #1: The costs of a keeping mistake go to zero
Future perfect vision #2: The likelihood of making a keeping mistake goes to zero
Conclusion
Introduction
In the ideal world, we have the right information at the right time, in the right place, in the right form, and of sufficient completeness and quality to perform the current activity. Tools and technologies help so that we spend less time with burdensome and error prone actions of information management (such as filing). We then have more time to make creative, intelligent use of the information at hand in order to get things done.
The reality is otherwise. Information is not always there when we need it or where we need it. The information we need to complete a task may be scattered across different locations (home and work) on different computers and in different forms (e–mail, e–documents, paper documents, Web references) within different organizational schemes. We frequently encounter information that is potentially useful, but for a future task, not the task we are currently trying to complete. Even information that is relevant to the current task can rarely be consumed in a single sitting. We may return to an article or report several times over an extended period of time as we extract various aspects of its information.
In these cases, we face the challenge of managing information for personal re–use — of "keeping found things found" (Jones et al., 2001). The important action of initially finding information has been the subject of considerable study; this is what the field of information retrieval is all about. But, what happens once information is found? How do we keep this information so that it can be re–accessed later when a need for this information arises? The ability to manage information for re–use, to keep found things found, is an essential component of good personal information management, or PIM (Lansdale, 1988). PIM includes all activities relating to the acquisition of new information (whether by deliberate search or more happenstance encounter), its organization into a personal store and its eventual re–access for re–use.
This article asserts the following:
- The keeping decision is fundamental to personal information management and fundamentally difficult. As people encounter new information they must decide whether or not to keep it and, if so ... How? Where (home or work)? In what form (on paper, in e–mail, in an electronic document, as a reference only that points to Web information elsewhere)? Leave unorganized (in a "pile") or put in a folder? Which folder(s) or under which tags? These decisions depend upon an understanding of the information itself and of the space into which the information will be placed ("Is the information already in here, somewhere?", "What must I do to remember it later on?"). Decisions also depend upon an ability to anticipate future information need (Bruce et al., 2004).
- Present support for PIM often, inadvertently, works to perpetuate, and sometimes increase, a situation of information fragmentation that makes the keeping decision more difficult and keeping mistakes more costly. Favorites/bookmarks work for Web references but not for e–mail. Reminders can be set for e–mail messages but not for local files or Web pages. Tools such as Microsoft’s OneNote (Microsoft, 2003) introduce wholly new forms of information. The organizations for new information forms are separate from those for existing forms such as e–mail, electronic documents, Web references (Favorites or Bookmarks) and paper. Personal Digital Assistants (PDAs) and smart phones produce still more information fragmentation. New information can then be kept in many different ways. In fact, information may already be "in there" somewhere! With so many alternatives in the way information is kept, the chances increase that information is misplaced, misfiled or simply forgotten.
- The keeping decision can be usefully viewed as a signal detection task (Peterson et al., 1954; Van Meter and Middleton, 1954). The theory of signal detectability (TSD) has broad application to tasks where people must distinguish between signal and noise. TSD makes provision for two kinds of errors: a.) the error of saying "yes" to noise (keeping useless information) and b.) the error of say "no" to signal (deciding not to keep useful information). Going back to the work of Swets (1963, 1969) TSD has been applied to decisions concerning what is returned in an initial search for information. This article suggests that TSD also has good application to a person’s decision to keep or not to keep information. TSD also suggests two general approaches to the support of the keeping decision: Reduce the costs of keeping mistakes or reduce the likelihood of making keeping mistakes.
- One overall direction in tool support and enabling technologies works to reduce the costs of keeping and of making keeping mistakes. It is cheap to keep information, whether useful or not. It is often easy to find information again even if it is not kept. For example, there is little cost in automatically keeping a history of Web page access and even caching copies of the pages themselves — whether useful or not. But even if no information is kept, useful Web pages can often be found again anyway using a Web search service.
- However, the reduction in costs of keeping mistakes is likely to bump into lower limits reflecting basic limits of the human condition. Disk space is cheap and information encountered can be kept automatically. But human time and attention are still dear, so that some costs of falsely keeping useless information remain. This useless information competes for time and attention and may obscure, in one way or another, the information people really need. Likewise, even as search support continues to improve, some costs of a "missing" or not keeping useful information will remain. For example, people can’t find again what they forget to look for.
- A second direction in support of PIM is to develop strategies and tools that reduce the likelihoods of making keeping mistakes in the first place. In the parlance of TSD, reducing the likelihoods of making keeping mistakes is equivalent to increasing the detectable differences that separate useful from useless information. The article concludes with a look at possible support for doing this. Special attention is given to the potential value of a Personal Unifying Taxonomies or PUTs. A PUT is essentially a classification scheme customized to the life of its owner. It reflects various activities, people and areas of interest in a person’s life — past, present and future.
In support of these assertions, the article looks first at the current state of PIM support before exploring the keeping decision as a signal detection task. The article then explores the two "future perfect" visions of PIM suggested by TSD: 1.) The costs of making keeping mistakes go to zero. 2.) The likelihood of making keeping mistakes goes to zero. Of course neither vision is ever completely attainable. However, as costs associated with keeping mistakes approach lower limits, there is still considerably more that can be done to reduce the likelihood of making a keeping mistake in the first place.
Present PIM tools to the rescue? The problem of information fragmentation
A wide range of tools and technologies are now available for the management of personal information [ 1]. But this diversity has become part of the problem leading to information fragmentation. A person may maintain several separate, roughly comparable but inevitably inconsistent, organizational schemes for electronic documents, paper documents, e–mail messages and Web references. The number of organizational schemes may increase if a person has several e–mail accounts, uses separate computers for home and work, uses a PDA or a smart phone or uses any of a bewildering number of special–purpose PIM tools. New tools often introduce still more schemes of organization [2].
If some PIM tools inadvertently lead to greater information fragmentation, other tools can provide a partial remedy. A number of commercial products are now available to support the full–text search of personal information [ 3]. Many of these products are integrative in their ability to search across several forms of information. The Stuff–I’ve–Seen project (Dumais et al., 2003) has also had excellent success in the implementation of a prototype that searches across Web pages, e–mail, e–documents and calendar information.
The search for personal information should continue to get better for a number of reasons. For example, documents and other information items are likely to carry increasing amounts of searchable metadata to complement document content. Even so, a search is not likely to provide more than a partial remedy for information fragmentation. For one thing, there is important metadata, most notably intended use (Kwasnik, 1989), which, under most circumstances, only the user can provide. And observational data suggest that people may continue to have a strong preference for location–based finding, orienteering, or simply browsing as a primary means to return to their personal information (O’Day and Jeffries, 1993; Barreau and Nardi, 1995; Marchionini, 1995; Teevan, 2003).
A report on PIM (Jones and Maier, 2003) from the 2003 National Science Foundation (NSF) Information and Data Management (IDM) workshop identifies information fragmentation as one of the major challenges that must be met if PIM is to improve. The report also noted that the study of PIM is itself often fragmented according to applications in ways that parallel the fragmentation of personal information. Many excellent studies focus on uses of and possible improvements to e–mail (for example, Mackay, 1988; Whittaker and Sidner, 1996; Balter, 2000; Bellotti and Smith, 2000; Gwizdka, 2000; Ducheneaut and Bellotti, 2001; Bellotti et al., 2002; Gwizdka, 2002a, 2002b; Wilson, 2002; Bellotti et al., 2003). Other studies similarly focus on the use of the Web or specific Web facilities such as the use of bookmarks or history information (for example, Catledge and Pitkow, 1995; Tauscher and Greenberg, 1997a, 1997b; Abrams et al., 1998; Byrne et al., 1999). A wide range of studies have looked at the organization and retrieval of documents in paper and electronic form (for example, Carroll, 1982; Malone, 1983; Case, 1986; Whittaker and Hirschberg, 2001).
But the study of PIM across information forms is still in its infancy. The results of initial studies suggest that there is overlap — similar or same folder names, for example — between the organizations for different information forms (Boardman et al., 2002).
In the Keeping Found Things Found (KFTF) studies (Jones et al., 2001; Jones et al., 2002; Jones et al., 2003), participants often expressed frustration that they needed to maintain so many different organizational schemes in parallel. Several participants indicated that they had largely abandoned their organizations of Favorites or Bookmarks as "one organization too many." Two participants indicated that they went to great lengths to consolidate organizations. One person printed everything of importance to paper to participate in an elaborate paper–based filing system. A second person saved e–mail and Web references in electronic documents which could then participate in a computer–based filing system. In a third instance, described in greater detail later in this article, an assistant and her manager worked to establish a single organizational scheme which was then used as a basis for the re–organization of e–mail, e–documents and paper documents.
Participants in the KFTF studies were occasionally observed to look in the wrong place for an information item (for example, in Favorites for a Web reference that was actually sent in self-addressed e–mail or pasted into a document). Participants were sometimes observed to "keep" Web information in several different forms (for example, as a reference in a self–addressed e–mail, as a file to the hard drive and as a Favorite) to insure that it could be retrieved later.
The limited data available suggest that many existing PIM tools, while helping in some ways, are further exacerbating problems of information fragmentation by providing separate, and often inconsistent support for information organization. Information fragmentation creates several problems that relate to the keeping decision of PIM.
- How to keep? In which organization? Keep in several places? (People may take extra time to keep the same information in several ways "just to be sure" they can find the information again later.) Keep a copy of the information or only a reference to this information in a bookmark, for example?
- Where to find? Later, people may need to look in several organizations before finding the desired information.
Other problems also follow from information fragmentation and the need to maintain several information organizations in parallel:
- The costs and difficulties of maintaining an organizational scheme are multiplied by the number of forms for which some organization is necessary. If a folder is created, re–named or deleted in one organization, shouldn’t this be done elsewhere too? And what happens when there isn’t time to do this?
- The assembly of task–relevant information can be a problem even if people know where to look for each item. Considerable time may be required to retrieve information from different places and across several different information forms (e–mail, e–documents, Web references, paper) in order to complete a task. When information is scattered, there is also increased danger that some information relevant to a task is simply overlooked or forgotten about altogether.
The keeping decision can be viewed as a signal detection task. Doing so suggest two "future perfect" approaches to overcoming current problems of information fragmentation.
The keeping decision as a signal detection task
The theory of signal detectability (TSD) first appeared back in 1954 (Peterson et al., 1954; Van Meter and Middleton, 1954). TSD is grounded in statistical decision theory and provides a framework with which to understand perceptual processes and decision making — especially in people. TSD has been applied elsewhere to a basic question of information retrieval: What does and does not get returned in response to a user’s query [ 4]. In this article, TSD is applied to keeping decisions.
The message of TSD might be summarized as "damned if you do; damned if you don’t." Consider the proverbial boy who cried "wolf!" The boy must make a timely decision to cry "wolf!" or not based on scanty, ambiguous perceptions — the snap of a twig, grey shadows in the trees beyond the pasture where his sheep are feeding. These perceptions may, or may not, signal that wolves are about to descend upon his flock. The two possibilities in stimulus — signal (wolves are present), noise (no wolves are present) — and the boy’s two responses — yes (cry "wolf!"), no (do nothing) — combine to form the outcomes and associated payoffs that are depicted in Table 1.
Table 1: Outcomes and payoffs in the fable of the boy who cried "wolf!"
Cry "wolf!" Do nothing Signal — wolves are present A Hit
The townspeople come. The sheep are saved. The boy is praised for his vigilance.A Miss
Sheep are eaten. Perhaps the boy is eaten too.Noise — no wolves are present False Positive
Townspeople are irritated with the boy and are less likely to come the next time he cries "wolf."A Correct Rejection
No cost; no benefit. Just another day.
Whenever people encounter information they face an analogous choice whether this choice is consciously exercised or not: Should steps be taken to keep the information for later access and use? The choices made in the act of keeping information and the reasons for doing so can vary greatly. But the essential choice is the same: To keep or not to keep? The choice is made both for information that comes back from a search and for information encountered by happenstance (Erdelez and Rioux, 2000). The outcomes and associated payoffs for this keeping decision are summarized in Table 2.
Table 2: Outcomes and payoffs of the keeping decision.
Keep Don’t keep Signal — the information is useful A Hit — useful information is kept.
Benefits: The information is more likely to be available later when needed.
Costs: The fixed costs of keeping information, including a person’s time, energy and the potential interruption of a current activity (the costs of time and task interruption to create a Web bookmark, for example). These will vary with the keeping method.A Miss — useful information is not kept.
Costs: Extra time and effort to find the information again later, and greater likelihood that the information cannot be found when needed or is forgotten about entirely.Noise — the information is not useful A False Positive — useless information is kept.
Costs: The fixed costs of keeping information (same as for a hit), an overall increase in clutter, and an increased likelihood that other useful information will be obscured and overlooked.A Correct Rejection — useless information is ignored. No cost; no benefit.
Some things to note:
- The cost of the false positive in Table 2 is not merely a cost wasted time and energy (and maybe money too). Certainly the time and energy would have been better spent elsewhere. But there is also the real and persistent cost associated with the added clutter that useless information brings to our lives. Useless information obscures better, more useful information. Useless information competes for our limited time and attention. Useless information gets in the way. Its maintenance and eventual deletion (if this ever occurs) also take time. Useless information also produces a very real, if difficult to measure, emotional cost as it increases our overall angst that we are not in control of our information.
- The term "useless information" as used in this article is interchangeable with the somewhat more awkward expression "information not used." There is no value judgment associated with the term. Useless information is never used. Most of us have a great deal of information — locked in stacks of old magazines and newspapers, for example — which we have not yet and likely never will use.
- The reader may notice that there appears to be a double counting for the value of useful information in Table 2. If useful information is not kept, people must take extra time and effort to locate this information later and risk not having this information. If useful information is kept, people have the benefit of its increased availability. The intention is not that the same information be counted twice — once as a cost for its absence, a second time as a benefit for its presence. Information can be roughly divided by two levels of importance: 1) Information that is essential or at least very important for the completion of a task; and, 2) Information that might significantly improve the outcome of a task but is not essential to its completion. If we have not kept the first kind of information, we will suffer the cost of extra time to find this information again. We are more likely to do without information at the second level of importance but will benefit from the decision to keep this information on hand. For example, if I am buying a new laptop computer, a recent review of laptops is more likely to fall in the second level of importance. My purchase decision is improved for the use of this information and I am happy if this information is readily available, but I can purchase a laptop anyway.
Table 2 has variations. We face a similar choice when we "spring clean" a collection of information; for example, a stack of magazines, the messages of an inbox or older files on a hard drive. Keep or not keep (toss, delete)? The information has already been kept but in most respects it is like new information. If we elect to keep, we may change its location or means of keeping. Or, if we leave it where it is, we have a strengthened memory for its current location.
Variations of Table 2 apply to the selection of information channels through which we receive information on an ongoing basis. Subscribe to this or that magazine or newspaper? Pay for extra TV channels? Set the car radio to this or that station? Cultivate this or that collegial relationship or friendship?
If we decide to keep information, we’re not done. A decision to keep information expands into a large number of smaller decisions. Where? On what device? In what form (e–mail, e–document, Web reference)? Leave in a relatively unorganized "pile" or "file" by placing in a folder or tagging?
So, even if we correctly decide to keep information, we may still go wrong in the specifics of its keeping. We may put the information in the wrong place (e.g. information may be placed in the folder for the Kelly account that actually belongs in a folder for the Johansson account). Sellen and Harper (2002) cite estimates that three percent of all paper documents are misfiled and that eight percent of these documents are eventually lost.
A filing error incurs costs of both a false positive and a miss. The information takes up space (physical and mental) in the wrong folder, distracting us from the more relevant information in that folder. At the same time, the information is not where it should be. Finding this information again later will take extra time and, per Sellen and Harper, there is a significant chance that misfiled information is never found. Given the costs of filing — immediate and delayed — it may be better to leave documents in piles (Malone, 1983) or larger, less differentiated folders. But this approach carries its own costs. Each document retrieval takes longer and important documents are more likely to be overlooked.
The situation is potentially better for digital information. Computer–based tools can help to reduce the costs both to keep information and to find this information again later on. The potential of computer–based tools to reduce the costs of keeping and re–finding — and associated costs of misses and false-positives — is explored more fully in the next section.
Nevertheless, mistakes happen. In the parlance of TSD, people don’t operate with perfect sensitivity. The best people can do is to adjust their thresholds for keeping information and for committing this information to this or that organization. People should keep (or commit) when the expected value of doing so exceeds the value of not doing so.
Given the available evidence, x, the expected value, E, to keep information factors in the probabilities (P) for a hit and a false positive along with the costs and benefits (V) for each:
#1 E(Keep|x) = V(Hit)*P(Information Is Useful|x) + V(False Positive)*P(Information Is Not Useful|x).The expected value to not keep information does likewise:
#2 E(Not Keep|x) = V(Miss)*P(Information Is Useful|x) + V(Correct Rejection)*P(Information Is Not Useful|x).In these expressions, x is a catch–all representing the total evidence a person has readily available when making a decision. Included in x are the person’s understanding of the information itself, related information the person already "has", and the activities for which this information will be used.
A person should keep — when #1 is greater than #2. Some implications immediately follow:
- People working in professions for which complete information and good record–keeping are especially important — lawyers or doctors, for example — would be expected to have a lower threshold for deciding to keep information, at least in their professional role.
- People are more likely to keep information as the cost of storage goes down. Lower storage costs mean lower costs for a false positive. The same person will likely have many different thresholds depending upon the information form and the channel involved. For example, an office worker might simultaneously be "upgraded" to a computer with a larger hard drive and "downgraded" to a smaller office with less room for filing cabinets and other means of paper storage. The corresponding cost of a false positive then goes down for electronic information and up for information in paper form. Other things (such as job role and status) being equal, the office worker should be more inclined than before to keep information in electronic form and less inclined than before to keep information in paper form.
- People should also be more likely to keep information that is presented in a new form and over a new channel. For example, several people in the KFTF studies reported that when they first started to use a Web browser they freely created Bookmarks or Favorites; now they are much less likely to do so. The sense is that their space has "filled up."
- People should be more likely to keep information as tool improvements make its storage and organization easier. Effectively, the costs of keeping this information (and the costs of a false positive) go down. This effect should again be specific to an information form. It is not difficult to imagine, for example, that people became more inclined to keep e–mail as e–mail applications made the organization of e–mail easier through the addition of support for folders, searching and sorting.
- Conversely, improvements in the tool support for finding information (without first "keeping" it) should raise the threshold for keeping information in a personal store. The costs of a miss are lowered. Why store locally what can be easily and reliably located again later regardless? Note, per Table 2, that there are costs associated with keeping information whether or not it proves to be useful. It takes time, for example, to bookmark or print out a Web page. For Web use, we may be nearing a situation where the expected value of keeping information is nearly always lower than the expected value of not keeping the information. In a KFTF study of re–finding (Jones et al., 2003), participants were able to return to Web information when prompted with 95 percent or greater accuracy. Participants had good success even for sites that they had last seen six months or more ago. More important, three methods accounted for more than two thirds of these successful returns: 1) Accept the suggested completion of a partially entered Web address ("auto–complete"); 2) Use a search service; and, 3) Access the Web site from another Web site (such as a portal). None of these methods required explicit keeping.
- The perceived salience of the information under consideration may bias people to keep. People may overestimate the benefits of the information, the costs of its absence and the likelihood that the information will be useful. The costs of a false positive — increasing clutter or the greater likelihood that good information is obscured — are less apparent. A related tendency to overestimate probabilities for easily remembered or perceptually salient events has been repeatedly documented in investigations of human decision–making [ 5]. We might call this the "old magazine effect." Many of us have had the experience of sorting through a pile of old magazines with the intent to throw out most. Don’t look! A magazine’s cover screams for our attention with articles that may appear very useful. The magazine we have not found the time to read for three years may get a reprieve — only to sit in a pile, unread, for another three years.
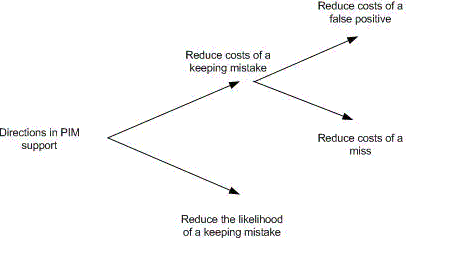
The grim message of TSD may be "damned if you do; damned if you don’t." But TSD, as depicted in Figure 1, suggests two approaches to improve the expected value of keeping decisions and, with that, the overall quality of personal information management:
- Reduce the costs of a keeping mistake.
- Reduce the likelihood of making a keeping mistake.
Each of these possibilities is now explored in turn as a "future perfect" vision of personal information management.
Figure 1: Directions in support of PIM.
Future perfect vision #1: The costs of a keeping mistake go to zero
One way of reducing the costs of a keeping mistake is by focusing entirely on reducing the costs of a false positive. As the costs of a false positive go to zero, the costs of a miss become increasingly irrelevant. Keep everything. Why not? It’s free! The Lifestreams project (Fertig et al., 1996; Freeman and Gelernter, 1996; Steinberg and Gelernter, 1997), MyLifeBits project (Gemmell et al., 2002) and DARPA’s LifeLogs project are in this spirit. The Stuff–I’ve–Seen (SIS) project (Dumais et al., 2003) also supports a "keep everything" approach. SIS makes it easy to complete full–text searches that bring together information items (e–mail, electronic documents, recently viewed Web pages, etc.) regardless of their current location (provided these are accessible from the user’s computer).
Also in the keep–everything spirit, albeit to a much more limited extent and for only one form of information, are the history and caching facilities of a Web browser. In all cases, notice is automatically taken of information a person encounters and, depending on the tool, this information is then indexed or otherwise organized and possibly cached for fast, easy access later on. A person needs to take no explicit action for encountered information to be kept, in some form, locally.
As digital storage capacities continue to increase and storage costs continue to decrease, we can certainly imagine a situation where a record of all digital information a person encounters and copies of the information itself are kept as personal information.
Several developments may provide additional help in reducing keeping costs. Documents may carry increasing amounts of metadata. The metadata may provide important description and retrieval cues that are missing in the document content. Support for the organization and retrieval of documents via content and metadata may be built in to the system [ 6]. These developments may bring us close to a vision of "placeless documents" (Dourish et al., 1999; Dourish et al., 2000) where people are freed from the restrictions of today’s folder hierarchies — the organization as well as the storage of information can be automated.
We might even make substantial progress in addressing the classic information retrieval problems of polysemy (a word can refer to several different things) and synonymy (several words are often used interchangeably in reference to a thing). Perhaps a thesaurus can be constructed that is customized to the needs of the individual so that personal information "in here" as well as public information "out there" can be easily retrieved — with no need to organize, tag or file the information ahead of time.
And yet, even as we approach this ideal, a basic cost of a false positive is likely to persist: Useless information competes for our precious supplies of attention and time. The now classic quote by Herbert Simon has enduring relevance:
"What information consumes is rather obvious: it consumes the attention of its recipients. Hence, a wealth of information creates a poverty of attention and a need to allocate that attention efficiently among the overabundance of information sources that might consume it." — Herbert Simon, 1971The supply of attention–getting real estate does not seem to be increasing and the old adage "out of sight; out of mind" still applies. Older e–mail messages in the inbox are pushed out of view by newer messages and frequently forgotten. Documents in a folder like "My Documents" or Web references in a bookmarking facility like Favorites compete with another for our attention. As their number increases, so too does the likelihood that we will overlook an important piece of information as a need for it arises. Similarly, the space on the personal toolbar, the desktop (physical or electronic), etc., is limited. Too much information can be nearly as bad as too little information.
Empirical findings also support the belief that people will continue to want to "keep" and to organize information in their own ways (Bergman et al., 2003) and that mistakes in doing so will continue to be costly. First, a primary means of organizing personal information is according to anticipated use (Kwasnik, 1989). Second, people continue to have a strong preference for location–based finding, orienteering or, simply, browsing as a primary means to return to their personal information even when sophisticated search support is available (O’Day and Jeffries, 1993; Barreau and Nardi, 1995; Marchionini, 1995; Teevan, 2003). This second finding is also supported by a wealth of empirical research demonstrating that, in most circumstances, people are better (faster, more accurate) at the recognition than the recall of information.
When working on a project (task, activity), we seek to gather together relevant information so that it is in one place and can be viewed, quite literally, at the same time. Different people have different styles. Some may scatter paper documents about their physical desktop. Others may do the analog with their computer desktop. Some may prefer to put all information relating to a task into a single folder. Having task–relevant information in a single place, under a single view, saves time. More important, the view acts as an extension of our very limited internal working memory. We may see important relationships between the information in a view that might not be apparent if the information is scattered about, and we are reminded of things that need to be done (Malone, 1983).
A task-centric organization of information might be dynamically generated — it could, for example, be the product of a search for information matching a tag that represents the task. But given the very personal, idiosyncratic nature of the tasks each of us performs and our ways of referring to these tasks, it is very unlikely that anyone else could provide these tags.
If we must still tag our information according to our anticipated uses of this information, keeping is not a cost–free activity, no matter how cheap storage becomes or how automated other aspects of keeping can become. Mistakes can still happen and these will be costlier still. Useless information may be kept. Worse, useful information may be incorrectly tagged. We then suffer the costs of both a false alarm and a miss — just as we would for misfiled information. We must spend extra time finding the information again (if we’re lucky). In the meantime, incorrectly tagged information may be taking up "attention space." When we look for information associated with the tag, for example, this information may appear first and distract us from looking at other, more relevant information.
A second approach in cost reduction is to make it extremely easy to find information "out there" so that the costs of a miss are very small or, in any case, smaller than the costs to keep information. There is then no reason to keep any information locally. Why bother? The information can be readily retrieved again — e.g. from the Web, from a corporate intranet, or from a specialty information store — when its need arises.
The success of "keep nothing" methods for re–accessing Web information has already been noted. People may often decide that Web information can be easily accessed again, when needed, via the auto–complete facility of a browser, a search service or another Web site. And people may decide that the costs of doing so are smaller than the costs of creating a reference to this information (e.g., a bookmark) locally.
Improvements in finding support may also favor the storage of work–related documents on a corporate intranet. (Intranet storage may be backed up by a company’s desire to maintain control over work–related information as much as possible.) For example, a friend of mine who works for a software company recently told me that he now keeps very few work–related documents on his computer’s hard drive. He has more or less constant access to the corporate intranet and prefers to leave work documents on the intranet. Fast, reliable access to these intranet documents is supported by full–text search support and a logical (to employees at least) project/sub–project folder organization.
E–mail provides another example where some people may be increasingly leaving information as is in the inbox, though this varies greatly according personal style (Whittaker and Sidner, 1996).
So, at the other extreme from the "keep everything" approach, nothing is kept. No keeping, no false positives. Everything is a "miss" but the costs of a miss are low. Information can be easily found again as the need for it arises.
This vision of a "keep nothing" future is limited in at least three ways.
- First, per earlier comments, we can’t expect that information "out there" will be labeled according to the activities we need to complete in our lives. It may make sense to rely on the shared organization of a corporate intranet for access to certain kinds of work–related information. But this organization reflects a considerable amount of work to achieve a shared vocabulary and a shared viewpoint among its users. Don’t expect the new employee to make effective use of this intranet without considerable training, and don’t expect the organization maintained by others to reflect our own unique constellations of activities.
- The second limitation is more fundamental: We can’t find what we forget to look for. Even if the organization of information out there perfectly aligns with our needs we still need to keep something locally in order to remember to use this information.
- A third limitation is that information "out there" is not under our control and could change or disappear entirely.
Future perfect vision #2: The likelihood of making a keeping mistake goes to zero
Developments in technologies and tools are working to significantly reduce the costs to keep and re-find information. Associated costs of false positives and misses are also going down — though there are limits to these declines as noted in the previous section. At the same time, a second possibility suggested by TSD remains largely unexplored. What can be done to reduce the likelihood of making keeping mistakes in the first place?
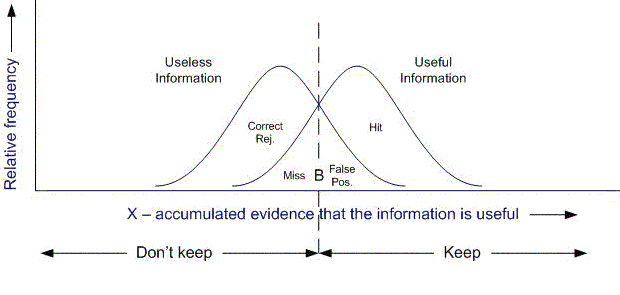
Figure 2: The likelihoods of a miss and a false positive are both large because distributions for useless and useful information overlap.
Our current situation is illustrated in Figure 2. Distributions for useful and useless information overlap to a considerable extent with respect to an x measure of "usefulness." In Figure 2, the likelihoods of a miss and a false positive are both large because distributions for useless and useful information overlap. Figure 2 also shows a response threshold. Keep encountered information when its x value is greater than B; otherwise, don’t keep it. B can be moved to reflect the relative costs and benefits of different outcomes — a hit, a miss, a false positive or a correct rejection. (And, per equations 1 and 2, B can also be adjusted to reflect estimations of the overall probability that encountered information is useful or useless.) If the cost of missing information is relatively high — as it often is in the legal and medical professions, for example — the threshold can be lowered. If the cost of missing information is relatively low — in the case of Web–based information, for example — the threshold can be raised.
But in Figure 2, the likelihoods of a miss and a false positive are both large because distributions for useless and useful information overlap. The likelihood of a false positive is reduced only by increasing the likelihood of a miss, and vice versa. In a sense, the overall likelihood of a keeping mistake remains the same. Since the distributions for useful and useless information overlap with each other considerably, this overall likelihood of a keeping mistake is high.
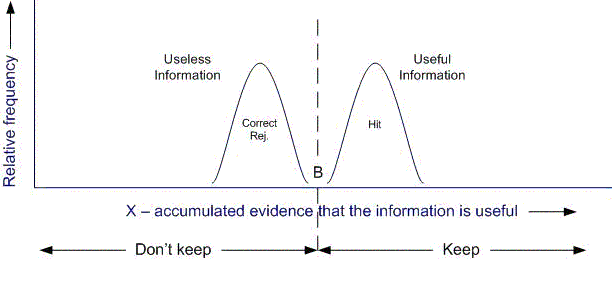
The situation is different in Figure 3. Now distributions for useful and useless information are widely separated from each other. For reasonable values of B, the likelihoods of a False Positive and a Miss are both low.
Figure 3: There is little overlap between distributions for useless and useful information and the likelihoods of keeping mistakes are small.
Note: The reduction in the likelihood of a keeping mistake in Figure 3 can be accomplished by reducing the "spread" associated with the distributions for useless and useful information or by increasing the difference in mean x ratings for the two distributions. The reduction in spread may be an apt representation for what happens if a person elects to spend extra time with an item of information before deciding whether or how to keep it. With extra time, the "sample size" contributing to the x rating increases and variance decreases. Better, more error–free decisions are made at the cost of extra time spent with the item of information.
In the ideal, we operate with perfect sensitivity. We are always correct in our initial assessment of an item’s information utility so that we do not miss useful information nor do we incorrectly keep useless information. Moreover, we are correct in all the particulars of the way we keep the information: we place it in the correct folder, tag it correctly, put it in the right physical location, in the right computer or gadget, in the right form, etc., in perfect alignment with our eventual uses of this item.
This ideal is certainly unattainable in our chaotic, uncertain world. But how can we come closer? The decision to keep or not keep an information item can be likened to a traveler’s decision to take this or that road as a means to reach a destination. The traveler needs to know about the road itself of course. Is it in good repair? How crowded is it? Is it a main road or a road that meanders through many towns? And so on. The traveler also needs to know where the destination is. And, just as important, the traveler needs to know where he or she is currently.
By analogy, three assessments are relevant to a person’s judgment of an item’s information value.
- What is the information content of the item itself?
- What is the person’s need for information, current and future? The ability to anticipate information need is very important to the keeping decision (see Bruce et al., 2004).
- What information does the person already have? Clearly, the information value of an item goes down, if the person already has much of its kind already.
Where am I now? What information do I have already?
Most of us can think of examples where we have had trouble with each of these assessments. Even if we had the time to thoroughly review a document, Web page or e–mail message, we might still miss or misunderstand important information in the item. And we rarely have time. We make snap judgments based upon a quick perusal. We have some understanding of our current and future information needs but this is far from perfect. We cannot see into the future.
More frustrating for many of us may be our lack of awareness of the information we "have" already. This is information we’ve made some effort to keep and that ought to be more accessible than information we haven’t kept. In the KFTF studies, for example, several participants described the frustration of finding a Favorite or Bookmark (often when cleaning and re–organizing) that pointed to Web information that would have been very useful for a project that is now finished. As noted earlier, knowing what information we already have is made more difficult when this information is scattered across various organizations and devices.
But even if we consider only a single form of information in our lives, e–documents for example, it is likely that many of us have no clear notion of what we have and don’t have. In informal surveys I’ve conducted in my classes, roughly a third of the students indicate emphatically that they are not happy with the way they organize information regardless of its form and that they do not feel in control of their information.
This is not surprising. Many researchers have observed that filing and other activities of information organization are fundamentally difficult and that people have trouble coming up with effective information organizations [ 7].
Many of us may find ourselves making organizational decisions in a bottom–up, ad hoc manner. We create a new folder to store e–mail messages, for example, because we can no longer stand the clutter in our inbox or because our system administrator or e–mail provider has told us the inbox is too full. The folder is hurriedly given a name with no thought to mirroring this folder elsewhere. One participant in the KFTF studies had folders named "stuff," "more stuff," and "still more stuff." How many of us have folders with similar names and lack of definition?
Again, steady improvements in support for searching personal information and in support for property–based, non–hierarchical storage may eventually eliminate the need to organize information into folders as we know them today. But we may still need to tag or organize information in some way in order to reflect the intended uses for which we are keeping this information. Can we get better at doing this?
In my informal classroom surveys, only a third of the students expressed strong displeasure with the way their information is organized. Surprisingly, another third (roughly) of students expressed considerable pride in at least one of their information organizations. This may, in part, reflect a difference in personality type — "neats" vs. "messies" to use Malone’s expressions (Malone, 1983). But that may not be the whole story. In the KFTF studies, some participants said that they used to be disorganized but no longer are.
One example of this "transformation" was an effort some two years ago (2002) by an assistant and her manager. They were experiencing the usual problems of PIM multiplied by the information stores they each maintained separately but jointly needed to access. Each of them separately maintained folder organizations for e–mail and e–documents. The assistant also organized paper documents into the hanging folders of several file cabinets.
Things were not working. None of the folder organizations worked very well by itself and there was only partial agreement between any of the organizations. Information in e–mail and documents was frequently mislaid and, worse, the manager and his assistant often had no clear understanding of the information they did and did not have.
They decided to do something. Over the course of several weeks they met periodically to discuss how their information should be organized. The assistant represented her understanding of their discussions in simple sketches illustrating important categories of information for their work and how these categories might be organized together. The assistant was a facilitator. In the end, they had a classification scheme — a taxonomy. This taxonomy was imposed upon their various stores of information: E–mail, e–documents, paper documents and even their collections of Favorites pointing to Web sites. This taxonomy, with small modifications, is still in use today some two years after its creation by the manager and his new assistant.
In general, a taxonomy need not be a hierarchy and might involve advanced concepts such as faceted classification [ 8]. Information items might be distinguished by different relations or property schemas together with rules concerning the values these properties can assume.
However, there is nothing fancy about the taxonomy that the assistant and her manager developed. It was built for the manager’s real world and the available support for information organization. The manager’s taxonomy is essentially a hierarchical arrangement of categories together with rules for their application. At the top–level of this hierarchy are the categories depicted in Figure 4.
Figure 4: The top level of the taxonomy developed by an assistant and her manager.
The simplicity of this taxonomy is a virtue. It is supported by existing tools. Its rules of application are easy to learn, easy to communicate (to the new assistant, for example) and can be easily and consistently followed (by both manager and assistant). More than just schema for organizing the manager’s information, the taxonomy establishes the more important divisions among the many activities that the manager pursues. The taxonomy provides a way of understanding these activities and how they relate to one another. The taxonomy also provides a basis for communication between the manager and his assistant.
The taxonomy that the assistant and her manager created to organize the manager’s information can be called a Personal Unifying Taxonomy or PUT. A PUT has the following characteristics:
- A PUT is personal. Each person’s PUT is unique and customized to his or her needs.
- A PUT is unifying in its completeness. A PUT can be used as is or with small extensions, to classify and organize a person’s information regardless of form. For example, e–mail, e–documents and paper documents shared by the assistant and her manager all had the same top–level structure illustrated in Figure 4. Sub–folders were used to provide additional, finer grained organization for e–documents.
- A PUT is a taxonomy. For the purposes of this article the words "taxonomy" and "classification scheme" are interchangeable. Implicit in the use of either term is the notion that there is an associated external representation and rules for its application which can be consistently followed.
The KFTF project ( http://kftf.ischool.washington.edu) is involved in a general exploration of PUTs, their development and use, and the problems and benefits that result. The effort is partly an exploration of supporting tools and technologies and partly an exploration of techniques and guidelines. One line of exploration, for example, is to understand the possible importance of a facilitator’s role (as played by the assistant, for example) in helping a person create a PUT.
Where am I going? What information do I need?
One possibility is that portions of a PUT, with tool support, might usefully reflect task/sub–task (goal/sub–goal) decompositions for various activities in a person’s life. This direction follows from the ideal of PIM presented at the outset of this article — "information in the right place, at the right time, to meet the current task." The KFTF project is exploring the proposition that personal information management and the personal management of activities (tasks, projects, goals) should merge, and that it makes little sense to discuss one without considering the other.
A PUT can then be more than just a basis for organizing existing personal information. A PUT with elements corresponding to activities (tasks the person wishes to complete, projects the person wishes to pursue, goals the person wishes to accomplish, etc.) is also an expression of information need.
Unfortunately, terms like "PIM," "project management," and "task management" are entangled with associations in the media which overly restrict their meaning. "PIM" software helps with scheduling and contact management. "Task management" or "project management" software provides structured support for assigning and tracking tasks, often in a group setting.
On a personal level, the management of goals, projects, tasks and supporting information ought to stand for something beyond these standard associations. At any point in time, a person must juggle between many different tasks, projects and activities relating to a variety of different areas: home and family, work and professional, civic and community, sports and leisure, various hobbies, general areas of interest, and so on.
Tasks (goals, projects) have a structure. This structure can help to organize and manage associated information as well as the tasks themselves. Consider the example in Figure 5, adapted from an interview with a research in one of the KFTF studies.
Figure 5: A classification of information according to the tasks for which it is needed.
The structure in Figure 5 represents a task decomposition. Italicized items represent tasks. The information items under a task represent the input to and outcome of the task. For example, under the Get hotel reservations item is a reference to Web information on hotel availability and pricing. Also under this task item is an e–mail message confirming reservations for a specific hotel.
In fact, Figure 5 depicts an idealization, not the reality. The researcher recognizes this as a representation of the way she would like to see her information organized. But the researcher’s information was actually scattered across many organizations: One for e–mail, another for Favorites, and another for e–documents.
These organizations only partially reflect the structure in Figure 5. (The structure for e–documents comes closest.) Actual labels were not as task–oriented as those in Figure 5. Instead of "Attend Interact ’03 conference" for example, the researcher had an e–document folder labeled "Interact03" and an e–mail folder labeled simply "conferences" (sorted by "date"). In another part of her folder hierarchy for e–documents was a folder labeled "expense reports" which was apparently no longer in active use (no files with a "last modified" date past June of 2001 and no shortcuts to other files).
So the researcher’s real world of information is not nearly as tidy as the task structure depicted in Figure 5. In the real world, folder structure often emerges in an ad hoc "bottom–up" fashion as demanded by the immediate situation. Should it be? Consider the following alternate scenario involved the use of a PUT:
- The researcher after deciding to attend Interact ’03 does a "structure–only" copy from another conference she attended in 2002 (say CHI ’02). She changes the label (from "attend CHI ’02" to "attend Interact ’03") and adds a task for "get authorization for international travel." Otherwise, she’s set to go. She can begin filling up the structure with content specific to her participation in Interact ’03.
- Later, the researcher has time to work on her paper submission. She might browse to the task "Submit paper." Alternatively, she might do a "contains" auto–complete to go directly to the information associated with the paper submission. (The "begins with" auto–complete of a Web browser like the Microsoft Internet Explorer would be very cumbersome to use for direct access to nodes deeply nested in a hierarchy.) Similar mechanisms of browsing or "jumping" can be used when the researcher wishes to associate other information items to the "Submit paper" task.
- All information associated with the "Submit paper" task regardless of form and including sub–tasks, if there are any, is displayed in a single integrated view. This is a good thing since the researcher needs several different kinds of information in order to complete the task including e–mail correspondence with a co–author, drafts of the paper and Web–based conference information concerning submission format and deadlines [ 9].
- For the "Submit paper" element of her PUT (and for other elements as well) the researcher can provide values for task–relevant properties such as "due date" and "priority." The researcher may also set "remind me later" flags for more amorphous "piles" of information relating to areas of interest in her life.
- If the researcher creates a new document, a new e–mail message or if she browses to a new Web site in the context of the "Submit paper" task, these new information items are tagged automatically (but perhaps provisionally) with the corresponding element in the PUT.
- Later the researcher may want to view expense reports for all conferences she has attended so far in the year in order to determine if she is keeping within the budgets of her grants. This is easily done by an "upside/down" listing — all expense reports (lower nodes in the task hierarchy) are listed according to their conference parent nodes.
- Still later, the researcher turns her attention to the purchase of a new car. She has no previous "buy a new car" structure that she can copy to assist in the management of this new task and its associated information. However, in our future world where task and information management are integrated, she can do a structure copy from a friend’s representation. Or she might copy a "canned" task decomposition for car buying from the Web. Either way, the task structure might include subtasks such as "Get a loan," "Look for a dealer," "Get recent reviews," "Decide what features really matter to me," etc. and might also include useful Web references. Other canned task decompositions available for Web download might support activities like "Plan a wedding," "Buy a house," "Find a new job," etc.
This idealized scenario of PUT use covers all three assessments relating to the keeping decision:
- A PUT enables a better understanding of the information that is already available in a personal store.
The PUT provides the basis for a better, more consistent re–organization of existing stores (for e–mail, e–documents, paper documents, etc.). Even if the information remains scattered between these stores, this re–organization makes it easier to compare stores to determine what is and is not available.
- A PUT enables a better understanding of information needs — current and future — and the differences between available and needed information.
The categories of the PUT represent tasks (goals, projects, activities) that the person wants to accomplish. As Figure 5 illustrates, portions of a PUT may do double duty as both a task decomposition and as a way to organize information relating to the tasks in this decomposition. When information is organized in this way, discrepancies between the information needed and the information currently available become more apparent.
- A PUT enables a better understanding of the ways in which new information can help to reduce differences between available and needed information.
The conceptual use of a PUT in assessing the usefulness of newly encountered information follows directly from points 1 and 2. If people know clearly what information they have already and what information they will need, they can focus more directly on those aspects of the new information that might help to reduce discrepancies between needed and available information.
Into this sunny picture of PUT potential drift a few dark clouds of disclaimer. A PUT may not work for many people for any of a number of reasons. PUTs may turn out to be too difficult to develop, or to use and maintain on an ongoing basis. Many intended PUT owners, even if willing, may never accept the notion of a PUT and the changes it brings to information organization and habits of information management. People may never develop the discipline to make consistent use of a PUT. People may feel that a PUT is too constraining for their uses of information. And so on ... .
Whether or not these dark clouds rain on the parade of PUT potential is likely to depend upon a number of factors. Finding the right tools to support the development, maintenance and use of PUTs is clearly important. But techniques for the same may prove to be even more important. For example, what interviewing techniques are most effective at eliciting the information needed to construct a PUT? What guidelines apply to the construction of a PUT? Can a PUT’s owner follow these guidelines without external assistance? It is also important that a PUT’s complexity not outpace the available tool support. With today’s tool support, keep it simple — as in the example of Figure 4.
Better categories enable better tool support (and vice versa).
One objective in the creation of a PUT is the creation of better categories: Fewer grab bag categories like "stuff"; more categories like "Interact03" where all associated information is topically related. Some kinds of tool support are likely to get better with better categories whether or not the larger vision of PUTs is ever realized. This tool support, in turn, may lead to better, less error–prone keeping decisions.
- Semi-automated categorization. Centroids can be extracted or diagnostic features learned. These can then serve as filters for incoming information. In the MailCat system (Segal and Kephart, 1999), for example, users are given a list of candidate folders in which to place an information item (an e–mail message). Semi–automated categorization promises to make keeping decisions better as well as faster. Categories may, for example, be suggested that a person might otherwise have overlooked.
- Highlighting and summarization techniques can further call out those aspects of incoming information that seem most relevant to a category. For example, if "Interact03" is suggested as one category under which a new piece of information might belong, it should be possible to have relevant phrases highlighted in the information item (e.g., "Interact," "CHI," "human–computer interaction").
- An "Information inventory" of even a crude sort may have value if the categories of information classification are meaningful. Knowing that there are 14 files under a category (in a folder) called "stuff" is not particularly useful. Knowing that there 14 files in a category called "articles about task decomposition" is useful. Tool support hasn’t gotten smarter; the categories are just better. If categories of an information organization are meaningful, even a simple report indicating "amounts" and recency of information per category might have value. A person might tell at a glance which categories are "information light."
Conclusion
The keeping decision is fundamental to the management of personal information and fundamentally difficult to do. We make mistakes, and these mistakes can be costly. We keep information that turns out to be worse than useless — it gets in the way and may distract our attention from information that really is useful. We choose not to keep information that turns out to be important. We then suffer the extra time of finding this information again or, worse, we don’t find this information or forget about it altogether.
Excellent progress has been made to reduce the costs of keeping. The costs of electronic storage keep going down. Storage capacities keep increasing. User interactions with some information — with Web information, for example — are automatically recorded and the information cached. More will be. It is already possible to record nearly all interactions a user has with electronic information as well as to cache the information.
The costs of keeping mistakes are also decreasing. If people take no steps to keep Web information or a reference to this information, they can often easily return to this information anyway. People can use auto–complete. People can use a search service like Google. People can access it from another Web site. And if information is kept in the wrong way (misfiled, misplaced) commercial search utilities (Metz, 2003) or a utility such as in the Stuff I’ve Seen project (Dumais et al., 2003) can help.
But some costs still remain. These costs reflect fundamental limits in our ability to attend to things, in the time we have, and in our ability to remember to use information without prompting. Too much information can be nearly as bad as too little information. We can’t see the information we need for the clutter of other information that competes for our precious attention. We don’t re–find information later because we forget about its existence entirely.
If we are nearing the limits of what can be done to reduce the costs of keeping and keeping mistakes, we have barely begun to explore the potential to reduce the likelihoods of keeping mistakes in the first place. How can we make better keeping decisions? In the ideal, we keep only useful information and nothing else. And this information is filed, tagged or otherwise organized so that it is available later when we really need it.
About the Author
William Jones is an associate research professor in the Information School at the University of Washington. He has published basic research in cognitive psychology as well as more applied research into information retrieval and human/computer interaction. He currently manages the Keeping Found Things Found (KFTF) project ( http://kftf.ischool.washington.edu) in collaboration with Harry Bruce, Associate Dean of Research at the Information School.
E–mail: williamj@u.washington.edu
Acknowledgements
I wish to thank Harry Bruce, Susan Dumais, Jonathan Grudin, Steve Poltrock and Maria Staaf for helpful comments made on earlier versions of this article.
Notes
1. For recent reviews see Etzel and Thomas, 1996; Rosenberg, 1999; and, Blandford and Green, 2001.
2. See, for example, the recently released Microsoft OneNote application (Microsoft, 2003).
3. For a recent review see Metz, 2003.
4. See, for example, Swets, 1963; 1969.
5. See, for example, Tversky and Kahneman, 1974.
6. See, for example, the description of Microsoft’s WinFS storage system by Grimes, 2004.
7. See, for example, Malone, 1983; Whittaker and Sidner, 1996; and, Balter and Sidner, 2002.
8. See, for example, Bates, 1988.
9. See the "Haystack" project at http://haystack.lcs.mit.edu/, for an example of such an integrative, if somewhat complex, view.
References
D. Abrams, R. Baecker, and M. Chignell, 1998. "Information Archiving with Bookmarks : Personal Web Space Construction and Organization," Proceedings of the ACM SIGCHI Conference on Human Factors in Computing Systems (CHI 1998), Los Angeles, Calif., pp. 41–48.
O. Balter, 2000. "Keystroke Level Analysis of Email Message Organization," Proceedings of the ACM SIGCHI Conference on Human Factors in Computing Systems (CHI 2000), The Hague, Netherlands, pp. 105–112.
O. Balter and C.L. Sidner, 2002. "Bifrost Inbox Organizer: Giving Users Control over the Inbox," Proceedings of the Second Nordic Conference on Human–computer Interaction, pp. 111–118.
D.K. Barreau and B.A. Nardi, 1995. "Finding and Reminding: File Organization from the Desktop," SIGCHI Bulletin, volume 27, number 3, p. 7.
M.J. Bates, 1988. "How to Use Controlled Vocabularies More Effectively in Online Searching," Online Review, volume 12, number 6 (November), pp. 45–56.
V. Bellotti, N. Ducheneaut, M. Howard, and I. Smith, 2003. "Taking Email to Task: The Design and Evaluation of a Task Management Centered Email Tool," Proceedings of the Conference on Human Factors in Computing Systems (CHI 2003), Ft. Lauderdale, Fla., pp. 345–352.
V. Bellotti, N. Ducheneaut, M. Howard, C. Neuwirth, and I. Smith, 2002. "Innovation in Extremis: Evolving an Application for the Critical Work of Email and Information Management," Proceedings of the Conference on Designing Interactive Systems (DIS2002), London, pp. 181–192.
V. Bellotti and I. Smith, 2000. "Informing the Design of an Information Management System with Iterative Fieldwork," Proceedings of the Conference on Designing Interactive Systems (DIS 2000), New York, New York, pp. 227–237.
O. Bergman, R. Beyth–Marom, and R. Nachmias, 2003. "The user–subjective approach to personal information management systems," Journal of the American Society for Information Science and Technology (JASIST), volume 54, number 9, pp. 872–878.
A. Blandford and T. Green, 2001. "Group and Individual Time Management Tools: What You Get Is Not What You Need," Personal and Ubiquitous Computing, volume 5, number 4 (December), pp. 213–230.
R. Boardman, M. A. Sasse, and B. Spence, 2002. "Life Beyond the Mailbox: A Cross–Tool Perspective on Personal Information Management," Proceedings of the CSCW 2002 Workshop: Redesigning Email for the 21st Century, New Orleans, La.
H. Bruce, W. Jones, and S. Dumais, 2004. "The Pain Hypothesis," submitted to Journal of the American Society for Information Science and Technology (JASIST).
M.D. Byrne, B.E. John, N.S. Wehrle, and D.C. Crow, 1999. "The Tangled Web We Wove: A Taskonomy of WWW Use," Proceedings of the Conference on Human Factors in Computing Systems (CHI 1999), Pittsburgh, Pa., pp. 544–551.
J.M. Carroll, 1982. "Creative Names for Personal Files in an Interactive Computing Environment," International Journal of Man–Machine Studies, volume 16, number 4, pp. 405–438.
D.O. Case, 1986. "Collection and Organization of Written Information by Social Scientists and Humanists: A Review and Exploratory Study," Journal of Information Science, volume 12, number 3, pp. 97–104.
L.D. Catledge and J.E. Pitkow, 1995. "Characterizing Browsing Strategies in the World–Wide Web," Proceedings of the Third International World Wide Web Conference (WWW 1995), Darmstadt, Germany, pp. 1065–1073.
P. Dourish, W.K. Edwards, A. LaMarca, J. Lamping, K. Petersen, M. Salisbury, D. B. Terry, and J. Thornton, 2000. "Extending Document Management Systems with User-Specific Active Properties," ACM Transactions on Information Systems, volume 18, number 2, pp. 140–170.
P. Dourish, W.K. Edwards, A. LaMarca, and M. Salisbury, 1999. "Presto: An Experimental Architecture for Fluid Interactive Document Spaces," ACM Transactions on Computer–Human Interaction, volume 6, number 2, pp. 133–161.
N. Ducheneaut and V. Bellotti, 2001. "E–mail as Habitat," Interactions, volume 8, number 5, pp. 30–38.
S. Dumais, E. Cutrell, J. Cadiz, G. Jancke, R. Sarin, and D. Robbins, 2003. "Stuff I’ve Seen: A System for Personal Information Retrieval and Re–use," Proceedings of the 26th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR 2003), pp. 72–79.
S. Erdelez and K. Rioux, 2000. "Sharing Information Encountered for Others on the Web," New Review of Information Behaviour Research, volume 1, pp. 219–233.
B. Etzel and P. Thomas, 1996. Personal Information Management: Tools and Techniques for Achieving Professional Effectiveness. New York: New York University Press.
S. Fertig, E. Freeman, and D. Gelernter, 1996. "Lifestreams: An Alternative to the Desktop Metaphor," Proceedings of the Conference on Human Factors in Computing Systems (CHI 1996), Vancouver, B.C., pp. 410–411.
E. Freeman and D. Gelernter, 1996. "Lifestreams: A Storage Model for Personal Data," ACM SIGMOD Record (ACM Special Interest Group on Management of Data), volume 25, number 1, pp. 80–86.
J. Gemmell, G. Bell, R. Lueder, S. Drucker, and C. Wong, 2002. "Mylifebits: Fulfilling the Memex Vision," Proceedings of the 2002 ACM workshops on Multimedia, pp. 235–238.
R. Grimes, 2004, "Revolutionary File Storage System Lets Users Search and Manage Files Based on Content," at http://msdn.microsoft.com/longhorn/understanding/pillars/winfs/default.aspx?pull=/msdnmag/issues/04/01/WinFS/default.aspx, accessed 12 February 2004.
J. Gwizdka, 2002a. "Reinventing the Inbox: Supporting the Management of Pending Tasks in Email," Proceedings of the CHI 2002: ACM SIGCHI Conference on Human Factors in Computing Systems, Doctorial Consortium, Minneapolis, Mn., pp. 550–551.
J. Gwizdka, 2002b. "Taskview: Design and Evaluation of a Task–Based Email Interface," Proceedings of the 2002 Conference of the Centre for Advanced Studies on Collaborative Research, at https://www-927.ibm.com/ibm/cas/archives/2002/papers/cascon02/htm/english/abs/gwizdka.htm, accessed 29 February 2004.
J. Gwizdka, 2000. "Timely Reminders: A Case Study of Temporal Guidance in PIM and Email Tools Usage," Proceedings of the Conference on Human Factors in Computing Systems (CHI 2000), The Hague, Netherlands, pp. 163–164.
"Haystack," at http://haystack.lcs.mit.edu/, accessed 12 February 2004.
W. Jones and D. Maier, 2003. "Report from the Session on Personal Information Management," Workshop of the Information and Data Management Program, National Science Foundation.
W. Jones, H. Bruce, and S. Dumais, 2003. "How Do People Get Back to Information on the Web? How Can They Do It Better?," Proceedings of the 9th IFIP TC13 International Conference on Human–Computer Interaction (INTERACT 2003), Zurich, Switzerland, at kftf.ischool.washington.edu/ interact03%20presentation,%20v2.ppt, accessed 29 February 2004.
W. Jones, S. Dumais, and H. Bruce, 2002. "Once Found, What Then? A Study of ‘Keeping’ Behaviors in the Personal Use of Web Information," Proceedings of the 65th Annual Meeting of the American Society for Information Science and Technology (ASIST 2002), Philadelphia, Pa., pp. 391–402.
W. Jones, H. Bruce, and S. Dumais, 2001. "Keeping Founds Things Found on the Web," Proceedings of the Tenth International Conference on Information and Knowledge Management (CIKM 2001), Atlanta, Ga., pp. 119–126.
B.H. Kwasnik, 1989. "How a Personal Document’s Intended Use or Purpose Affects Its Classification in an Office," Proceedings of the 12th Annual ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR 1989), Cambridge, Mass., pp. 207–210.
M. Lansdale, 1988. "The Psychology of Personal Information Management," Applied Ergonomics, volume 19, number 1, pp. 55–66.
W.E. Mackay, 1988. "Diversity in the Use of Electronic Mail: A Preliminary Inquiry," ACM Transactions on Office Information Systems, volume 6, number 4, pp. 380–397.
T.W. Malone, 1983. "How Do People Organize Their Desks: Implications for the Design of Office Information-Systems," ACM Transactions on Office Information Systems, volume 1, number 1, pp. 99–112.
G. Marchionini, 1995. Information Seeking in Electronic Environments. New York: Cambridge University Press.
C. Metz, 2003. "Conquer Information Overload," PC Magazine (8 April), at http://www.pcmag.com/article2/0,4149,932965,00.asp, accessed 29 February 2004.
Microsoft, 2003. Onenote 2003 Product Guide. Redmond, Wash.: Microsoft, at http://www.microsoft.com/office/onenote/prodinfo/guide.mspx, accessed 29 February 2004.
V. O’Day and R. Jeffries, 1993. "Orienteering in an Information Landscape: How Information Seekers Get from Here to There," Proceedings of the ACM SIGCHI Conference on Human Factors in Computing Systems (CHI 1993), pp. 438–445.
W.W. Peterson, T.G. Birdsall, and W.C. Fox, 1954. "The Theory of Signal Detectability," Institute of Radio Engineers Transactions, volume PGIT-4, pp. 171–212.
S. Rosenberg, 1999. "Personal Information Mismanagement: Why Hasn’t the Software Industry Given Us More Tools to Get Our Lives in Order?" Salon 21st (5 March), p. 6, and at http://archive.salon.com/21st/rose/1999/03/05straight.html, accessed 29 February 2004.
R.B. Segal and J.O. Kephart, 1999. "Mailcat: An Intelligent Assistant for Organizing E–Mail," Proceedings of the The Third Annual Conference on Autonomous Agents, pp. 276–282.
A.J. Sellen and R.H.R. Harper, 2002. The Myth of the Paperless Office. Cambridge, Mass.: MIT Press.
S.G. Steinberg and D. Gelernter, 1997. "Lifestreams," Wired, volume 5, number 2 (February), p. 12.
J.A. Swets, 1969. "Effectiveness of Information Retrieval Methods," American Documentation, volume 20, number 1, pp. 72–89.
J.A. Swets, 1963. "Information Retrieval Systems," Science and Technology Libraries, volume 141, pp. 245–250.
L.M. Tauscher and S. Greenberg, 1997a. "How People Revisit Web Pages: Empirical Findings and Implications for the Design of History Systems," International Journal of Human–Computer Studies, volume 47, number 1, pp. 97–137.
L.M. Tauscher and S. Greenberg, 1997b. "Revisitation Patterns in World Wide Web Navigation," Proceedings of the Conference on Human Factors in Computing Systems (CHI 197), Atlanta, Ga., pp. 399–406.
J. Teevan, 2003. ""Where’d It Go?" Re–Finding Information in the Changing Web," Proceedings of the MIT Laboratory for Computer Science and MIT Artificial Intelligence Laboratory (MIT LCS/AI) Student Oxygen Workshop, Gloucester, Mass., at http://sow.lcs.mit.edu/2003/proceedings/Teevan.pdf, accessed 29 February 2004.
A. Tversky and D. Kahneman, 1974. "Judgments under Uncertainty: Heuristics and Biases," Science and Technology Libraries, volume 185, pp. 1124–1131.
D. Van Meter and D. Middleton, 1954. "Modern Statistical Approaches to Reception in Communication Theory," Institute of Radio Engineers Transactions, volume PGIT-4, pp. 119–145.
S. Whittaker and J. Hirschberg, 2001. "The Character, Value and Management of Personal Paper Archives," ACM Transactions on Computer–Human Interaction, volume 8, number 2, pp. 150–170.
S. Whittaker and C. Sidner, 1996. "Email Overload: Exploring Personal Information Management of Email," Proceedings of the Conference on Human Factors in Computing Systems (CHI 1996), Vancouver, B.C., pp. 276–283.
E.V. Wilson, 2002. "Email Winners and Losers," Communications of the ACM, volume 45, number 10, pp. 121–126.
Editorial history
Paper received 19 February 2004; accepted 27 February 2004.


Copyright ©2004, First Monday
Copyright ©2004, William Jones
Finders, keepers? The present and future perfect in support of personal information management by William Jones
First Monday, volume 9, number 3 (March 2004),
URL: http://firstmonday.org/issues/issue9_3/jones/index.html