The Online Archive of California (OAC) is a digital information resource that facilitates and provides access to materials such as manuscripts, photographs, and works of art held in libraries, museums, archives, and other institutions across California. "Museums and the Online Archive of California " (MOAC) is a series of projects enabling museums to participate in the OAC. This paper describes MOAC from an operational as well as theoretical point of view, forming a case study in large-scale integration of access to museum and archival materials.Contents
A Little History
Goals and Challenges: or, What Were We Thinking?
Approaches: Shared Standards for Describing Collections
Approaches: Standards for Structuring Complex Multimedia Objects
How it All Works Together
Tools
Project Workflow and Management
Research Agenda
Concluding Thoughts
A Little History
"A core component of the California Digital Library, the Online Archive of California (OAC) is a digital information resource that facilitates and provides access to materials such as manuscripts, photographs, and works of art held in libraries, museums, archives, and other institutions across California. The OAC is freely available to a broad spectrum of users - students, teachers, and researchers of all levels. Through the OAC, all have access to information previously available only to scholars who traveled to collection sites" [ 1].In 1995, the University of California began a digital library project, called "UC-EAD", which involved archives and special collections libraries from across the nine UC campuses. Together, these partners began testing an emerging standard, "Encoded Archival Description" or EAD [ 2], as a way of allowing these institutions to provide integrated online access to collections information for students and researchers. In 1998, the OAC expanded beyond its roots as a UC cross-campus project into a California statewide project involving dozens of archives, special collections libraries and historical societies from university, public, and private settings. With State Library funding the project took three important steps toward expansion. First, the name of the project was changed from UC-EAD to the Online Archive of California. Secondly, administration of the project moved from UC Berkeley to the more campus-neutral California Digital Library, a division of the UC Office of the President in Oakland, Calif. Another step came when the Berkeley Art Museum/Pacific Film Archive approached the OAC with a proposal to bring museums into the mix, rounding out the OAC as an online resource integrating every major type of cultural collection. The OAC gladly agreed, and collaboration began in the form of a project suitably called, "Museums and the Online Archive of California" or MOAC [3].
Just as the OAC has the grand ambition to create a standards-based and scaleable solution which will, theoretically, allow every library, archive and historical society in California to share collections online; MOAC began with the equal ambition to create a way of allowing every museum in the state to participate and share its collections via this resource. Such a project is especially challenging in a state like California, which, because of its size, large population, and relative wealth, has a very large number and variety of cultural institutions and collections. It was decided that it would not be prudent to just throw the doors of the OAC open to all museums at once, but rather to conduct a pilot project involving a limited, but representative selection of museum partners who would test the process and hopefully map the territory allowing other museums to participate in this large and uniquely integrated environment. The Berkeley Art Museum/Pacific Film Archive had been implementing the EAD to describe its own collections for a while, but was hardly the only museum in California with relevant experience in digital presentation of collections which would be necessary for such a project. Other California museums quickly came together to form the museums who would initially participate in MOAC. These partners purposefully include small and large museums, university and public museums, and represent collections ranging from art to photography to historical/ethnographic materials to anthropological artifacts. Current participants in MOAC include:
- Berkeley Art Museum/Pacific Film Archive
- Bancroft Library, UC Berkeley
- Phoebe Hearst Museum of Anthropology
- Japanese American National Museum
- UCR/California Museum of Photography
- Grunwald Center for Graphic Arts, UCLA
- Oakland Museum of California
- Museum of Paleontology, UC Berkeley
- Cantor Art Center, Stanford University
- Fowler Museum of Cultural History, UCLA
In October 1999, MOAC received funding from the Institute of Museum and Library Services ( IMLS), and is now approaching the second year of funded activity.
Goals and Challenges: or, What Were We Thinking?
From the beginning, MOAC has been an effort toward integration and collaboration across many communities. MOAC is testing the integration of collections information from diverse types of museums, but is also working on how to then allow these museums to collaborate with the larger cultural heritage community of libraries and archives. Beyond these daunting challenges of diversity and scale, MOAC took on a few other fairly unique tasks. MOAC deals with describing and representing individual museum objects of course, but is also concerned with describing museum collections - that is to say, groups of meaningfully related objects within a museum. Such collections may be related by artist, as is the "Theresa Cha Conceptual Art Collection" at the Berkeley Art Museum; or related by period and medium as is "Stereograph Images of California" at the California Museum of Photography. An expanded discussion of archive and museum descriptive practices is included below. The approach of MOAC is to describe collections in a hierarchical way which allows multiple types of use, for instance allowing a researcher to search and find a single object, or allowing them the benefit of context and organization inherent in browsing a whole collection. It should be noted that this multiple functionality puts a high demand on the tools (search engines and databases) used to present the EAD online. For instance, while this dual functionality is possible with some tools, the current software used by OAC, DynaWeb, does not readily provide this kind of functionality and, for this and other reasons, it is being replaced.
Another aspect of presenting collections MOAC is tackling is the description and presentation of complex multimedia objects - for instance representations of art works which are comprised of more than one image or piece. Such works include Asian scroll paintings, artist books, or installation art works - all of which require multiple images to represent the whole work in detail. These images must be structured so that they can be intelligently and conveniently navigated by the user and still understood to comprise one 'object' in the collection. So, instead of presenting museum collections as a series of discrete objects accompanied by one view each, MOAC is exploring methods of presenting structured collections and structured objects.
One of the specific goals of MOAC is to explore the use of the EAD standard in museums as a way of allowing integration of museum information with archival and library collections in one online resource, and as a way of describing structure and relation between objects in a collection. Another goal is to test the use of EAD with object or item-level description (more common in museums than archives) and with images. Lastly, MOAC is testing the use of the Making of America II (or MOAII) standard [ 4] for describing and navigating complex multimedia objects. Approaches toward these goals are described below with notes on progress and hindrances.
Approaches: Shared Standards for Describing Collections
The EAD remains the core standard used by the OAC. The EAD is an XML DTD (a specific set of XML tags and rules) to 'markup' or electronically encode finding aids, inventories, and guides to collections. The end result is one text file which includes the actual guide to a collection, including any number of individual object records belonging to that collection, and the EAD tags. The guide is structured hierarchically, so that at the top you identify and describe the entire collection, then as you move down, you describe sub-groups of objects, and list individual object records. At any level in the document, but probably at the level of the object record, one can include EAD tags to link or display multimedia files such as a thumbnail image of the object.
Below is an example of one object record (an artist book), exerpted from a collection guide, shown with EAD markup:
<c01 id="bampfa" level="item">
<did>
<daogrp>
<daoloc href="http://www.bampfa.berkeley.edu/moa2/servlet/archobj?DOCCHOICE=1992.4.91.moa2.xml" role="hi-res"></daoloc>
<daoloc href="http://www.bampfa.berkeley.edu/docs/images/bampfa_1992.4.91_136_3.jpg" role="thumbnail">
</daoloc>
</daogrp>
<origination>
<persname> Theresa Hak Kyung Cha </persname>
</origination>
<unittitle> Pomegranate Offering </unittitle>
<unitdate> 1975 </unitdate>
<repository> The Berkeley Art Museum / Pacific Film Archive </repository>
<unitid> 1992.4.485 </unitid>
<admininfo> Gift of the Theresa Hak Kyung Cha Memorial Foundation
</admininfo>
</did>
</c01>
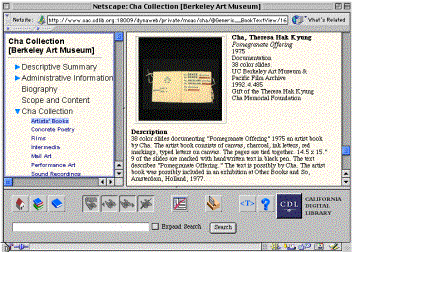
Below is an example of how the above markup appears when presented online in the context of the collection guide:
The main benefit of testing the EAD for museum use is of course that if museums can share information about their collections in EAD format (among other standardized formats), that allows museums to immediately share collections information in integrated systems such as the Online Archive of California, Research Libraries Group, Library of Congress and many others. The other benefit of EAD is that museums can describe not only individual items in their collections with as much detail as they want, but can also describe the context of an entire collection, such as the biography of the artist or historical period that joins a group of objects. These relations are sometimes implicit in standard collections databases by the presence of keywords across several object records which link them for searching purposes, but the EAD allows museums to present that context in an explicit manner, relating objects in human language for the user to facilitate not just retrieval, but understanding.
The archival community developed the EAD and so its method and language come from that community. For instance, a list of individual objects in a collection described in EAD is called a "container list" - hardly an intuitive term for a museum registrar or IT professional. However the semantics of the tags are not the obstacle MOAC partners at first thought they might be. For the most part the semantics are easily overcome or translated for two reasons. First, the public does not need to see any of this jargon, and only sees what the encoding institution chooses to name an object or group of objects. The second, and most important reason, is that even when the term for describing a collection may differ between archives and museums, the principle is usually the same and an equivalent term and concept can be readily found. For instance, some of the core tags of the EAD are listed here with 'museum' semantic equivalents: origination (creator or collector), unittitle (object title), unitdate (object date), dimensions (dimensions), and adminifo (credit line).
As it turns out, a far greater challenge is in defining what a 'collection' is in the first place. Archives organize and describe their collections based on the principles of provenance and original order. An archival collection is a group of items that have a shared history and provenance. The history of the collection, who generated it, who collected it, and where it has been is more important than the history of any one object in that collection. Moreover, items in a collection always remain in that collection, preferably in the same place with relation to other items, in their original order. So, when archives use the EAD, they are often describing the history of who owned the collection, and they describe items, the container list, in the original order that they received them. Of course museums use a hybrid of organizational models for collections. Sometimes, as with archives, provenance is paramount, and a museum collection may be named for the donor (the Guggenheim's Panza Collection). Sometimes the story of a donor and collection is the story of the founding of the museum itself and would surely be represented. However, museums also organize collections in other ways, grouping together objects by same artist (Hans Hofmann collection at BAMPFA), or media (photography collection at MOMA), or historical period (Renaissance prints at the DeYoung Museum). Mixed models of collection organization often exist side by side in the same museum. The EAD itself does not prescribe how a collection is described in this overall sense (since in actuality archives occasionally describe collections in alternate ways as well), but the problem arises when sharing collection guides in a shared online system such as the OAC. Users may come to the system expecting all collections to be presented under the same principles of provenance and original order, and could become confused to find some collections organized by say media instead.
It may be a significant byproduct of the project to have teased out this conceptual dilemma in the context of online access so that it may inform further development of OAC and add to the museum community's larger discussion of how we describe and relate objects within and across projects. How this particular issue will play out for the majority of users of the OAC remains to be seen, but in discussing it, members of MOAC and the OAC have begun an intriguing cross-community conversation, and may even have unintentionally come across a potential solution, as follows. One problem with creating shared systems such as the OAC is that the EAD, like many standards, is very flexible, and can be used in very different ways by different institutions. Some can use more or fewer tags than others, or in different order, resulting in collection guides which function very differently for searching and look very different from each other to the user. This is not unique to the EAD, and many shared systems built upon standards are now beginning to define 'content standards' - that is rules defining how exactly to implement the shared standard for any one purpose. A standard, such as the EAD, Dublin Core, or MARC, must be somewhat flexible if it is to be adopted by a wide variety of institutions, but to ensure consistency within any given system, a content standard is usually defined by participants in that shared system which defines which tags to use, which are required, and in what order they must appear for data contributed to that shared system. OAC administrators knew from an early point that they would need to develop content standards for archives using the EAD to submit data to the OAC, and in discussing that content standard with museums it is becoming clear that OAC may need two content standards; one for each community. What if we can use this new "problem" to our advantage however?
Perhaps one way to allow different communities (such as museums and archives) to reap the benefits of sharing a standard such as the EAD is to define different content standards for each community. In this way, most cross-functionality can be preserved, but when descriptive practice dictates that tag requirements or order should be different, it can be. If this solution is adopted, it requires two more questions to be answered. Even if two communities can adopt slightly different ways of implementing a shared standard, can one system - such as OAC - really contain both styles without adversely affecting functionality? Secondly, how does the system go about explicitly documenting and identifying the two methods so that the system or the user can tell the difference between the break in absolute consistency?
To answer these questions and make the whole system work, all communities involved must create detailed data-mappings between content standards, so that cross-searching between all collections remains viable. For instance, if the OAC allows users to search all collections by 'title of collection', then both the archival and museum content standards for using EAD should dictate that the tag for 'title of collection' should be required and filled. One further possibility is that the core search could search across all EAD encoded collections, and then alternate pages or interfaces could allow users to search only certain types of collections in more specific ways. MOAC is already exploring this, as the user can now search across museum and archival collections from the OAC main page; however in the "MOAC portal" - a separate interface to the same database - users can limit their search to just museum collections, and search by museum-specific information such as "media/materials". The content standards for EAD in the OAC will likely differ only about 10-20 percent between museums and archives, and MOAC will find out if that amount bends or breaks the OAC as a shared system for museums, libraries and archives. Finding the exact percentage of difference in content standards that begins to affect functionality in a shared system generally is still an outstanding question, and it would be interesting to have data from several testbeds beyond MOAC in order to determine if there is a universal "breaking point" or limit to this solution.
Approaches: Standards for Structuring Complex Multimedia Objects
One interesting area of investigation in MOAC, representation of digital media files, is an area that is so new as to be unencumbered by past traditions of descriptive practice between museums and archives. As mentioned before, some museum objects are fairly simple objects such as the flat, delimited plane of an easel painting. These objects require a fairly simple form of visual documentation - usually one image, at multiple resolutions, will do the trick. In an online environment, these are deployed as one thumbnail image which appears alongside one object record, creating an easy 1-to-1 relationship. The user can click on the thumbnail and access a higher resolution of the image. However, many museum, library, and archival collections contain works which are not sufficiently represented by the 1-to-1 model. These complex or compound objects require more than one image to be viewed in any detail. This small change radically alters the methods needed for managing and navigating these images online.
For instance, when one object record describes an artist book, one image would only depict the cover of the book - a teaser not useful for research even at high resolution. Imaging the entire book is much more desirable; but even when that is accomplished, how does one relate the individual page images and present them on-screen so that they can be navigated by the user effectively? In another instance, many Asian scroll paintings have long, thin proportions which are not compatible with the "thumbnail" rectangle of most collections access systems. To picture the entire scroll in one thumbnail image would present a thin light bar across the center of the image, leaving out so much detail as to make them all look the same. When accessing a larger version of this work, one image of the entire scroll at a sufficiently high resolution would be far larger than most bandwidth currently allows. Instead, one needs a way of presenting several high-resolution sections of the scroll which can be 'stitched' together for viewing as a complete whole. Site-installation artworks often exist in environments which cannot be accurately represented by one image. Angle and side views of sculpture also require many images to be somehow related to one object record and navigated in a way that makes sense.
To represent these latter works online, the museum needs not only a couple of resolutions of one image, but now also needs to manage several resolutions of several images - all representing one work in the collection. The museum needs metadata describing the relationship of one image to the next, and the structure of the complex object overall, so that it can be navigated - for instance, so that one can view an artist book in page-order, and even jump through the book to an exact page or chapter. In short, the museum needs a metadata system which is nearly as detailed and flexible as the system for describing the collection itself.
While MOAC uses the EAD as an international standard for describing the structure and detail of a collection (the actual physical collection) - MOAC has adopted the MOAII standard for describing the structure and detail of complex objects (and their digital surrogates) within a collection. MOAII is also an XML DTD, which describes in similar hierarchical fashion the structure and digital image metadata associated with any one object or work. The end result is a sort of mirror of the EAD; one text file which includes the structure of a complex object, including any number of individual images belonging to that object, and the MOAII tags. The MOAII XML document is structured hierarchically, so that at the top you identify and describe the entire object (say an artist book), then as you move down, you describe sub-groups of images (say those belonging to the same chapter), and list individual images (say page images). MOAII shares some of the benefits of being a standard in the making. Several of the institutions which developed the MOAII DTD; the UC Berkeley Library, Cornell University, New York Public Library and others are deploying the standard as well and creating a community of users which can leverage resources, experiences, and content.
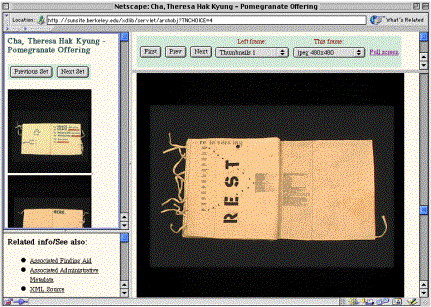
MOAII allows software, such as a server application or Web browser, to act on the MOAII XML document to display the object. The metadata is structured in such a way that one can simply "flip" or browse through the images, or one can jump to a particular chapter title or page number to get that exact image. One of the most intriguing features of the MOAII DTD is that it also allows the museum to capture the transcript of each page of an artist book, and then allows the user to search for keywords as they appear on a page to retrieve that page, or to display the transcription when the original page text may be in a foreign language or difficult to read. The Berkeley Art Museum has used MOAII to present 60 artist books from the Theresa Cha Conceptual Art Collection online as part of the OAC. These 60 works include hundreds of page images and transcriptions.
Below is an example of one page from the above artist book, exerpted from the larger MOAII document representing the whole book, shown with MOAII markup:
<File ID='bampfa_1992.4.485_14_3' MIMETYPE='image/jpeg' SEQ='14' X='150' Y='150' UNIT='PIXELS' CREATED='10/31/2000' OWNERID='bampfa_1992.4.485_14_3.jpg' ADMID='ADM3' GROUPID='517' USE='THUMBNAIL'>
<FLocat LOCTYPE='URL'>http://www.bampfa.berkeley.edu/collections/bam/images/moa2/bampfa_1992.4.485_14_3.jpg
</FLocat>
</File>
Below is an example of how the above markup appears when presented online in the context of the entire artist book in digital form:
MOAII is metadata - it allows MOAC to manage and display digital images in groups and sequences, but it does not spell out the requirements for the digital images themselves. To define the requirements for digital images, MOAC looked toward the California Digital Library Digital Image Specifications, a sort of 'content standard' for digital images submitted to the OAC, adopted them with a few revisions, and folded them into the MOAC Technical Specifications (available on the MOAC Web site at http://www.bampfa.berkeley.edu/moac/moacfullspecs.html). The specifications for image files outlined some general concepts and goals such as the ability to re-purpose images across print, fixed, and network media and a strategy of one "master" or very high-resolution original file which is not modified after capture; and several optional "derivative" image files for delivery which may be altered, color-corrected, cropped and so on. The specifications dictate such other details as 1) all thumbnails should be150 pixels along the longest edge 2) thumbnails and other derivative filesshould be in the JPEG or GIF file format 3) master files should be in the lossless TIFF format and have at least 3000 pixels along the shortest edge.
At this point in time, MOAII deals well with 'book-like objects' such as diaries, albums, and of course artist books. The Berkeley Art Museum will be testing MOAII on a collection of Asian scroll paintings to see if it can be successfully adapted or extended. MOAII appears a promising direction to pursue for managing and presenting complex objects comprised of discrete, static images such as books, rooms, sculptures, and scrolls, but what about time-based media such as digital representations of film, video, and audio collections?
An intriguing direction to explore for time-based media would be the Synchronized Multimedia Integration Language (SMIL) [ 5]. SMIL is a W3C standard for describing the structure and allowing navigation of complex multimedia files - acting on time-based media in much the same way that MOAII acts for static images. The SMIL standard is also XML-based, and allows one to position multimedia files for display, carefully time the playback of multiple audio and video streams at once, and - again like MOAII - includetranscriptions for video or audio. Lastly, like MOAII, SMIL is a metadatastandard which could greatly aid in the management and presentation of multimedia files, but would not dictate the format or standards for the actual multimedia files. So, again MOAC would need to develop or adopt some 'content standards' for implementation of SMIL, and some specifications with relation to the actual media files as well.
How it All Works Together
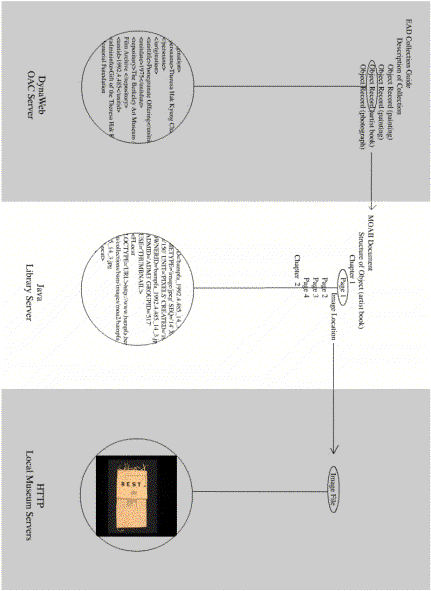
At this point it would make sense to explain how all these standards and XML files work together in the OAC environment. Currently there are three main content types within the OAC and these are deployed in three areas which make up the broader technical environment of the OAC. Following is a description of the content types and how they relate to one another.
The first type of content is the description of actual (physical) collections. This takes the form of one text document, a collection guide, which contains some administrative data about the museum, followed by optional curatorial text about the collection in general, and followed then by object records for each object within that collection. This text contains the EAD tags as required and ordered by the MOAC Specifications. In each object record that includes an image(s), two things occur. First, there is a link in the EAD document similar to an IMG tag in HTML. This link creates a link to a thumbnail image which appears inline on the page next to the object record when it is viewed. Secondly, if the object is a complex object, such as an artist book, then another link is embedded in the EAD document. However this one does not present anything inline, but rather creates a hyperlink from the thumbnail image to the MOAII XML document which contains the image metadata for that artist book. When a user clicks on the thumbnail image, they leave the EAD encoded object record, and are passed along to a MOAII encoded document which presents that one object. An EAD collection guide then can include links to hundreds of images and hundreds of MOAII documents. These EAD documents all reside centrally on a server at the OAC HQ in Oakland, Calif. where they can be searched and accessed by visitors on the Web using DynaWeb, an SGML/XML search engine. Dynaweb converts the EAD XML into HTML on the fly so viewers do not need any special software.
The second type of content is the metadata which describes the structure and images that represent complex objects. This content takes the form of a MOAII XML encoded text file. Each file represents one complex object (one artist book). All MOAII files currently reside on a separate server at the UC Berkeley Library. When a visitor is passed on from an EAD object record to the accompanying MOAII file, they activate a file on the MOAII server which serves out that MOAII file using a Java servlet (server-based applet) to present all the images from that artist book. The Java servlet converts the MOAII XML to HTML on the fly so that viewers can use any standard Web browser.
The third content type is the images themselves. MOAC is testing an innovative approach to image storage and access in shared systems, and the images are stored in a couple of optional ways. Some MOAC partners who do not have their own webservers online store their images centrally on the OAC server. However, most of the larger MOAC museum partners store all their images locally, on their own museum webserver. The files are accessed when viewers view the EAD files, and again when they view the MOAII files. The OAC does not store copies of these images, but they do have the MOAII XML which helps the OAC manage all the image metadata associated with the OAC. For instance from these files they know exactly how many, and which files are associated with each collection and each individual object. They know exactly where these files should be, and what format and size they are. The MOAII XML files are maintained via XML catalogues so that if a museum changes the location of their images, it is easier to update the link from the OAC. One means of doing this is to generate new versions of the EAD and MOAII XML files using a local database tool (explained below) and upload to the OAC. However, the exact mechanism for updating image location information is one of the near future concerns of the OAC.
The figure below illustrates three content types within OAC environment:
Tools
This section will outline how each type of XML metadata is generated by MOAC partners and how it is delivered online to the public. Correspondingly, software tools used for the OAC are broken down here into two basic types; access/viewing tools and management/authoring tools.
As mentioned earlier, OAC uses the commercially available SGML/XML search engine, DynaWeb, as its public search and delivery tool. Dynaweb is powerful and robust, able to support a large resource like the OAC. However, Dynaweb is being phased out of production, and lacks some of the features identified as key by OAC committees and partners, so a replacement tool is being sought. Dynaweb is expensive by museum standards, and its replacement will likely be expensive as well - given the demand for both sophisticated features and robust performance. Dynaweb is not the only XML search engine available of course, and the Berkeley Art Museum has been using a freeware package called Isite, another Unix-based XML search engine, to deliver BAM EAD and other XML files locally on the BAM Web site. Isite is powerful for freeware, but it is not configured for native translating of XML into HTML for easy viewing, and comes without support.
The MOAII files must also be served out via XML-capable software. At present, the OAC requires MOAII software which can present MOAII XML, but it does not need to be searchable. So, staff at the UC Berkeley Library have written a Java servlet to deliver MOAII XML on the web, and are continuing development of this tool.
As one can glean from reading this, hosting an XML-based shared resource is no small technical feat, and is made especially daunting by the surprising lack of inexpensive tools for accessing and viewing XML data on the Web. Many cultural community standards are based on the much-touted XML standard. The promise of XML is that since it will be the basis of so much Web content will be based on it, vendors will develop a wealth of diverse tools for delivering XML. This will surely happen, but it is happening at a much slower rate than predicted. For instance, both Internet Explorer 5 and Netscape 6 can both natively display XML. However, each uses a separate stylesheet mechanism (IE uses XSL, Netscape CSS); making either one solution only applicable to one browser. Browser-native display is only half the battle anyway; as most sites would like to allow users to search data which is complex enough to warrant XML in the first place, and browser-viewing only solves the viewing portion and not the search function. For this, we need XML search engines, preferably software which can also convert XML into HTML for cross-browser viewing. Such XML software is here; but in the form of very expensive big-business-2-business software. It appears that XML software aimed at the consumer or mid-level market has yet to arrive. XML is being used on an increasing scale, and until cheaper software arrives, XML based standards seem best suited for the interchange of information between institutions or the sharing of information in larger, consortia-based resources such as the OAC. Locally, it would seem wise to convert XML data into a more usable format for deployment, and institutions should be able to export their own data into XML for interchange.
On the management/authoring side however, MOAC is happy to have made more significant progress toward a scaleable solution. Staff at the UC Berkeley Library began development of a project management database for managing digital imaging projects associated with the OAC. An empty version of this database, developed in MS Access, was distributed to OAC partners for local use. Since some museums in MOAC are Macintosh-based, and Access does not run on Macs, the Berkeley Art Museum set out to develop a parallel tool using FileMaker Pro. MOAC partners chose to use either database based on local platform or choice of features. The BAM database, dubbed the Digital Asset Management Database or DAMD, is now in beta form and has been distributed to MOAC partners where it has been used for its two main purposes; management and data conversion.
The DAMD database is intended to capture, manage, and track digital image metadata produced during the imaging workflow. The database was structured using the same CDL Imaging Specifications that the MOAC Specifications were built upon. DAMD is made to hold descriptive data about collections (needed for the EAD collection guides) as well as metadata about digital images and complex objects (needed for MOAII files). DAMD is a gathering place for this collections-related information. Object records are exported from the museum's existing collections management system and imported into DAMD. Data is then input to DAMD during the digital imaging workflow which links digital images to their respective collection records, and describes metadata about the image's file format, location, and it's place within a complex object. Lest this sound like an enormous amount of data entry; most of the data in DAMD is not hand-entered, but rather is automated. For instance, the object records are imported from an existing database, and most of the digital image metadata is repetitive (copyright holder, file format, storage location, color space, etc) and thus is set up once at the start of digitizing a collection and then is auto-entered by the database for each image. Once this information is gathered into DAMD, it can be maintained long term and used to manage the museum's digital assets if needed.
The other purpose of DAMD, data conversion, fills an even wider gap in the current software market by automating the process of marking up data into both EAD encoded XML files and MOAII XML files. Once the aforementioned data is gathered into the database, one can simply choose to export data into EAD format. Choosing a collection and clicking on the EAD Export button triggers a series of scripts which create the fully formed EAD XML file, compatible with MOAC content standards, and puts the EAD file on the computer hard disk so it can be uploaded to the OAC. One can also choose an individual object and export the MOAII XML file in the same manner [ 6].
This is a significant step in the MOAC project because it may reduce the cost of participation in MOAC by minimizing and collapsing the labor into one inexpensive, automated tool, and by reducing the need for expertise in EAD or MOAII XML markup at the local institution. Lastly it may provide a model for the vendor community in providing inexpensive tools which can export/convert local museum data into standardized formats (ideally not just EAD, but also Dublin Core and others), thus allowing participation in any number of consortia projects which use that standard. One of the reasons most museums choose to participate in only one major consortia project is because it is so labor-intensive to map and convert the museum's data into the required formats. If tools are developed which can easily export museum data into not just one standard, but in fact several of the most commonly used standards for collections information, it could greatly increase the sharing of collections information between and across projects and communities.
Project Workflow and Management
Since a main goal of MOAC is to test methods which could allow all types of museums in the state of California to participate in the OAC, MOAC has been developing project methods which are scaleable, enable partners to be largely self-supporting and to exert local control. For instance, MOAC is testing the ability of museums to store images locally for maximum local control of primary resources. This also allows OAC to scale up quickly as it is mostly metadata text files and not images that need to be stored centrally. Developing tools like DAMD enable partners to cost-effectively manage all types of data locally, and allow museum partners to export information exactly conforming to OAC specs easily and quickly.
MOAC is like most other consortia projects in that partners communicate regularly via e-mail discussion lists where such topics as content standards are worked out. MOAC also meets at centralized meetings once a year for training with tools and in-depth discussion of relevant technical specs and workflow issues.
One key aspect of MOAC is the iterative development of the MOAC resource. Often in consortia projects, partners meet early to work out standards issues, then retreat for the main portion of the project to digitize content, and then gather together again at the end of the project to make one heroic effort to bring together all the content created in the preceding months. It is often a massive, one-time effort at the end of the project and thus accomplishes the gathering of content, but not the documentation of a repeatable method for creating a sustainable resource. In the two-year MOAC funding period, MOAC partners will go through the process of gathering data, vetting it, converting it, submitting it to OAC and seeing it go online every six months. By repeating the entire practical production process in six-month iterations, MOAC stands a better chance of working out the glitches in the process and developing a sustainable method for museums across California to participate in the OAC.
Though it may not be a systematic aspect of MOAC, part of its progress is made possible by the enduring patience, expertise, and collegiality of all the partners from the UC Berkeley Library to California Digital Library to each of the museum partner liaisons. Despite the challenges of working with such large numbers of institutions across communities with different professional languages and institutional cultures, the mission of the OAC to serve the public in an open manner so closely mirrors the missions of each partner that in the end everyone comes together.
Research Agenda
Some potentially valuable lessons already learned by MOAC include; starting small and scaling up; working in iterations to enable learning and not just production; and, adapting widespread standards when possible and developing community-specific content standards when necessary for maximum leverage of standards for sharing information on a truly wide scale. However, many important questions remain to be answered before projects like MOAC can be repeated, expanded, and sustained for the long-term in a mainstream production mode. These questions include:
- What metadata standards can be adapted, or need to be developed, to enable management and presentation of time-based film, video, and audio collections? Could SMIL be used alongside MOAII to represent multimedia collections?
- What multimedia content standards should be used in creating time-based multimedia files themselves? Is MPEG practical? Are proprietary formats such as QuickTime or RealMedia acceptable solutions?
- Can images effectively be stored locally and used for multiple, separate access projects? If so, what is the reliable mechanism for allowing projects to update and locate images? If not, is it more desirable to allow multiple copies of image files to exist at each access project site?
- Beyond static image files and time-based linear media like video and audio, what metadata standards and formats should be used to describe, present, and navigate native-digital collections (such as digital net.art increasingly being collected by art museums)?
- How can the cultural heritage community present the case that a market exists for small to mid-level software tools for authoring, managing, searching, and viewing standards-based XML formatted information?
- How can we reduce the cost of participation in consortia projects so that museums can afford to share collections in more than one place, each consortium adding value in its own way?
- How can we share information about 'best practices', success and failure stories across different projects, to help museums along any portion of the decision tree? [ 7]
- How can we develop or document necessary training for museum professionals in information and media management? [ 8]
- How can we gather more detailed and substantive information on how different audiences actually use online collections resources and what they expect of them? Is there a gathering place for such reports on this topic, like that authored by Howard Besser about the Museum Educational Site Licensing Project [ 9]? Are there effective, inexpensive methods for including such research in every collections access project?
Concluding Thoughts
Whatever the outcome of specific MOAC investigations, the project as a whole has already proven valuable in bringing diverse communities together to begin discussing how to close the seams of broad-based access to cultural heritage collections. MOAC leaders and partners from every community must keep an open mind about what might work, and what should be allowed to fail. Museums have been around for centuries, and yet the type of networked, always-available, comprehensive, open, audience-controlled access to collections that many consortia are exploring today is only a few years old. It behooves us all to learn from each other's experiments and to innovate. Such synergy, which on the best days one can liken to the energy in a barrel full of monkeys, is more important now than it ever was.
About the Author
Richard Rinehart holds a joint appointment at the University of California, Berkeley, as Director of Digital Media for the Berkeley Art Museum/Pacific Film Archive, and as Faculty for Digital Media in the Department of Art Practice. Richard is project manager for two museum consortium projects: "Museums and the Online Archive of California", bringing together 12 museums with the archives and libraries across the state of California to provide standards-based access to collection; and "Conceptual and Intermedia Arts Online" a consortium of 14 art organizations providing standards-based access to non-traditional art material. Richard serves on the Boards of Directors for New Langton Arts, and for the Museum Computer Network, the international organization for museums and technology.
E-mail: rinehart@uclink.berkeley.edu
Acknowledgments
A version of this paper appeared in the Spring 2001 issue of Spectra: Journal of the Museum Computer Network and is reprinted here with the kind permission of Spectra.
Notes
1. http://www.oac.cdlib.org, accessed 19 April 2002.
2. http://www.loc.gov/ead/, accessed 19 April 2002.
3. http://www.bampfa.berkeley.edu/moac/, accessed 19 April 2002.
4. http://sunsite.berkeley.edu/moa2, accessed 19 April 2002.
5. http://www.w3.org/AudioVideo/, accessed 19 April 2002.
6. For a more detailed analysis of the DAMD database, see Guenter Waibel, 2000. "Produce, Publish and Preserve: A Holistic Approach to Digital Assets Management," Spectra (Fall), pp. 38-43, and at http://www.bampfa.berkeley.edu/moac/imaging/, accessed 19 April 2002.
7. For information on a current project documenting "Best Practices in Networking Cultural Heritage" conducted by the National Initiative for Networked Cultural Heritage.
8. Watch the MCN Web site at http://www.mcn.edu for news on the "MCN Curriculum Project" which is creating an ongoing, modular set of classes on different topics beginning with an introductory course on selecting a collection management system.
9. http://sunsite.berkeley.edu/Imaging/Databases/1998mellon/, accessed 19 April 2002.
Editorial history
Paper received 18 April 2002; accepted 19 April 2002.


Copyright ©2002, First Monday
Museums and the Online Archive of California by Richard Rinehart
First Monday, volume 7, number 5 (May 2002),
URL: http://firstmonday.org/issues/issue7_5/rinehart/index.html