Do Web search engines suppress controversy? by Susan L. GerhartWeb behavior depends upon three interlocking communities: (1) authors whose Web pages link to other pages; (2) search engines indexing and ranking those pages; and (3) information seekers whose queries and surfing reward authors and support search engines. Systematic suppression of controversial topics would indicate a flaw in the Web’s ideology of openness and informativeness. This paper explores search engines’ bias by asking: Is a specific well–known controversy revealed in a simple search? Experimental topics include: distance learning, Albert Einstein, St. John’s Wort, female astronauts, and Belize. The experiments suggest simple queries tend to overly present the "sunny side" of these topics, with minimal controversy. A more "Objective Web" is analyzed where: (a) Web page authors adopt research citation practices; (b) search engines balance organizational and analytic content; and, (c) searchers practice more wary multi–searching.
Contents
Understanding Web behavior: Politics, technology and users
Why does visibility of controversy matter?
Case studies of controversial topics
Summary of case studies: How much is controversy suppressed?
Limits of the experiments
Explanations for controversy revealing/suppression
General explanations
Toward a more objective Web
A simulated objective Web
Conclusions
Understanding Web behavior: Politics, technology and users
Recent potential policy changes [ 1] open the possibility for greater concentration of media ownership, possibly leading to fewer and more overlapping sources of information. How does the Web weigh into this picture? Harvard Digital Government researchers [ 2] argue the Internet is not really a counterbalance to traditional media bias because the Web itself is dominated by a few gatekeeper and winner–take–all link–accumulating sites. Is the Web’s apparent openness, diversity, and cost effective information dissemination an illusion?
One empirical study [ 3] investigated link characteristics of highly controversial topics such as gun control and abortion. Crawling three million pages confirmed that a few sites accrued most of the inlinks, suggesting a normal surfer would be "pulled" toward those sites, rather than traveling to smaller and more diverse sites. Because search engines heavily use page links to rank results, searchers often start surfing at these same popular sites. This study also found Web site size and linking often mirrors well established traditional organizations, with only occasional Web–based newcomer groups. While a topic may be presented from many viewpoints and published cheaply, less popular sites are not necessarily easily accessible via search engines — nor by surfing. Retrievability and visibility are quite different, but often confused in technical/political discussions.
Recognizing such bias is not an accusation of unfairness but rather is symptomatic of our growing understanding of complex Web technology operating at a scale of billions of pages and hundreds of millions of users. Although not precisely characterized, search engines collectively cover much less than the whole Web and individual search engines index different parts of the Web [ 4], further exposing alternative orderings by their ranking strategies. Indeed, those biases attract searchers to favor one engine over another.
Search engine bias has been mathematically characterized as deviation from norm or ideal [ 5], e.g. for benchmarking search engines on consumer decision–making queries such as "brand names of refrigerators." Such bias is termed indexical, versus concerns of propaganda and misinformation as content bias. Search engines are thus similar to media organizations, warning "too much consolidation [of either] limits the options for both information producers and information seekers." In practical terms, this study counters the widely held misconception of search engines behaving somewhat like objective and well–informed librarians [6]. Further political concerns [ 7] are voiced about the role of search engines in supporting or thwarting the inclusiveness ideology of the Web. A cause–effect description of search engine indexing practices illustrates certain political consequences. Indeed, the Web might be thought of as an economy of links [8], valued as both monetary and intellectual currency.
The commercial search engine optimization industry [ 9] raises other bias issues tracking ever changing and unclear search engine strategies. Consumer surveys [ 10] about paid placement in search results reinforce a common theme: The general public that is growing increasingly dependent upon search engine technology has relatively low understanding of how the technology works or their responsibilities for its proper use.
Beyond economics and politics, the Web also shares phenomena of complex, dynamic physical systems. Recent studies [ 11] have explored system theories based on Web–wide regularities of structure, growth dynamics, and patterns of authorship and reading. These studies show the Web having an overall "power law" feature, where size of sites, number of incoming, and number of outgoing links all follow a non–modal distribution (i.e., no average behavior). These laws describe a world where a few X have high Y following a rapidly descending curve with most X having low Y (X is a number of sites or pages, Y is a number of links or measure of traffic). A few sites receive a disproportionate amount of traffic and links, while most are effectively islands. Figure 2 and Figure 3 illustrate power curves.
These phenomena are further associated with "winner take all" market forces where the more links a site has, the larger its share as more pages join the Web. However,"winner take all" applies to a lesser extent [ 12] when a topic is more uniformly interesting or a community is more competitive. Usability expertise [ 13] contends no adverse effect on controversial topics from this power law structure because: (a) Topics rarely have overlapping top sites; (b) even if the top sites accrue the bulk of the links, normal searchers will ask more specialized questions that surface smaller sites; and, (c) cheap advertising greatly diversifies the Web by exposing new or smaller sites.
The "search advice" literature [ 14] bases key rules on this knowledge about Web behavior: Use multiple engines (because no engine indexes even half the Web, each has biases), use specialized search engines (much Web content is invisible, hard to index), authenticate and evaluate the quality of Web sites (many sites are only for self–promotion), don’t depend solely on Web searching (fee–based services and traditional library materials may be better catalogued with higher quality). A disturbing analysis of critical thinking deficiencies of college students [ 15] shows specific examples of potentially harmful Web content bias tricking unwary searchers. Furthermore, it’s not reliable to issue retractions or corrections [16] if the modifications are not hyperlinked or reported with the original erroneous articles.
Thus, an understanding of controversial topics on the Web must address three interlocking communities: (1) Web page authors who bestow links on other pages; (2) search engines that partially rely on links for crawling and indexing pages and their ranking of search results; and, (3) searchers (humans) who query for topics and then make browsing selections based on results that serve both engines and authors. Certainly, a search engine could have corporate political biases of its own, e.g. by not crawling designated Web sites or by eliminating pages with particular keywords. However, a search engine basically reflects the biases of Web page authors, and their institutions and objectives. Surfers and searchers reinforce both authors and engines.
Why does visibility of controversy matter?
Highly polarized controversial topics are usually clearly observable in Web contexts. They often bear the identity of well–known organizations and evoke immediate emotional responses in informed readers. Of course, there are proprietary databases for legal research, e.g. Westlaw, that contain exclusively controversial matters and disputes. Another type of controversy exists as a murky subtopic of a broader topic. It may be a different set of facts about a historical episode, or a strongly opposing point of view on a generally accepted practice, or an emerging change in social standards. In Web terms, the controversy may appear as a subweb loosely connected to a topic’s main theme or by pages widely distributed across sites, not inter–linked, but sharing controversy–related keywords. Controversies are easy to miss unless searchers read closely or are actively seeking opposing views.
Why might we care whether controversy is omitted from search results or is missed in an initial topic search?
- Controversies often express the richness and depth of a topic. Consider one of our case studies, Albert Einstein. If all top search results are overly bland or redundant biographies, then a person curious about Einstein’s life and work could well miss richer Web content regarding his personal and political life.
- Controversies dramatize change. Einstein’s public persona and scientific work might seem well settled, but the past two decades have opened up new facets of his career and personal life. For feminists, Einstein’s first wife is a great target of study regarding marriages and scientific collaborations in the early twentieth century. Several Web sites also acclaim her significance as a Serbian woman scientist, reminding us of recent international political changes.
- Controversies may make a critical difference in life–altering decisions. Medical treatments and educational choices require extensive personal research, more than the first superficial search. If controversies are buried in search results or require several links of surfing, then the searcher faces increased risk of missing critical information. Furthermore, an initial search may deter further search by portraying an overly bland and boring picture of the topic (e.g. 27 biographies of Einstein) or a misperception of accepted practice (see Distance Learning and St. John’s Wort case studies).
- Scientists, journalists, and intelligence analysts are professionally required to address multiple perspectives, facts, authorities, and opinions on topics. Search engines may significantly decrease their productivity or conceal incompetence if controversies are overly difficult to investigate.
The dilemma with controversies is that the searcher often doesn’t know what to query for on a broad topic. Asking "(Topic) AND controversy" works some times, but "controversy" has many synonyms. A searcher often doesn’t know the keywords, proper nouns, real life organizations, or link paths to expose a controversial side of the Web. And, there’s a difficult psychological step to "look for trouble" or "peek into the dark side," especially if search results provide an initial positive, or even boring, impression.
Case studies of controversial topics
In order to analyze controversy, we must formulate a more precise question, develop an experimental approach to collect and analyze data, then interpret the results. For example, one study [ 5] presents a mathematical model of bias, collects search engine query data, and offers an interactive Web site for exploring search engine bias.
Our starting assumption is: A controversial subtopic is revealed or suppressed to the degree its URLs are recognizable in the query for the broad topic. This paper uses the hypothesis a given, well–known specific controversy will not be revealed in the top search results. A priori, we would expect that among the 1000s of URLs on a topic, few subtopics will be exposed in top search results. However, using this hypothesis, we might find some surprising refutations where, indeed, controversial subtopics are well represented in top search results. Or we might find absolutely no evidence of controversy in top search results, suggesting systematic bias. Or we might (and did) find a mix for different kinds of topics and subtopics. Each outcome leads us to ask about factors suppressing or revealing the particular controversy, which provides the main contribution of this paper.
The outline of each topic experiment is:
- Select a broad topic and define the simple, perhaps naïve, query a searcher might ask to start learning about the subject matter.
- Collect the top 50 URLs from each of three popular modern search engines and the top 100 from two meta–searchers (send the query to multiple engines and collate the results).
- Identify a controversial subtopic, then define a query using specific keywords for the controversy, and query the same engines in the same amounts.
- Browse the search results to identify pages revealing the controversy, especially those deeply into the controversy itself.
- Select a second, more factual, somewhat related subtopic with specific keywords, but (to reduce experimenter exhaustion) simply assume all URLs are relevant to the topic.
- Compare the results of the subtropics to the simple query and to each other to identify overlapping URLs revealing the underlying controversy.
As we browsed Web pages, we made three levels of judgment:
- Deep: This page digs into the details of the topic. If you (an information seeker) ran across the page within search results or while surfing, you would definitely recognize the existence of controversy, which this page explains in some detail.
- Revealing: This page has links to pages of the controversy or short discussions in passing. However, you might well miss the existence of controversy, in contrast to deep pages definitely revealing the controversy.
- Other: Usually very informative pages, but not mentioning or linking into the controversy.
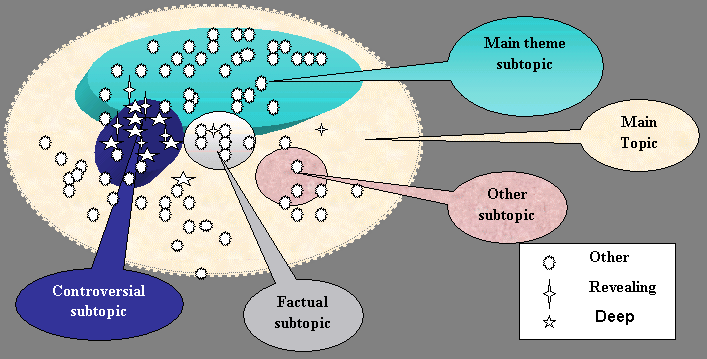
Figure 1 pictorially shows the various subtopics, with images denoting the three categories of Web pages relative to a controversy. The areas we’re particularly interested in are those overlapping the controversy subtopic with the main theme (results of the simple query) and the factual query. Each area represents the results of queries in the combined results from all search engines.
Figure 1: Topics and subtopicsMore details of the experimental methodology are discussed in Appendix A. The reader of this paper should think of these experiments as prolonged browsing sessions aided by a URL calculator, note–taking, and an iterative process. Appendix B provides a brief list of revealing URLs as examples, tables and graphs for the counts and computed percentages of URLs in simple, controversial, and factual queries (merged from all engines). The interested reader is invited to perform a search in their favorite engine for the simple query to get a feeling of the type of results expected (see Appendix A.2). However, search engine results are always changing and query settings may give different results from ours.
Table 1 provides a listing of the broad topics and identifies the selected controversial subtopic. Table 2 shows the factual subtopics and representative other subtopics, along with sample URLs from the 200+ URLs in each query group. Following are brief descriptions of each topic and subtopic for context with brief summaries of results and preliminary explanations.
Table 1: Broad topics and controversial subtopics (queries are vitalized).
Broad Topic Controversial Subtopic Distance Learning "Digital Diploma Mills", the trend toward commercialization of education, as characterized by technology historian David Noble. Albert Einstein Did Einstein’s first wife, Mileva Maric, receive appropriate credit for scientific contributions to Einstein’s early work? Female Astronauts Did the U.S. space program discriminate against the "Mercury 13" women pilots who passed preliminary astronaut screening tests? St. John’s Wort Does this popular herbal remedy work effectively for depression and mood improvement? Recent medical trials differ in their results. Belize This small Central American country has a long, and ongoing, border dispute with Guatemala with deep historical roots in Spanish and British colonialism.
Table 2: Broad topics and other subtopics (Sample URLs).
Broad Topic Controversial Related Factual Other subtropics Distance Learning "Digital Diploma Mills", David Noble (Sample). Formative Evaluation (Sample). accreditation, faculty careers, intellectual property, Web–based training, home schooling, interactive media Albert Einstein Einstein’s first wife, Mileva Maric (Sample). Einstein’s pacifism and political activism ( Sample). religion, humanism, quotations, correspondence, relativity theory, cosmology, philosophy Female Astronauts "Mercury 13" women pilots (Sample). Astronaut selection criteria and procedures ( Sample). space shuttle, space station, Columbia, Challenger, Mir, mission control, astronaut training, astronaut qualification St. John’s Wort Effectiveness (Sample). Dosage recommendations (Sample). side effects, botany, depression, psychotherapy, vitamins, dietary supplements Belize Border dispute with Guatemala (Sample). Narcotics facts (compared with other countries) ( Sample). ecotourism, coral reefs, mayan ruins, British colonies, developing countries, technology
Suppressed Topic: Distance Learning/Digital Diploma Mills
"Distance learning" (DL) refers to modes of instruction which are not same–time/same–place. The topic blends technology with instructional practice with the educational enterprise. The Web reflects these dimensions describing "how Web–based technology works and is used in DL," "how instructional practice benefits from technology," and "what (our) university/company’s DL program offers." In 1997, a technology historian, David Noble, challenged the distance learning movement through a series of widely disseminated articles, inciting numerous debates. Faculty were concerned by loss of control over their intellectual products, as well as contact with students. Active commercialization of DL was causing visible strife at certain universities among faculty, administration, and external interests. Noble coined the term "digital diploma mills" to refer to the new breed of university programs.
Our experiment found only one revealing page in the simple "distance learning" query: An annotated webliography by a library. The top search results are primarily organizational: DL trade associations, universities offering DL programs, as well as several explanatory pages on the nature of DL. Our second subtopic is "formative evaluation," the standard terminology for educational methodology evaluation of technologies, materials, and experiences with them. We wondered if effectiveness and ongoing evaluation influenced David Noble or vice versa. However, the simple, controversy, and factual queries are nearly disjoint.
This topic might be described as suppressing controversy by organizational clout. The David Noble/Digital Diploma Mill subweb is linked around Noble’s writings but perhaps its participating organizations are of less Web status (links, size) than the organizational ones. Readers interested in this particular controversy are also more likely to be inside the academic enterprise, rather than consumers of DL products. The DL "search engine personality" is to "help you find the DL program right for you," rather than "provide pro and con arguments for going the DL route." An information seeker might well assume distance learning is a fully accepted and well–paved alternative cheaper education, when issues of quality, accreditation, and durability of degrees are still unresolved. A few pages address other perceived negative aspects of DL, such as pure degree mills, faculty workload, rich vs. poor, and intellectual property. This controversy seems to have abated since 1999.
Suppressed Topic: Albert Einstein/Mileva Maric
Einstein’s biographies discuss not only his role within normal science but also his life as a political activist during the World War II era. Because Einstein received Nobel recognition in 1921 and then settled at Princeton’s Institute for Advanced Study, his opinions were widely sought and his pithy quotations broadly disseminated. In the past two decades, other facets of Einstein’s personal life have emerged, notably the extent to which his first wife, Mileva Maric, might have contributed rather more than recognized in co–authorship of his technical work. Numerous family related facts appear frequently in biographies, including an illegitimate daughter lost to history, the failure of Maric’s scientific career, their messy divorce (her settlement included his Nobel prize money), and Einstein’s estrangement from his children. Compounding a benchmark of genius, Time’s "Person of the Century" and widely quotable writings, there’s no shortage of pages and Web sites about Albert Einstein.
We focus on the controversy: Did Mileva Maric provide significant scientific support for Einstein’s earlier work? Web authors reference books and articles about "our work," co–authorship listing on submitted papers, indications of Maric’s superior math skills as well as her physics training. However, there is no definitive evidence one way or the other. This controversy was mentioned once in passing in a page from the simple "Albert Einstein" query. Maric is mentioned as student, sometimes colleague, but mostly unhappy wife and mother abandoned for a second wife and family. Our factual topic is Einstein’s pacifism, as expressed in this public writing and speaking. Pacifism, shows a greater number of its revealing URLs in the simple query. Some Maric URLs are revealed in the pacifism query – primarily in pages with more substantive biographies or personality analyses.
One explanation for the absence of controversial content is simple: Albert Einstein is a prime target for term papers, an obligatory biography for science sites, and a fertile source of quotations. These top Web pages are mostly bland, featuring the photogenic Einstein. Such pages essentially squeeze out not only controversy, but any deeper discussions of Einstein’s life and work. The Web material about Einstein is somewhat organizational, with a few museums and affinity groups, plus the Einstein Page and a few other hubs. Many Web pages simply represent organizations named after Einstein. Many pages contain little more Einstein content than a quotation, relevant or not. The Maric Web has the unfortunate characteristic of lacking a central site for the various pages to link to.
Using our criteria that a subtopic appear in the top results for the simple query, the Mileva Maric Einstein controversy is suppressed by sheer volume of quotations, biographies, and passing mentions.
Suppressed Topic: Belize/Guatemala Border Dispute
Belize is a recently independent Central American country known for its barrier reef, jungles, and Mayan ruins. A former British colony, Belize has been caught in a long–standing (since 1821) territorial dispute with Guatemala. Recent international mediation has reduced the level of dispute to "confidence building" negotiations and free trade agreements. The settlement of this dispute remains a major current political issue and a significant one in Belizean history. We chose this controversy because it relates to certain aspects of tourism (visiting the border area) and provides a major contrast with the North American experience. Our factual subject is "narcotics," a recent problem for Belize as its location provides a transfer point from South to North America. Both topics delve into how a small country with few military resources deals with international issues.
The experiment found about seven percent of the simple "Belize" queries controversy–revealing, typically pages like the CIA or an encyclopedia fact sheet. One search engine surfaced a Belizean government Web site on Guatemalan relations and the dispute. Three percent of the Belize narcotics controversy were revealing, mentioned on pages about modern Belizean politics and country facts. Other controversies/disputes include dam placement, logging, elections, and human rights.
Our experiments suggest this topic as another controversy suppressed by organizational clout. A simple "Belize" query returns mostly tourism information and some general country information, with relatively little depth in historical, political, or current events. Major Belizean newspapers are online but much of the political and cultural material comes from either U.S. or British sources. As a one–time tourist (mainly for the reefs and ruins, in the 1990 pre–Web era), this author is now disappointed not to have had this cultural and historical background. Trading off a few tourism pages for more history would have presented a better rounded portrayal of "Belize" as a starting query.
Revealed Topic: Female Astronauts/Mercury 13
Female astronauts serve as significant role models for young women through their career participation in science and engineering, feats in space, and competition in a still male–dominated field. Most young people go through a "how do I become an astronaut?" phase. Especially when the next step for manned space exploration is such a long one, promoters such as Dr. Sally Ride and Dr. Mae Jemison play important roles in maintaining interest in space. This is a popular Web topic.
But there are other persistent voices from the beginning of the space era. A little known story about the early days of astronaut selection has received increasing attention through various space and women’s organizations and recent books. When the Mercury space program started around 1960, concerns grew about human performance and payload size, including astronaut weight and food and oxygen consumables. A group of highly experienced women aviators were considered as astronaut candidates. They passed extensive physical and psychological testing, involving secrecy and disruption of their careers and personal lives. Their testing success brought the issue to U.S. Senate hearings involving Mercury 7 astronauts and NASA officials as well as the group leaders, pilots Jerrie Cobb and Janey Hart. NASA and Vice President Johnson put an end to the testing for various reasons, including a perceived need for test pilot experience and public relations fear at loss of a female crew member. The Russian space program first launched a woman into space in 1963. The shuttle need for mission scientists led to the launch of Dr. Sally Ride in 1983. Senator Glenn’s second (geriatric) flight also brought public attention to the earlier "Mercury 13," some still seeking a space flight.
This controversy is definitely visible in the results for the simple query "female astronauts," with about 16 percent of the top results being revealing, including nine percent deeply describing the Mercury 13 episode and its protagonists. Mercury 13 headlines appear across CNN and other news sites, at aviation and space Web sites, and in women–oriented venues, notably the National Organization for Women and the ninety–nines (women pilots). This has been an easy cause for such groups to promote and continue in memory of four lost female astronauts in two space shuttle accidents, and recognition from Commander Eileen Collins. Numerous biographies and speaking engagements by women astronauts, NASA promotion of its internal women corps, and "first women" histories account for the dominant theme of the search results. Another factor revealing the controversy is timeliness coinciding with 40 and 20 year commemorations of Russian and American flights. However, the odds of finding Mercury 13 information are significantly less, four percent, with the factual query "astronaut selection," which largely rehashes the modern day criteria enumerated on NASA’s Web site.
We judge the Mercury 13 topic as a controversy significantly contributing to and not suppressed within the broad topic of "female astronauts."
Revealed Topic: St. John’s Wort/Effectiveness
St. John’s Wort (SJW) is a long–used herbal remedy for depression, stress, anxiety, and related maladies. In the U.S., as an off–the–shelf drug, its effectiveness, side effects, and proper dosages are not regulated nor subjected to much clinical study. With increasing market competition and medical concern, the U.S. National Institutes of Health, following British and German studies, began clinical trials around 2000. These trials raised questions: Is St. John’s Wort effective for what its sellers claim? Why does it work? What are the proper dosages? How does its effectiveness compare with other prescription drugs? What are the known side effects and drug interactions?
We chose the controversy about ongoing clinical trials under NIMH (National Institute of Mental Health), with participating drug companies (Glaxo, Pfizer, and Lichter Pharma). A page was judged to deeply reveal the controversy if it prominently addressed these clinical trials. This criterion omitted many pages of other clinical trials related to side effects (often HIV–related), general descriptions of the herb plant, and pricing and product information. Our second factual subtopic is "St. John’s Wort dosage" related, of course, to effectiveness (How much is needed? How much is too much?) and other issues of measuring the amount of key ingredients.
Nearly 30 percent of the simple "St. John’s Wort" query results raised the controversy to some significant degree. For the factual topic "SJW Dosage" about 16 percent rates as controversy–raising. However, the number of unique pages is much lower thanks to duplicates or syndicated articles: An NIH NCCAM (Alternative Medicine) fact sheet, a Nutrition Action newsletter study description, and an NIH warning of SJW ineffectiveness for major (opposed to minor) depression.
The top search results give significant prominence to this controversy. An astute reader who bypasses the pure product pages will have a good chance of running onto a page reporting on clinical trials, for example, a newsletter’s succinct description with links to the on–going studies. However, a superficial reading of the product pages and many of the older (pre–2000) description pages could well lead to a false sense of acceptance of SJW as harmless, a solid alternative to therapy and medicine, and a relatively cheap and standardized product.
Summary of case studies: How much is controversy suppressed?
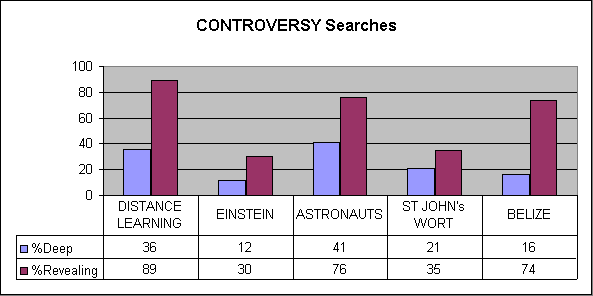
Each controversy was well represented on the Web in search results posed with the right query. However, we do not believe many searchers would be exposed to the controversies by search or surfing alone, without off–Web experience. We knew of Mercury 13 through a recently released book, of David Noble by regular reading of sources publishing his work, of Mileva Maric by vague recollection of a book review or PBS program. We discovered the controversies for St. John’s Wort and Belize as added experimental topics.
Female Astronauts/Mercury 13 and St. John’s Wort/Effectiveness showed the most prominence of their controversies. Mercury 13 is a new and interesting aspect of a somewhat stale topic, stimulated by current and anniversaries of space events and recently published books. St. John’s Wort is addressed by commonly disseminated information regarding alternative medicines, with the force of U. S. government advisories. The Einstein/Maric controversy was swept away by biographies from standard science resource sites. The Belize–Guatemala border dispute was buried a level down in Belizean history, which is dominated by the country’s tourism industry. The Digital Diploma Mill controversy was dominated by the organizational clout of distance learning organizations and by its fading presence in the past five years.
Our experimental results are, not surprisingly, inconclusive. If all five topics had strong representation of controversies then we might consider search engines performing much like well–informed, unbiased professional subject experts. If all five had completely suppressed controversy, we might suspect a conspiracy to present only the pleasing or commercial sides of search subjects. Some ambiguity in the results arises from the nature and limits of the experiments themselves, but several factors of Web behavior warrant further study.
Limits of the experiments
Appendix A.2 summarizes some limits of our experiments: Messiness handling duplicates, dead URLs, and dud pages; subjectivity judging pages deep or revealing; incompleteness in the evaluations; unpredictability of query syntax and semantics; time sensitivity; and, bias of engine choices. We believe any single experimental limitation made a difference of only a few URLs, but not a significant change in results. The most serious difficulty with the experimental methodology is assuming controversy suppression/revelation correlated with a single, specific, well–known subject query and a simple query for the broader topic. Further examination of additional queries or a vaguer notion of "controversy, altercation, disagreement, dispute" are called for, but the current limited experiments still tell us much about how controversy is handled by search engines. Replication of these experiments should include additional bodies of material, such as (1) subscription and value–added databases and traditional library materials; and, (2) the rapidly growing and heavily inter–linked Weblogs.
An interesting question is whether there is a clearly superior search engine among the ones used in the experiment. Is Google the clear winner? Table 3 shows a surprising consistency among search engines in their ability to reveal controversy Web pages. Google had a slight edge and AllTheWeb a slight lag, but for our purposes the engines are roughly equal in results. Also consistent is the overlap among engines, about 33 percent.
Explanations for controversy revealing/suppression
Suppose you asked a knowledgeable, objective consultant or advisor about a topic. They’d likely tell you something like
"here are the top information sources on the topic (A, B, C). You should consider these issues (X, Y, Z), specifically controversies raised by A and B as well as C’s analysis. Research literature (D, E) systematically evaluates the technology. Note I have a conflict of interest with B on topic X, and I’m somewhat more persuaded by A’s criticism on issue Z."Of course, nobody expects such a level of professionalism and expertise from a bundle of algorithms and databases and servers operating under a still developing business model. However, we might look for significant characteristics of bias: Gaps, preferences, undeclared conflicts, blurry categories of expertise, or difficult to handle material. The following table summarizes some of the factors associated with bias as observed in our five experiments:
Table 3: Factors for Suppressing or Revealing Controversy.
Distance Learning/Diploma Mills Albert Einstein/Mileva Maric Female Astronauts/Mercury 13 St. John’s Wort/Effectiveness Belize/Guatemala Border Suppressing Factors Organizational Clout sellers, services, trade associations prolific reference and science sites NASA and big space sites store sites tourism industry Poorly organized academic talk no Maric Web site Duplication, junk trivial biographies, quotes lists of women firsts, space history chains of stores lots of hotels Analytic Web secondary newsgroups, e–zines low readership few in–depth biographies only dissertations and long histories Revealing Factors Promotion debates, articles online letters, biographies books, 99s, NOW NIH, syndication Government agencies Social relevance college costs, professors’ worry Serb history, feminism role models, activism safety, HIV colonialism, mediation Timeliness Web commercialism debates Time person of century, ads, books Columbia, 20/40 year anniversaries, Glenn flight clinical trials in progress referendum on settlement Media interest "diploma mill" exposès first wives club, love letters character profiles, pilot feats nutrition, medicine news daily stories
General explanations
The Organizational Web dominates the Analytic Web.
Two broad communities of interest on the Web might be grouped as "organizational" and "analytic." Organizational communities are actual or virtual: Companies, universities, trade associations, consortia, alliances, and government agencies. Distance learning purveyors, science reference sites, NASA, medical advisors, and tourist associations have off–Web organizations, resources, and motivation to be big Web players. The "analytic" Web consists of online full–text (or tables of contents) journals, technical reports and preprints, opinion pages, bibliographies, and pages of links to these. Analytic literature is widely available on the Web, but is not as extensively interlinked nor represented by large dominant Web sites. The Organizational Web tends to link to key Web sites to an extent search engine ranking strategies naturally assume these organizations are what searchers are looking for first and foremost. And they’re usually right.
Controversial subtopics are widely distributed, poorly defined, and weakly organized.
Mercury 13 illustrates a cohesive controversy, with book Web pages, online stories by protagonists, and broad reach into news Web sites. In contrast, Mileva Maric shows how a few pages without a core Web site or organizing group does not change the primary perspective of its topic. The Distance Learning controversy is represented by many long articles distributed in some limited–interest publications without continuing interaction with DL purveyors.
Revisionism takes time.
The Einstein subtopic shares with Mercury 13 not only feminist interest, but also the issue of revisionist history on the Web. Social change interests some communities, but repels or is ignored by others. New views on a topic must coexist with older views (and the links to them). Do search engines take topic currency into consideration when ranking results? How could they? Page modification date, content creation date, and whether content is current are all different. With few pages yet a decade old, is it possible Web content is becoming increasingly outdated? Suppose an irrefutable and important fact were discovered about Albert Einstein? Would most of the hundreds of Web biographies be updated? Probably not, although a few sites would feel the obligation. And, many of the important articles, such as Time’s Person of the Century, should remain unchanged in archives. Likewise with St. John’s Wort, clinical trials in progress will publish results in 2005 to share Web space with pre–trials articles written around 1997. The Albert Einstein topic pointed out the crucial role for new content venues, such as Wikipedia, which reflect more recent information as well as modern interests, and may be more frequently updated than traditional references.
It’s not technology, but social factors, suppressing controversy.
Search engine strategies seek to provide credible, relevant answers to general questions, such as the ones we’ve posed for our experiments. Ranking highly the most linked to or heavily keyworded or largest sites on a topic makes sense. But beyond the "round up the usual suspects" strategy, what other search results are relevant? Searcher and surfer habits seem to be rewarding "more of the same" organization sites rather than less popular content from the Analytic Web. On the other hand, are search engine results mostly a reflection of what Web authors write about and how they link to each other? What about those pages clearly revealing of controversy? Which might serve as "role models" for analytically oriented authors who seek to get their pages into the top rankings? Our experimental results suggest social factors, timeliness, and media interest strongly influence the prominence of controversies.
Toward a more objective Web
Knowing that pages with controversial content may be found sometimes, but not consistently, suggests alternative strategies toward more prominence of controversial and analytic pages.
Web authors might adopt more rigorous linking practices to (a) reach a higher standard of objectivity and/or (b) exert greater influence on search engine ranking. Academic researchers learn early in their careers to pass stringent peer reviewing by addressing not only the data favoring their approach but also opposing views, contradictions, and unknowns. If this practice was adopted by Web content creators, how would Web linking change? Search engine optimization experts now practice link exchange in recognition that links have economic value. We simulate a more objective scenario later in this paper.
Many factors work against this change in linking practice. Most organizations invest heavily to promote themselves and certainly won’t link to competitors. This is characteristic of the Organizational Web, but now consider the Analytic Web. Many safe sites (e.g. Yahoo or Google directories) are common hubs for links, leaving the information seeker to sort out the link’s actual target. Well–stablished authorities, often traditional real–life organizations, are other safe and useful targets. It takes some courage to link to a lesser known or "lone genius" site. Linking to a less stable site with dead links or unpredictably changing pages is risky, even if its content is well–written and provocative. As in writing a thorough research paper, considerable extra thought must go into creating accurate and balanced references (links). We’re still looking for the opposing links for this paper’s novel topic. However, linking only to popular, but possibly bland or less relevant, sites reinforces their status in search rankings over more specialized sites.
Search engines might alter their ranking strategies to provide more openness to the "Analytic Web" (controversy + data + evaluation + detail). Search engine ranking strategies remain proprietary, often mysterious, in flux, and a challenge to searchers. It would be unreasonable, and probably undesirable, to urge search engine companies to adopt a more objective standard, e.g. 25 percent of rankings include controversies, 25 percent traditional organization Web sites, and 50 percent objective pages, even if technically feasible. However, ranking might include more predictable and recognizable distribution of the organizational (institutions vs. individuals) or analytic (glossy vs. technical) subwebs, e.g. Teoma’s "Link Collections from Experts and Enthusiasts."
Search trainers and professional searchers might alter their search practices. This paper shows how five different topics only weakly present controversies at the naïve query level. Advice to query specifically for controversy belongs with advice to be wary of deceptive Web pages. Librarians have long advised the Web is often not the best source of analytic information. Search pros recognize Web content must be authenticated and checked from different sources before accepted. Mistrusting search engine results falls into this category. of advice, as do countermeasures for balancing organizational and analytic Web content.
Engines, authors, and searchers might advance toward alternative paradigms for working the Web. Today’s metaphor is "search." Another metaphor is "Collect" [ 17], emphasizing broader search, filtering, and ranking to produce well–rounded, multiple–use collections of URLs rather than a single–answer URL. Another paradigm is explicit markup on concepts driven by ontologies (concept specifications) in the Semantic Web [18].
A simulated objective Web
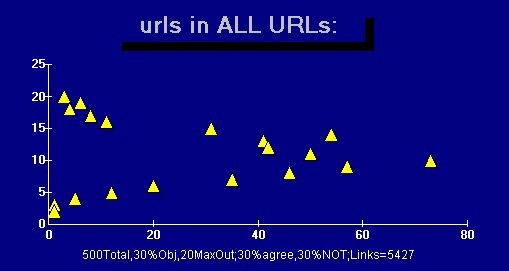
Here’s how the current Web appears. Figure 2 shows the number of inlinks for sites of the "distance learning" data graphed against the number of sites with this number of inlinks.Note the area near the Y axis with few sites having large numbers of inlinks, leading to a long tail of the curve with most sites having 0 or 1 inlinks. Figure 3 shows a similar curve for pages of "Albert Einstein." These curves apply for links among pages in the respective collections not the data about the Web as a whole, but sharing the same distributions as fractals [11].
Figure 2: Power curve of Inlinks to Sites of "Distance Learning"
Figure 3: Power curve of Inlinks to URLs for "Albert Einstein"Let’s idealize a situation where many pages are objective; examples are starred in Appendix A.2. A purely objective page might hold a carefully selected list of links or provide multiple sides of a topic. Of course, most pages would be pro or con some issue, usually favoring their organization’s position. Now, suppose we "require" all Web authors identify and link to opposing and contrasting views, as well as relevant objective pages. Examples of this linking strategy include: Distance Learning pages linking to pages refuting its effectiveness, experimental results, as well as the negative business side of degrees; Einstein biographies linking to Maric biographies and providing more depth on the controversy; Female Astronaut lists also showing the Mercury 13 pilots (many do), plus pages analyzing NASA’s acceptance of women; alternative medicine stores linking to NIH advisories, and revisions to knowledge as clinical trials advance; and, Belize histories linking more to the Guatemala dispute coverage from both sides of the border.
Below is the resulting graph when 10 percent of 500 URLs are objective and Web pages distribute their links 50 percent to supporting, 25 percent to opposing views, and 25 percent to objective pages. Numbers of links and links among pages are randomly generated, constraining pages to either both agree or both disagree. This new graph, Figure 4, shows a redistributed power curve with many links to the objective pages (near the Y axis) and a more even distribution of the number of inlinks with more pages getting inlinks. Figure 5 shows more evenness in distribution of inlinks with a higher percentage of objective pages. Of course, this simulated Objective Web differs from Figures 1 and 2 not only in link distribution policy but also in number of links.
Figure 4: Simulation of an inlinks in an Objective Web with 500 pages, 10 percent objective, and 50:25:25 Agreeing:Opposing:Objective Distribution
Figure 5: Simulation of an Objective Web with 500 pages, 30 percent objective, and 30:30:40 Agreeing:Opposing:Objective DistributionThe results are not surprising but visually emphatic, contrasting today’s Web with a hypothetical Web having a different standard of linking behavior. This model confirms that a more objective policy would exhibit an extreme change in some Web characteristics. Further effects would then appear in search engines ranking highly by inlinks, shifting preference to objective pages. The requirement to link more extensively and non–exclusively to agreeing or popular pages would distribute links more evenly across all pages.
Conclusions
The experimental methodology introduced in this paper, while needing refining, raises important questions about Web search engine bias. A given topic is analyzed by a combination of specified searches (simple, controversy, factual), rating pages for possible or deep revelation of controversy, then interpreting the suppressing or revealing factors. The dilemma of controversies is that the searcher beginning to explore a topic doesn’t know the search terms to investigate a controversy unless it is revealed with reasonable visibility, e.g. not item number 879 in search results, nor buried three links away from result number 30. The unpredictability of search engine indexing and ranking algorithms exacerbates the difficulty of performing good experiments. Nevertheless, these experiments provide many insights into the nature of searching and authoring for the Web:
- Five specific controversies are well–represented on the Web, knowing the appropriate search terms, with background knowledge required. Controversies exist to be revealed.
- The controversies contribute significantly to the richness and depth of their topic. A searcher who went no further than the top 50 simple topic search results of any engine could easily miss interesting and important content (deficiencies of distance learning, social status of women scientists, continuing effects of colonialism). Where the controversy reached the top search results, the topic gained data (clinical trials, aviator personalities) and exposed historical trends (alternative medicine, professional contributions of women in space).
- Search technology tends to present the "sunny side" of a topic. This bias reflects authors’ links and searchers’ choices. A few organizations often exert strong commercial (or nonprofit) influence through Web site investments and accrue high link counts through their off–Web prominence. On the simplest query for a topic, a searcher expects to see the most influential organizations appear, not a bundle of dirty laundry or diatribes attacking the topic’s leaders or ideas, i.e. the "dark side." Searchers use a particular engine because its biases give them the results they usually want.
- As long as search engines are heavily guided by links, Web authors who bestow or withhold links to related pages influence the status of their subtopic in search results. If the Web’s analytic content (holding a deep controversy page) separated from its organizational content (sellers, trade associations, activism), pages could be presented more clearly in context and evenly distributed. If Web authors linked more objectively and extensively, e.g. following the traditional research citation model, then authoritative pages would likely accrue more links, rise higher in search engines, and carry along the most significantly contributing pages on all sides of a controversy — facts, opinions, analyses, and activists. An example is the librarian–created links to Distance Learning (highlighted in Appendix A.2).
- The most practical change is for searchers to be more aware of indexical bias and "sunny only" predisposition of search engines and page authors, to actively seek the "darker side" when appropriate, by using more search engines, more diverse queries, a greater number of search results, and searching where controversy and more analytic material is likely to be found.
Web search engines do not conspire to suppress controversy, but their strategies do lead to organizationally dominated search results depriving searchers of a richer experience and, sometimes, of essential decision–making information. These experiments suggest that bias exists, in one form or another, on the Web and should, in turn, force thinking about content on the Web in a more controversial light.
About the Author
Susan Gerhart teaches software engineering, databases, and discrete mathematics at Embry-Riddle Aeronautical University (Prescott, Ariz.) ( http://pr.erau.edu/~gerharts). She was recently active in developing and evaluating interactive computer security modules for undergraduate curricula ( http://nsfsecurity.pr.erau.edu). Dr. Gerhart is also the developer of the twURL Web analyzer ( http://www.twurl.com) and has created a portfolio of topics at "the twURLed World" ( http://www.twurled-world.com).
E-mail: gerharts@erau.edu.
Acknowledgements
Thanks to one of First Monday’s anonymous reviewers for distinguishing Web from general search characteristics, to Ms. Linda Seyler’s Northern Arizona University class on "questioning techniques" for lucid and helpful critiques, to Dr. Paul Hriljac for suggestions on the paper’s simulations, Embry–Riddle Prescott faculty and librarians for feedback, and Dr. Jan Hogle for a framework for evaluating research results.
Notes
1. See, for example, the Federal Communications Commission’s (FCC) "Media Ownership Policy Reexamination," at http://www.fcc.gov/ownership/Welcome.html, accessed 1 September 2003.
2. Matthew Hindman and Kenneth Neil Cukier, "More News, Less Diversity," New York Times, (2 June 2003), also at http://www.princeton.edu/~mhindman/NYTimesOpEd2.htm, accessed 1 September 2003.
3. Matthew Hindman, Kostas Tsioutsiouliklis, and Judy A. Johnson, "‘Googlearchy’: How a Few Heavily Linked Sites Dominate Politics on the Web," paper presented 4 April 2003 at the annual meeting of the Midwest Political Science Association (Chicago), at http://www.princeton.edu/~mhindman/googlearchy--hindman.pdf, accessed 1 September 2003.
4. Lee Giles and Steve Lawrence, 1999. "Accessibility and Distribution of Information on the Web," Nature, volume 400, number 6740, pp. 107–109.
5. Abbe Mowshowitz and Akira Kawaguchi, 2002. "Bias on the Web," Communications of the ACM, volume 45, number 9 (September), pp. 56–60. Also CCNY Intelligent Searcher at http://wikiwiki.engr.ccny.cuny.edu/IntelSearch/.
6. Chris Sherman, "Are Search Engines Biased?," at http://www.searchenginewatch.com/searchday/article.php/2159431, accessed 1 September 2003.
7. Lucas Introna and Helen Nissenbaum, 2000. "Defining the Web: The Politics of Search Engines," IEEE Computer, volume 33, number (January), 54–62.
8. Jill Walker, 2002. "Links and Power: The Political Economy of Linking on the Web," In: Kenneth M. Anderson, Stuart Moulthrop, and James Blustein (editors). Hypertext 2002: Proceedings of the Thirteenth ACM Conference on Hypertext and Hypermedia, June 11th–15th, 2002, University of Maryland, College Park, Maryland. New York: ACM Press, pp. 78–79, and at http://cmc.uib.no/jill/txt/linksandpower.html.
9. WebMasterWorld forums at http://www.webmasterworld.com/.
10. See ConsumerWebWatch at http://www.consumerwebwatch.org/.
11. Bernardo Huberman, 2001. The Laws of the Web: Patterns in the Ecology of Information. Cambridge, Mass.: MIT Press; Albert–Làszlò Barabàsi, 2002. Linked: The New Science of Networks. Cambridge, Mass.: Perseus Publishing; Book Web site at http://www.nd.edu/~networks/linked/.
12. David Pennock, Gary Flake, Steve Lawrence, Eric Glover, and C. Lee Giles, 2002. "Winners don’t take all: Characterizing the competition for links on the Web," Proceedings of the National Academy of Sciences, volume 99, number 8 (April), pp. 5207–5211; abstract at http://www.modelingtheweb.com/.
13. Jakob Nielsen, 2003. "Alert Box: Diversity is Power for Specialized Sites," (16 June), at http://www.useit.com/alertbox/20030616.html, accessed 1 September 2003.
14. Chris Sherman and Gary Price, 2001. The Invisible Web: Finding Hidden Internet Resources Search Engines Can’t See. Medford, N.J.: CyberAge Books, Table of Contents at http://www.invisible-web.net/iw_contents.pdf; Ballard Spahr Andrews & Ingersoll, LLP, "Evaluating The Quality Of Information On The Internet," at http://www.virtualchase.com/quality.
15. Leah Graham and P. Takis Metaxas, 2003. "Of course it’s true; I saw it on the Internet," Communications of the ACM, volume 46, number 5 (May), pp. 70–75, also http://www.wellesley.edu/CS/pmetaxas/CriticalThinking.pdf, accessed 13 September 2003.
16. Stephen Adams, 2003. "Information Quality, Liability, and Corrections," Online, volume 27, number 5 (September/October), pp. 16–22, and at http://www.infotoday.com/online/sep03/adams.shtml, accessed 13 September 2003.
17. Susan Gerhart, 2002. "Topics and Collections: An Alternative Metaphor for Using the Web," FreePint, number 56 (February), athttp://www.freepint.co.uk/issues/170200.htm#feature, accessed 7 November 2003.
18. Tim Berners–Lee, James Hendler, and Ora Lassila, 2001. "The Semantic Web," http://www.w3.org/2001/sw/, accessed 7 November 2003.
Appendix A: Experimental methodology details
This appendix describes the details of search engine queries (engines used, specific search terms), an analysis of the limits of the experimental methodology, and a summary of the twURL URL analyzer used in the experiments.
Appendix A.1: Search engine details
Search engines used
and two multi–searchers
- Web–based Profusion (Altavista, About, AOL, Lycos, Raging Search, Wisenut, Metacrawler, MSN, Adobe PDF, Looksmart, Netscape, Teoma, AllTheWeb)
- desktop Copernic (Ah–ha, Altavista, AOL, Euroseek, AlltheWeb, Findwhat, Hotbot, Infospace, Looksmart, Lycos, Mamma, MSN, Netscape, OpenDirectory, Teoma, Wisenut, Yahoo).
Queries used
Simple: distance learning, Albert Einstein, female astronauts, St. John’s Wort, Belize
Controversy: distance learning and David Noble, distance learning and digital diploma mills; Mileva Maric, Albert Einstein and Mileva; Mercury 13, Jerrie Cobb; St. John’s Wort and (Glaxo, Lichter Pharma, Pfizer, NCCAM, ASP-ASIM, Nutrition Alert); Belize and Guatemala dispute
Factual: distance learning and formative evaluation; Albert Einstein and pacifism; astronaut selection; St. John’s Wort and dosage; Belize and narcoticsQueries posed as Advanced Search, using phrase (vs. all words) where possible. One hundred URLs drawn from the results, then reduced to the top 50. For multi–searchers, top 30 drawn from each engine for Copernic, all for Profusion, as far as the multi–searchers would go, then the top 100 used.
Appendix A.2: Limits of the experiments
- Results are based on the naïve, simple query and a single controversial topic. No established experimental methodology for testing bias in search engines yet exists [ 5]. Our approach — comparing a simple query with a controversial one — provides a baseline experimental hypothesis: A specific controversy, though well–known, would not be significantly represented in top search results. This hypothesis proved false for two topics and true for three. The experiments also generated questions and explanations for some behavior of search engines, Web authors, and information seekers.
- The experiments were complicated by messy duplicates, dead links, ads, paid placement, and irrelevant pages. The same Web content often appears under many different variations of URLs or mirrored pages. We considered the pages different until the end analysis where duplicates effectively merged into single URLs. Dead links, paid placement, and browsed pages with no apparent relevance were eliminated. Analysis focused on identifying Deep Web pages first, and those Revealing next, with a goal of missing a few Revealing, but no Deep.
- Identifying Deep and Revealing URLs required subjectivity. We viewed most of the nearly 3,500 URLs in Internet Explorer, using a stream of URLs fed by twURL. Growing familiarity with a topic clarified URLs deep into the controversy (you "couldn’t miss the controversy in the title and page scan"). The Revealing category took more work to find pages with links to or passing references in larger articles. An independent review would likely show some differences of opinion on specific URLs.
- The browsing process was incomplete. We used a controlled vocabulary for each topic to identify possibly Deep or Revealing pages. Our keywords applied only to snippets from pages, thus sometimes missing relevant pages. Although these pages were already filtered by the indexing algorithms of search engines, we sometimes found relevant pages which search engines had missed or ranked too low to appear in our results. We also followed links to or from URLs found to be Deep, prioritizing browsing to the deeper controversy, then the revealing, and finally the remaining pages.
- The search results are biased by the specific queries used. Are the broad topics using the correct keywords, e.g. "women astronauts" instead of "female astronauts" or "distance education" instead of "distance learning"? Variant queries do give different results, and might lead to somewhat different conclusions. For example, there may be a greater correlation in the terminology of Web contributors between "David Noble" and "distance education" (versus "distance learning"). Since some search engines are also sensitive to plurals, we queried where we thought necessary for both singular and plural of "female astronaut" and "digital diploma mill". Furthermore, advanced searches sometimes twist combinations of "must include" into obscure Boolean expressions. The unpredictability of ranking algorithms together with the imprecise definition of "advanced search" results is an underlying dilemma: How would one validate a query to assure it’s posed correctly and the search engine delivered its promised results?
- The experiments are time–sensitive. Any query results will vary from one instance to the next and probably more over longer periods of time. Books on "Mercury 13" possibly accelerated the "female astronauts" controversy; these books were published in mid–2003 and this experiment was performed in August 2003, although related articles from other sources go back several years. Forty– and twenty–year panniers of "first female astronauts" also may have influenced the results. Other topic search results will likely show declining or increasing amount of controversy as Web authors write more or less and information seekers interest grows or declines. Search engines will index new pages and eliminate other pages from their indexes. Search engine ranking algorithms will change and the relative rankings of sites will also vary.The same experiments repeated six months from now will likely show some differences.
- The experiments are sensitive to search engine choices. Indeed, more engines could have been chosen, but our experience indicated three major engines plus two multi–searchers (covering other engines) would suffice. Indeed, it is surprising how much the chosen engines are in agreement and how consistent their overlap with other engines.
In summary, we have an outline of an experimental methodology no more valid nor reliable than its underlying technologies. A valid experiment is not biased away from producing the data needed. These experiments addressed bias by targeting recognizably deeper, then revealing, then other Web pages. A reliable experiment would produce the same results for all samples taken and with different experimenters. This should be addressed simply by replicated and more exhaustive experiments. Thus, the results of these experiments should not be overly interpreted until the experimental methodology is refined and variations performed to address the above problems.
Appendix A.3: Summary of twURL
twURL is a Windows desktop tool for analyzing URL collections. URLs are extracted from saved search engine pages (Google, Teoma, AlltheWeb, Profusion) or exported files (Copernic) and merged into a URL base. Views of the URLs then include: Internet domains, number of links, number of sources, ranking by query and engine, keywords from a topic–specific controlled vocabulary. Once organized into Views, URLs are browsed in order within sub views, e.g. all URLs with keyword "Milevav or URLs with most links in. Browsing consists of automatically loading the Web page into Microsoft Internet Explorer in the order given in the current View. As URLs are browsed decisions may be made and recorded to identify Deep, Relevant, and Other pages. The data was imported into Microsoft Excel for further analysis, e.g. decisions per engine, overlaps among engines, decisions per query, etc. HTML reports of the entire collection and the controversy pages are available at http://www.twurl.com/Controversy/Data/.
Appendix B: Results of experiments
This appendix provides the numerical counts and percentages of deep and revealing URLs for each topic, a graphical comparison of these results, samples of URLs showing characteristics of controversial and factual pages, and a comparison of search engine overlaps and effectiveness.
Appendix B.1: Query results
This table shows the results of queries from all engines. Revealing Web pages suggest the existence of controversy, among other topics. Deep Web pages provide details in full force regarding the controversy. A searcher might well miss a Revealing URL description but would definitely be presented the controversy in a Deep Web page.
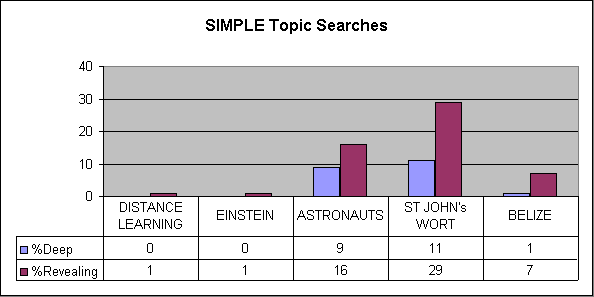
number of URLs Revealing Deep Percentage Deep Percentage Deep or Revealing Distance Learning (totals) 661 152 100 15 38 controversy david noble 281 147 100 36 89 factual formative evaluation 179 1 0 0 <1 simple distance learning 212 1 0 0 <1 Albert Einstein (totals) 759 110 4 8 20 controversy mileva maric 504 91 58 12 30 factual albert einstein pacifist 180 8 2 1 0.6 simple albert einstein 171 1 0 0 <1 Belize (totals) 443 89 22 5 25 controversy belize guatemala dispute 144 84 23 16 74 factual belize narcotics 167 5 0 0 3 simple belize 169 10 1 1 6 Female Astronauts (totals) 663 85 90 14 26 controversy mercury 13, Jerrie Cobb 210 66 88 41 76 factual astronaut selection 167 5 3 1 4 simple female astronauts 349 25 32 9 16 St. John’s Wort (totals) 948 106 145 15 27 controversy St. John’s Wort effectiveness 648 87 135 21 35 factual St. John’s Wort dosage 221 16 19 9 16 simple St. John’s Wort 267 48 29 11 29
Appendix B.2: Comparison of Revealing and Deep (Controversy. Broad Topic)
Appendix B.3: Samples of most Revealing sites/URLs
*** indicates a model objective page
Distance Learning
Controversy "David Noble", "digital diploma mills"
- "Digital Diploma Mills: The Automation of Higher Education" http://www.firstmonday.dk/issues/issue3_1/noble; "Digital Diploma Mills: A Dissenting Voice" http://www.firstmonday.dk/issues/issue4_7/white; "Brave New Universities" by Michael Margolis http://www.firstmonday.dk/issues/issue3_5/margolis
- Distance Education http://communication.ucsd.edu/dl; Untitled http://www.rohan.sdsu.edu/faculty/feenberg/TELE3.HTM (deep URL below ranking cut–off)
- Digital Diplomas http://www.motherjones.com/mother_jones/JF01/diplomas.html
- Review: Digital Diploma Mills http://mtprof.msun.edu/Win2003/lockrev.html
- The Dark Side of ALN http://eies.njit.edu/~turoff/Papers/darkaln.html (pre–dates David Noble, similar theme)
- ***Library Support for Distance Learning http://www.lis.uiuc.edu/~b-sloan/libdist.htm (Also in factual and simple queries)
Factual "formative evaluation"
- Archived — The Integrated Studies of Educational Technology — ED Office of Educational Technology http://www.ed.gov/Technology/iset.html
- theNode.org: Ellen Herbeson — a formative evaluation of distance education: experiences of learners http://node.on.ca/tfl/notes/herbeson.html
Albert Einstein
Controversy "Mileva Maric"
- ***Mileva Maric — Wikipedia http://www.wikipedia.org/wiki/Mileva_Maric
- Student Searches for Albert Einstein’s Wife and Daughter http://www.mtholyoke.edu/offices/comm/csj/961122/ein.html
- Albert Einstein/Mileva Maric — Love Letters http://www.semcoop.com/detail/0691088861
- Mileva Maric http://www.teslasociety.com/Mileva.htm
- Mileva Maric Einstein — ‘Out From The Shadows Of Great Men’ http://www.compuserb.com/mileva02.htm
Factual "Pacifism"
- Albert Einstein — http://www.crystalinks.com/einstein.html
- Albert Einstein — Wikipedia http://www.wikipedia.org/wiki/Albert_Einstein
Female Astronauts
Controversy "Mercury 13"
- Ninety–Nines — The Mercury 13 Story http://www.ninety-nines.org/mercury.html
- Mercury 13 — the Women of the Mercury Era http://www.mercury13.com/noframes/jerrie.htm
- NOW Launches Campaign to Send Pilot Jerrie Cobb Into Space, http://www.now.org/nnt/winter-99/jerriecobb.html
- CNN — First female astronaut still hoping to go up — October 28, 1998 http://www.cnn.com/TECH/space/9810/28/first.woman.astronaut
- Military Women Astronauts http://userpages.aug.com/captbarb/astronauts.html
Factual "Astronaut Selection"
- Women in Space — Female Astronauts and Cosmonauts http://womenshistory.about.com/cs/aviationspace
St. John’s Wort
Controversy "effectiveness"
- St. John’s Wort (Hypericum perforatum) and the Treatment of Depression http://nccam.nih.gov/health/stjohnswort
- Nutrition Action Health letter — St. John’s Wort Links Page http://www.cspinet.org/nah/sjw.html
- ***NIH News Release — Study Shows St. John’s Wort Ineffective for Major Depression of Moderate Severity http://www.nih.gov/news/pr/apr2002/nccam-09.htm
- ***ACP–ASIM Pressroom http://www.acponline.org/college/pressroom/antidep.htm
Factual "Dosage"
- herb data, St. John’s Wort, Hypericum Perforatum, Johnswort, Amber, http://www.holisticonline.com/Herbal-Med/_Herbs/h20.htm
- Herb World News Online — St. John’s Wort http://www.herbs.org/current/stjefficacy.html
Belize
Controversy "Belize Guatemala Dispute"
- ***Anglo–Belize/Guatemala Territorial Issue Title Page http://www.belizenet.com/bzeguat.html
- Belize — Consular Information Sheet http://travel.state.gov/belize.html
- ***CIA — World Fact Book 2002 — Belize http://www.cia.gov/cia/publications/factbook/geos/bh.html
- Belize–Guatemala Relations http://www.belize-guatemala.gov.bz/support/british.html
Factual "Belize narcotics"
- Guardian Unlimited | The Guardian | Why the secret world of Belize business alarmed US drug agents http://www.guardian.co.uk/uk_news/story/0,3604,500941,00.html
Appendix B.4: Search engine characteristics for all URLs (Simple, Controversy, Factual)
Topic Percentage Deep
(Range)Percentage Revealing or Deep
(Range)Revealing or Deep
Low/High EnginePercentage Overlapping
search/multi–search
(Range)Distance Learning 17–21 33–49 google/teoma 35–46/62–74 Albert Einstein 6–11 14–21 alltheweb/google 26–33/49–82 Female Astronauts 16–24 29–37 copernic/google 27–34/56–84 St. John’s Wort 15–22 25–35 alltheweb/teoma 27–34/66–95 Belize 4–8 20–32 alltheweb/google, teoma 232–35/66–855
kept=on-topic and not 404, percentage deep = #deep/#kept, percentage revealing or deep = (#deep + # revealing)/#kept, overlapping = #overlapping second engine/#kept
Editorial history
Paper received 17 November 2003; accepted 20 December 2003.


Copyright ©2004, First Monday
Copyright ©2004, Susan L. Gerhart
Do Web search engines suppress controversy? by Susan L. Gerhart
First Monday, volume 9, number 1 (January 2004),
URL: http://firstmonday.org/issues/issue9_1/gerhart/index.html