Three major botanical institutions, the Morton Arboretum, Field Museum of Natural History, and Chicago Botanic Garden, are developing an online searchable herbarium (vPlants, or "virtual plants") that will provide herbarium specimen data and digital images of specimens and labels to anyone with Internet access. This Web-based system will include a "portal," housed at the Morton Arboretum, and three separate databases housed at and maintained by each participating institution. This virtual herbarium will be designed using state-of-the-art computer and Web-based technology, current standards for the searching and retrieving of data sets, ease of accessibility by any user, and ease of future expansion (enlarged data sets as well as new participants).Contents
Introduction
The Collection: What is a Herbarium?
Project Goals
The Digital Collection
Challenges
Conclusions
Introduction
vPlants, a Virtual Herbarium of the Chicago Region, is a digital collection project funded by a National Leadership Grant from the Institute of Museum and Library Services (IMLS). A partnership between the Morton Arboretum ( MOR), Field Museum of Natural History ( F), and Chicago Botanic Garden ( CHIC), the goal of vPlants is to create a pool of herbarium specimen data and digital images from each institution available via a Web-based portal. A portal is a Web site specializing in a specific field or area of interest. Each institution's data offers a unique glimpse into the flora of the Chicago Region over the last century. By pooling the data sets together (an estimated 150,000 specimens) users are provided with a comprehensive online resource backed by a partnership.
The Collection: What is a Herbarium?
A herbarium houses a collection of pressed, dried plants. Each herbarium specimen contains actual plant material as well as label information detailing attributes of the specimen such as the collector/s, date of collection, and collection site details (e.g., geopolitical location, GPS coordinates, locality).
Figure 1: Herbarium Sheet - Veronica longifolia L.;
Image from the Morton Arboretum Herbarium, Accession #26486.A herbarium records the past, providing users with documented occurrences of plants in specific locations over time. Users of a traditional herbarium include the following:
Users Usage Examples Taxonomists
- Identify and validate specimen data
- Annotate the scientific names used to describe the specimen
- Conduct molecular genetics studies
- Compile regional floras or keys
Conservation Scientists
- Perform research
- Sample plant material for chemical or genetic analyses
Conservation Stewards, Students, and Educators
- Interpret the past for guidance in restoration projects
- Learn characteristics of native and cultivated plants
- Foster future botanists
Project Goals
Resurrect "dead" data
Because of the physical storage requirements, herbaria are usually hidden within an institution, away from the public eye. This project seeks to promote the existence and use of these valuable resources.
Create "collective knowledge"
Through a partnership, we are merging fragmented data sets into a single, cohesive whole. This in turn provides users with a more diverse and complete sample of information. For example, a user interested in county distributions for a particular species can seamlessly review the data from MOR, F, and CHIC in a single, Web-based search instead of attempting to synthesize the data by visiting three separate herbaria.
Leverage the Web to broaden data access
The partnership's herbaria currently require users to physically visit each institution. Generally, users must browse the collection under supervision, sometimes requiring them to have an advanced understanding of botanical nomenclature.
Our goal is not to replace the herbarium, but to foster and broaden its usage by providing users with efficient, easy-to-use data access via the Web. By publishing data on the Web, we will:
- Provide useful information (data and images) without requiring users to physically visit each herbarium
- Increase "walk-in" traffic by giving users a preview of the data before they arrive
- Support access regardless of a user's botanical skill level (e.g., support searches on common plant names)
Provide the potential for future changes in scope
Currently vPlants covers the flora of the Chicago region; however, our vision is to expand on this initial offering. We have approached all decisions and designs with this vision in mind. This potential for expansion is multidimensional and may include one or all of the following:
- Geographic - include plants from outside the Chicago region
- Collections - include other groups of organisms housed in our collections (fungi, non-vascular plants, birds, etc.)
- Partners - include other herbaria, museums, arboreta, and/or botanic gardens
Formulate a generic solution for harvesting metadata
In general, we would like our model to be generic and not project-specific. We hope that other institutions can learn from our experience and apply the vPlants model to fulfill the goal of greater public access to collections.
The Digital Collection
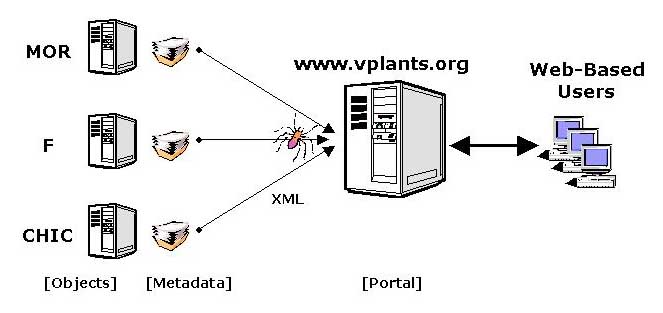
The technical architecture for vPlants is shown below:
Figure 2: The Digital Collection - Technical ArchitectureEach vPlants partner will publish Metadata on the Web describing their Objects (herbarium specimens). On a regular basis, a Web agent (depicted here as a spider) will be dispatched from the portal to harvest the metadata, storing it in a searchable format on the Portal, http://www.vplants.org. A Web agent, which is also known as a "robot" or "web crawler," is a program that traverses a Web site, indexing the sites data in some useable format. This method of data collection is similar to the model followed by commercial search engines such as Yahoo!®, Webcrawler™, and Alta-Vista™. Web-Based Users will have a variety of searches and indexes available, giving them seamless access to the vPlants inter-institutional data set.
Utilization of XML
The Extensible Markup Language (XML) is a structured language used to formally describe or "markup" data. The World Wide Web Consortium ( W3C) provides a basic explanation of XML in 10 points. vPlants will utilize XML in the following two ways:
XML in the back-end metadata exchange
The Web-accessible metadata published by each vPlants partner will be formatted in XML. We feel XML offers the following advantages:
- Provides a robust framework for exchanging data (e.g., numerous tools exist for reading and writing XML data)
- Supports format checking and validation (e.g., we can enforce the requirement that each specimen has a date of collection formatted as DD/MM/YYYY)
- Promotes interoperability as XML gains momentum on the Web
- Support for XML is becoming commonplace in the current software industry
XML in the front-end reporting
vPlants will also utilize XML technology when outputting search results. All portal queries will originate from the database as raw XML data. These streams of raw XML data will be converted into browser-based reports in Hypertext Markup Language (HTML) using an XML publishing framework ( Oracle's XSQL technology). In the future, these same streams of raw XML data may be reused and converted into other formats such as Wireless Markup Language (WML), Portable Document Format (PDF), or native XML data. This reporting model highlights XML's theme of separating content (the raw stream) from format (HTML, WML, PDF, etc.).
Open Architecture
vPlants does not impose any specific hardware or software requirements on its partners. Participants are free to make technical choices based on their skill sets and/or strategic initiatives. For example, MOR and CHIC will be using a Sun®/Oracle® solution for publishing their metadata while F will be using a Macintosh®/Filemaker Pro™ solution.
This platform independence opens the door for future partners regardless of their size, budget, or technical expertise. The only requirement for participating institutions is that they publish their metadata on the Web following the XML standard defined for the project (discussed below).
Challenges
Formulating metadata content and structure
During the first year of the project (2001) we discussed at length the content and structure of the vPlants metadata. With respect to content, our challenge was to select a set of meaningful data fields while considering the ultimate footprint or size of the metadata. For structure, our objective was to arrange the metadata in an efficient manner, avoiding redundancy (e.g., if we have ten specimens of the same species, can the metadata publish the name once instead of ten times?).
For more information, refer to the vPlants Metadata Standards Page.
Finalizing image formats
vPlants will provide digitized herbarium sheets. Research into the size, resolution, and formats of these images is ongoing. The challenge we face is balancing image detail with download time; striking a balance between the two is critical for maximizing usability. We are in the process of publishing a set of prototype images to gain feedback from our users. Our initial offering will include an actual size JPG image (0.5 Megabyte) as well as a MrSID© image.
MrSID is a proprietary image format from LizardTech™ which encodes high resolution TIFF images into smaller sizes, greatly reducing their download times without jeopardizing image resolution. In our case, we are compressing 50 Megabyte TIFF images into 1.5 Megabyte MrSID images. This equates to an estimated two hour savings in download time over a standard 56Kbps modem. The cost for this savings is that users must download and install a MrSID browser plugin from LizardTech. Going forward it will be interesting to see how many users are willing to download this free plugin. Another benefit of MrSID is improved image navigation, allowing users to zoom in or out on specific areas of the image.
Dealing with synonymy
Taxonomic opinions sometimes differ with respect to the scientific name used to describe a particular plant species, leading to situations in which several names represent the same entity. These names are said to be synonyms. For example, the common prairie grass, little bluestem, is referred to by some taxonomists as Andropogon scoparius and by others as Schizachyrium scoparium.
Differences in opinion are inevitable when dealing with inter-institutional plant data. Forcing each institution to accept a particular scientific name is not a viable option. Instead, our goal is to present plant data regardless of a user's taxonomic opinion. vPlants acknowledges synonymy by providing search results for all specimen within a particular synonymy grouping. For example, a search on little bluestem will return all records for both Andropogon scoparius and Schizachyrium scoparium.
To facilitate this strategy, we have created a fully synonymized checklist containing all recognized scientific names for plants of the Chicago region. The United States Department of Agriculture (USDA) PLANTS Database was an invaluable resource in compiling this checklist.
Sensitive data
The handling and presentation of sensitive data, such as GPs coordinates for a rare or endangered species, was a topic acknowledged by the vPlants partners. Our current strategy calls for each institution to suppress any location data for rare or endangered species.
Conclusions
We have posted a prototype at the vPlants Web site containing live data for a variety of plant families. We encourage feedback and ideas from our potential users.
Looking to the future, we are excited about the potential for expanding our data content and scope, and "opening" our collections to the public. We are currently pursuing the creation of species pages to complement the specimen details available at vPlants. Species pages will present general information for a given species. This provides the general public with a useful learning tool, preparing them for the more detailed specimen data. We are actively pursuing other partners for inclusion in the portal.
About the Authors
Matthew Schaub is the technical lead for vPlants. He has a B.S. in Computer Science from the University of Iowa. He is the Manager of Information Technology at The Morton Arboretum.
E-mail: mschaub@mortonarb.orgChristopher Dunn is PI of vPlants and is Director of Research at The Morton Arboretum. He earned his PhD in botany and ecology from the University of Wisconsin - Milwaukee.
E-mail: cdunn@mortonarb.org
Editorial history
Paper received 24 April 2002; accepted 26 April 2002.


Copyright ©2002, First Monday
vPlants: a Virtual Herbarium of the Chicago Region by Matthew Schaub and Christopher P. Dunn
First Monday, volume 7, number 5 (May 2002),
URL: http://firstmonday.org/issues/issue7_5/schaub/index.html