Search engines are unreliable tools for data collection for research that aims to reconstruct the historical record. This unreliability is not caused by sudden instabilities of search engines. On the contrary, their operational stability in systematically updating the Internet is the cause. We show how both Google and Altavista systematically relocate the time stamp of Web documents in their databases from the more distant past into the present and the very recent past. They also delete documents. We show how this erodes the quality of information. The search engines continuously reconstruct competing presents that also extend to their perspectives on the past. This has major consequences for the use of search engine results in scholarly research, but gives us a view on the various presents and pasts living side by side in the Internet.Contents
Introduction
Time and search engines
Research questions
The setup of the experiment
Experimental results
Discussion
Conclusion
Introduction
Internet search engines reconstruct the past by updating their indices. This reconstruction does not follow the historical axis of time. While historical analyses aim to reconstruct the developments chronologically, search engines renew the time stamp of Web pages on the basis of the most recent update. In other words, search engines entertain a model of the Internet that evolves with the Internet. Under certain conditions such an evolution can become self–organizing. Unlike self–organization in biological systems, the historical traces of the development are overwritten by search engines to such an extent that they can only be retrieved artificially on the basis of a systematic research design.
In this project we attempt to test this hypothesis using AltaVista and Google as "clocks of the Internet" for searches at different moments of time. Search engines are an obligatory point of passage in Internet research as there is no unmediated access to the Web. The central issue is the reliability of social science data produced by search engines. The difference between the evolutionary and historical dynamics can be measured in terms of the "short" and "long" term memories of the search engines. We show that both the retrieval of information and the quality of information retrieved erodes over time.
Time and search engines
Societies reconstruct themselves by reconstructing their histories. This is a constant process of mutual adaptation between historical traditions and institutions on the one side, and emerging expectations of both future and past on the other (Schütz, 1932). Both the duration of activities and processes and the way they are synchronized and updated affect the position of agents in the network. The network development itself can be considered as an interplay and interaction effect among the different temporalities (Innis, 2004; Nowotny, 1989). In terms of systems theory, this can be understood as the interference between different updating frequencies of the subsystems in society.
For example, the subsystem of science publishes scientific results with a frequency that differs greatly from that of daily newspapers. Similarly, some Web pages are updated with a higher frequency than others, and different search engines update their indexes with structurally different frequencies (Thelwall, 2001). The focus on temporality enables the analysis of socio–technical systems in which technical constructs are both functioning as nodes and as media embedding the relationships between the nodes of the network (Latour, 1988; Leydesdorff, 1994, 2001).
Internet search engines continuously reconstruct the past by updating their indices.
The study of updating cycles has an especially salient relevance to search engines. Some search engines (AltaVista and Google) can be used to search for information from certain periods of time. However, these "date stamps" are not determined by the first occurrence of these pages in the Web, but by the last date at which a page was updated. The "same" Web page may therefore belong to the year 1995 in a data set collected in 2003, while in a data set collected in 2004 it belongs to the year 2003. If used to search with historical dates, search engines represent the results of interacting frequencies of the updating of Web pages and search engine crawlers, and not necessarily the dates of publication of the documents under study.
Internet search engines continuously reconstruct the past by updating their indices. While the development of the engines remains historical, their dynamics evolve in the present and reflexively to the system to which they belong. Thus, these engines invert the time axis and enable the user to reconstruct a history by looking backwards (Dubois, 1998; Rosen, 1985). Because of the updating effect, this reconstruction will tend to draw Web sites into the most recent past, thus possibly erasing the older representations of that particular Web site. This also means that search engines tend to lose their history while evolving in the present. Yet it remains possible to systematically archive the indices of the different search engines or build up an independent Internet archive (e.g., the Internet Archive at http://web.archive.org).
Research questions
In this study we attempt to test the hypothesis that search engines rewrite the past, and obliterate this past in the process. We used the search engines of AltaVista and Google comparatively and for searches at different moments in time. Our aim is to specify the extent to which, and how, the past is overwritten. We focus on two major search engines that provide the option to limit searches to specific dates. AltaVista’s Advanced Search Engine ( www.altavista.com/web/adv) allows searches from the year 1980 to the present, limited to specific months, dates or years. Google is currently the most frequently used and largest search engine ( www.searchengineshowdown.com). It provides the option for similar time limited searches via Google’s APIs and Faganfinder (www.faganfinder.com) which exploits Google’s database [ 1].
Originally, we planned to provide search results with a one–year time interval (January 2003 versus January 2004) and a one–month time interval (January 2004 and February 2004). During our study, in April 2004, AltaVista adopted the Yahoo! search engine. After this, the number of hits became considerably lower, and we decided to generate an additional point at the end of April 2004, that is, three months after the searches in January 2004.
We are interested in two related questions. One is the set of methodological problems encountered when using search engines to gather data and construct time series. Because of the updating mechanisms operating it can no longer be assumed that time series data would reflect historical developments of the systems under study. This raises the question of whether one can construct time series data by periodically searching the Web for a specific string of characters. What is the extent to which these results can be reproduced?
The second question is related. If one cannot interpret a data set of a specific search using the date stamps of the search engine in a historical or traditional sociological way, how can the changes be interpreted? It seems too easy to conclude that this type of data is worthless, since the "errors" are generated systematically. Although one expects similar mechanisms of change in social systems — not only the data change, but also the meanings of the data — the updating of Web pages provide us with an empirical domain in which to study this mechanism. The mechanism represents a significant socio–technical activity on the Web.
The setup of the experiment
Our experiments focus on how two major search engines, AltaVista and Google, have reconstructed the Web pages on "Frankenfoods" over time. The metaphor of "Frankenfoods" was used on the Web in the debate on genetically modified foods from the mid–1990s onwards in pages of various consumer and environmental organizations, in discussion forums and newsletters, as well as in political arenas and journalistic accounts of the debate. The use of the metaphor in these arenas on the Web reached its peak between 1998 and 2000, after which its use rapidly decreased (Hellsten, 2003). Thus this topic provides us with regularly updated and heavily contested data.
The data was initially collected on 21–23 January 2003 using only the AltaVista advanced search engine. The searches were limited to the years 1995–2002. This data collection was repeated exactly after one year, i.e. on 21–23 January 2004, and then after one month, i.e. on 21–23 February 2004, and after three months, i.e. 21-23 April 2004 using both AltaVista and Google, and including the year 2003. The results for the year 2003 were further broken down into the constituent twelve months in order to be able to distinguish between the long–term and short–term effects in greater detail (see Hellsten, Leydesdorff, and Wouters, in preparation).
The user interfaces of the two search engines are different and they provide different options for using search terms. With AltaVista we originally used the search string frankenfood* OR (frankenstein AND food*) for the retrieval. In order to be able to use the date range capability of Google, we used the FaganFinder interface to Google at http://www.faganfinder.com/google.html. This interface transforms normal date ranges into the ones which Google can handle. However, the interface does not allow the combination of Boolean operators and the * placeholder does not function in the "exact phrase" option. For this reason, the original search string was split into three versions, for which we collected the results separately and pooled them afterwards: frankenstein food, frankenstein foods and frankenfood(s) [ 2]. In order to compare the results of Google with AltaVista, we also used the following string in AltaVista: frankenstein food* OR frankenfood* for the three searches in 2004.
We not only checked the reported number of hits of each of the search engines, but also downloaded the search results pages. These pages contain the titles, first sentences, document types, and URLs. This material allows us to check how many of the reported results could actually be retrieved from the Internet. More importantly, the titles provide us with a semantic domain that can be mapped and visualized in order to see how the words used are positioned and whether the clusters of words change from one data collection to another. We use techniques that we developed for this purpose in other contexts (Leydesdorff, 2004) and provide the visualizations below in order to illustrate our arguments with substantive interpretations [ 3].
Our expectation about the time representation by the search engines can be formulated as follows. First, we expect that the distribution of the reported number of hits over the preceding years will show a strong bias in favour of the latest year (relative to the date of the measurement). We call this the long term memory of search engines. Second, if it is true that Web sites are continuously overwritten with newer date stamps, then we expect a decrease in the total number of hits for the months before the last one (again relative to the date of the measurement). We call this the short term memory.
Additionally, we test if the decrease with the progress of time also means that the structure in the data is eroded. This design enables us to study the construction of time both in terms of changes in the reported numbers of results per year and the actually retrieved results. The downloaded numbers are in most cases lower than the reported numbers of results. We use the reported numbers for the short and the long term memory, while the semantic maps are based on the actually retrieved results.
Experimental results
Search engine memory
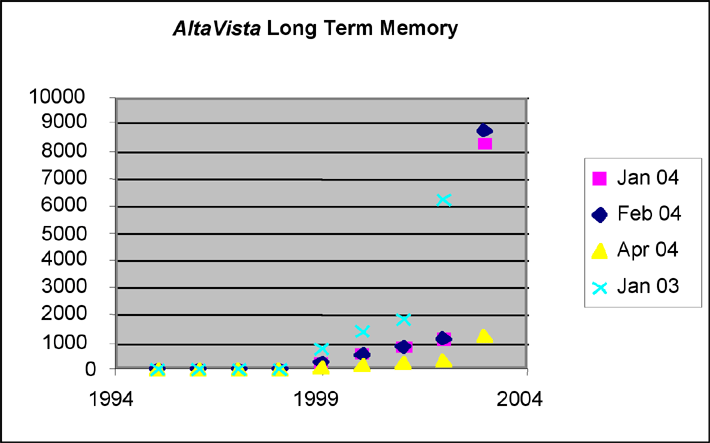
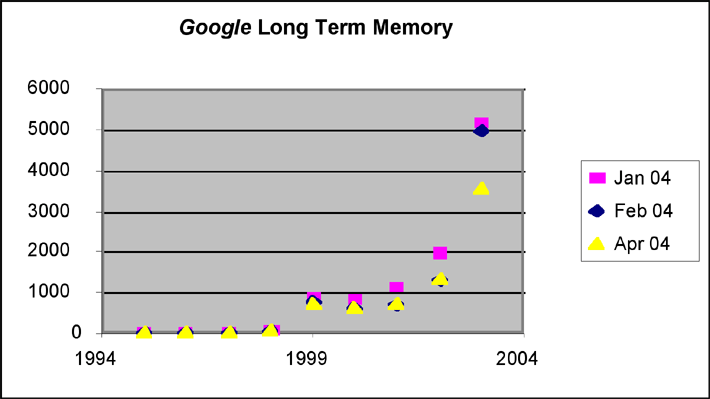
Figures 1 and 2: Search results using ‘frankenfood* OR frankenstein food*’ as search terms in Google and AltaVista.
The figures show that both AltaVista and Google have a strong and consistent bias towards the latest year. For the measurement in January 2003, the year 2002 was the most recent year, hence this distribution is shifted one year to the left (Figure 1). The data also prove that AltaVista and Google both overwrite their histories. The number of hits recorded by AltaVista decreases over time (from January 2003 until and including April 2004). The sharpest fall is seen in the year 2002 which can be attributed to a massive updating of Web pages from that year in the year 2003. Google hits decrease from January to April 2004 for all years. Except for the most recent year, the numbers in February and April are at the same level. (The AltaVista hits in April 2004 are orders of magnitude lower because of the change to the engine of Yahoo!.)
The short term memory shows essentially the same updating mechanism and loss of the historical record, with a small difference here between Google and AltaVista [ 4].
Substantive similarities and differences
We also expected that the structure of the Web pages would differ across the searches at different points in time. After all, if documents are relocated to a more recent year, the existing structure of documents within one year is disrupted. As this relocation will not be uniform for all documents, a shift of the structure as a whole into a more recent year is highly unlikely. Our expectation is therefore that the structure as represented by co–appearances in the titles of Web pages in a particular year erodes over time. As a result, the information in the structure gets gradually lost.
To study this, we calculated correlation coefficients, and drew semantic maps based on the co–occurrences of words in the titles of the retrieved documents. The semantic maps are based on asymmetrical matrices of words, where co–occurring words are used as variables and the documents are used as cases. These matrices were imported into Ucinet and the visualizations were made with Pajek [ 5].
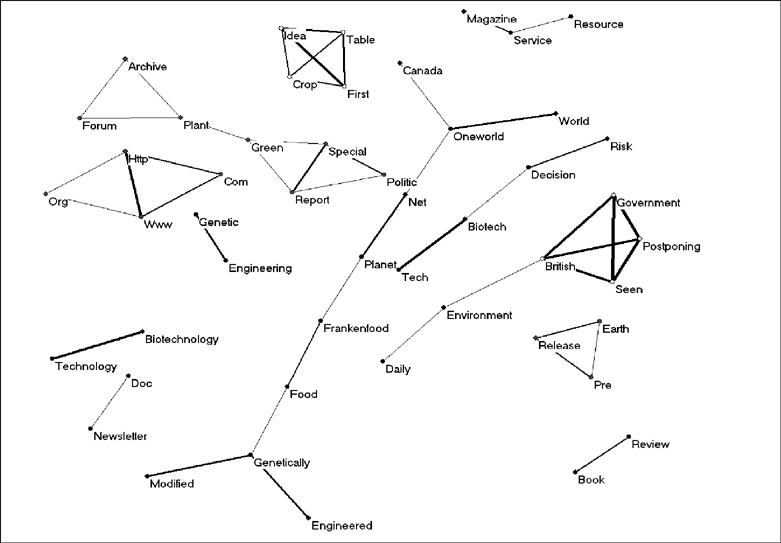
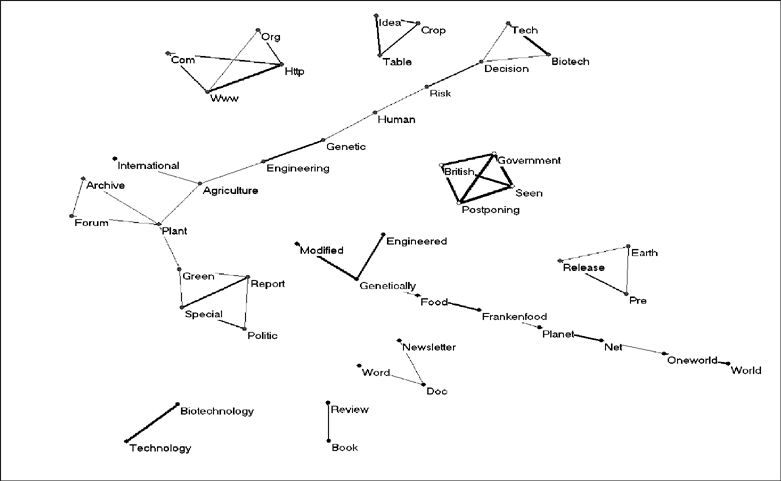
The next two figures show the structure of the title words that co–occurred more than 12 times. The semantic maps are based on the searches conducted with AltaVista in January and February 2004 and represent the results date stamped to year 2003 (Figures 3 and 4).
Figure 3: Forty–nine words related at the level of cosine ≥ 0.2 and occurring more than 12 times in 2,035 records collected with the AltaVista advanced search engine in February 2004.
Figure 4: Forty–six words related at the level of cosine ≥ 0.2 and occurring more than 12 times in 2,106 records collected with the AltaVista advanced search engine in January 2004.
This picture of January (Figure 4) is more informative than the one from February (Figure 3) because of the erosion of structure in the data over time. The number of unconnected clusters increases. This confirms the expectation that search engines gradually shed structure. The development of the structure in the maps based on the Google data confirms this erosion of structure in the semantic networks [ 6].
Discussion
The results confirm both of our hypotheses. The past in the Internet is constantly overwritten by search engines. This affects the numbers of results as well as the actual Web pages that the search engines retrieve. The present, from where the data is collected, affects search results considerably. Search engines not only lose information quantitatively, but they also erase the structure entailed in the relationships between words in the titles of the Web pages.
What does this mean for reliability of search engines in the context of social science research? Earlier research has shown that search engines are problematic tools for data collection because of different types of instabilities (Bar–Ilan, 1999; Rousseau, 1999; Wouters and Gerbec, 2003). However, in this study we are not primarily dealing with instabilities. On the contrary, in many ways the updating mechanisms of search engines are remarkably stable and systematic. This is not to say that we did not meet sometimes irritating instabilities. A major example was the fundamental restructuring of AltaVista in April 2004 which made its results before and after the reorganisation unrelated. We also experienced a variable difference between the reported number of records and the number of records that actually could be retrieved.
We interpret search engines as the clocks of the Internet, by their representation of the updating frequencies of both the Web and the underlying Internet.
The main phenomenon on which we focused in our experiments is not the instability but the systematic erasure of both the historical record and the structure in informational and semantic networks. This is caused by the fact that search engines are tied to updating cycles of the Web and the Internet, rather than to the historical development of their structure. As a result, search engines are unreliable for data collection for most social science research. The construction of tailor–made archiving and crawling tools seems, therefore, urgent if one wishes to retain either structural or historical information on the Internet.
This does not mean that search engines are completely useless or do not represent a significant phenomenon on the Web. On the contrary, it confirms that we can interpret search engines as the clocks of the Internet, by their representation of the updating frequencies of both the Web and the underlying Internet. How should we interpret this? It should be stressed that there is not one single updating frequency on the Web. We are instead dealing with complex interactions of, among others:
- the updating frequency of individual Web pages by their author or Web master;
- the updating frequency and mechanism of the structure in which these Web pages are positioned;
- the frequency with which these Web pages are being visited by search engine crawlers;
- the updating frequency of the search engine databases;
- the extent to which "old" Web pages are retained in search engine databases despite more recent versions of that "same" Web page having been added;
- and, the updating frequency of the sorting algorithm of the search engine and its presentation mechanisms.
All these frequencies can be expected to differ. In addition, each search engine will be influenced in different ways by the various frequencies.
Each search engine can therefore be said to represent not one updating frequency but a frequency distribution or a spectrum (including very slow changes). The spectrum may be specific for the search engine in a particular period of its existence.
Conclusion
We have shown that the search engines AltaVista and Google systematically relocate the time stamp of Web documents in their databases from the more distant past into the present and the very recent past. Second, they also delete documents from the year they were initially assigned to. This leads to the loss of information in the historical record on the Web as represented in the search engine databases. Third, information also gets lost in the sense of loss of structure in the semantic networks. Both Google and AltaVista "shed structure" as the consequence of the differential frequencies with which documents get their time–stamps updated.
This has major consequences for the use of search engines in social science research. In short, search engines are unreliable tools for data collection for research that aims to reconstruct the historical record or for research that aims to analyze the structure of information at a particular moment in history. Only those Web pages that contain the date of the publishing document in question (for example, in various Web archives and citation index databases), can be used for this purpose (Hellsten, 2003). This unreliability is not caused by sudden instabilities of search engines, but precisely by their operational stability in systematically updating the Internet. For many types of social science research, it is therefore necessary to build ‘tailor made’ archiving tools that are not based on the available commercial search engines.
Search engines are unreliable tools for data collection for research that aims to reconstruct the historical record or for research that aims to analyze the structure of information at a particular moment in history.
We have also interpreted search engines as the clocks of the Internet, driven by the interaction between the different updating frequencies. We have shown in our experiment that these clocks not only run at different frequencies depending on the ‘present’ of the searches and the search engine in question, but also reconstruct the past in very different terms. Each search engine differs in the combination of these frequencies and their selection, resulting in different lag times and information restructuring windows. This question of how we can make more use of search engines to unveil the overall updating cycles that dominate the Web and particular domains of the Web must therefore be put on the agenda as an interesting research question. The different search engines continuously reconstruct competing presents that also extend to their perspectives on the past. This has major consequences for the use of search engine results in scholarly research, but gives us a view on the various presents and pasts living side by side in the Internet.
About the authors
Paul Wouters is Programme Leader at Networked Research and Digital Information ( Nerdi), Royal Netherlands Academy of Arts and Sciences; direct communications to: paul.wouters@niwi.knaw.nl.
Iina Hellsten is Researcher at Networked Research and Digital Information ( Nerdi), Royal Netherlands Academy of Arts and Sciences.
E–mail: iina.hellsten@niwi.knaw.nl.Loet Leydesdorff is a member of the faculty of the Amsterdam School of Communication Research (ASCoR), University of Amsterdam.
Web: http://www.leydesdorff.net
E–mail: loet@leydesdorff.net.
Acknowledgements
We would like to thank Mike Thelwall and Henk Harmsen for their comments on previous drafts. We thank our colleagues at Nerdi for the inspiring intellectual context they provide.
Notes
1. Google uses the Julian calendar, but FaganFinder automatically converts calendar dates into this older time scale.
2. We also tested the string frankenstein AND food in Google, but this generated too many pages about Frankenstein movies where one could also eat in relation to the number of pages about the debate on genetically modified food.
3. The mappings are based on using the so-called vector-space-model for the analysis and Pajek for the visualization. Pajek is available at http://vlado.fmf.uni-lj.si/pub/networks/pajek/.
4. For more details, see Hellsten, Leydesdorff, and Wouters (in preparation).
5. For information on the methods see Leydesdorff (2004) and Hellsten and Leydesdorff (2004).
6. For more details, see Hellsten, Leydesdorff, and Wouters (in preparation).
References
J. Bar–Ilan, 1999. "Search engine results over time: A case study on search engine stability," Cybermetrics, volume 2/3, issue 1, at http://www.cindoc.csic.es/cybermetrics/vol2iss1.html, accessed 3 September 2004.
D.M. Dubois, 1998. "Computing anticipatory systems with incursion and hyperincursion," In: D.M. Dubois (editor). Computing Anticipatory Systems: CASYS–First International Conference, Liège, Belgium, August 1997. AIP Conference Proceedings, volume 437. Woodbury, N.Y.: American Institute of Physics, pp. 3–29.
I. Hellsten, 2003. "Focus on metaphors: The case of ‘Frankenfood’ on the Web," Journal of Computer–Mediated Communication, volume 8, number 4, at http://www.ascusc.org/jcmc/vol8/issue4/, accessed 3 September 2004.
I. Hellsten and L. Leydesdorff, 2004. "Measuring the meanings of co–words in contexts: Automated analysis of ‘monarch butterflies’, ‘frankenfoods’, and ‘stem cells’," paper presented at the Conference of Research Council 33 of the International Sociological Association, 17–21 August 2004, Amsterdam.
I. Hellsten, L. Leydesdorff and P. Wouters (in preparation). "Re–writing the past: How search engines construct and forget time."
H.A. Innis, 2004. Changing concepts of time. Oxford: Rowman & Littlefield.
B. Latour, 1988. The pasteurization of France. Translated by Alan Sheridan and John Law. Cambridge, Mass.: Harvard University Press.
L. Leydesdorff, 2004. "The university–industry knowlege relationship: Analyzing patents and the science base of technologies," Journal of the American Society for Information Science & Technology, volume 55, number 11, pp. 991–1001.
L. Leydesdorff, 2001. A sociological theory of communication: The self–organization of the knowledge–based society. Parkland, Fla.: Universal Publishers; at http://www.upublish.com/books/leydesdorff.htm, accessed 11 September 2004.
L. Leydesdorff, 1994. "Uncertainty and the communication of time," Systems Research, volume 11, number 4, pp. 31–51.
H. Nowotny, 1989. Eigenzeit: Entstehung und strukturierung eines zeitgefühls. Frankfurt am Main: Suhrkamp.
R. Rosen, 1985. Anticipatory systems: Philosophical, mathematical and methodological foundations. Oxford: Pergamon Press.
R. Rousseau, 1999. "Daily time series of common single word searches in AltaVista and Northernlight," Cybermetrics, volume 2/3, issue 1, at http://www.cindoc.csic.es/cybermetrics/articles/v2i1p2.html, accessed 11 September 2004.
A. Schütz, 1932. Der sinnhafte aufbau der sozialen welt: Eine einleitung in die verstehende soziologie. Vienna: J. Springer.
M. Thelwall, 2001. "The responsiveness of search engine indexes," Cybermetrics, volume 5, issue 1, at http://www.cindoc.csic.es/cybermetrics/articles/v5i1p1.html, accessed 11 September 2004.
P. Wouters and D. Gerbec, 2003. "Interactive Internet? Studying mediated interaction with publicly available search engines," Journal of Computer–Mediated Communication, volume 8, number 4, at http://www.ascusc.org/jcmc/vol8/issue4/, accessed 3 September 2004.
Editorial history
Paper received 5 September 2004; accepted 10 September 2004.


Copyright ©2004, First Monday
Copyright ©2004, Paul Wouters, Iina Hellsten, and Loet Leydesdorff
Internet time and the reliability of search engines by Paul Wouters, Iina Hellsten, and Loet Leydesdorff
First Monday, volume 9, number 10 (October 2004),
URL: http://firstmonday.org/issues/issue9_10/wouters/index.html