This paper describes the basics concepts of first-degree, second- and third-degree price discrimination. The author then expands on the second-degree concepts by illustrating how managers could exploit quantity-, features-, performance-, and time-based discrimination approaches. The paper differentiates the affiliation-based discrimination concepts, and presents strategies of symmetric and asymmetric quality adjustments for the positioning multiple information products in markets.Contents
Introduction
The use of differential pricing for self-selection
First-degree price discrimination
Second-degree discrimination: Quantity-based approach
Second-degree discrimination: Features-based approach
Second-degree price discrimination: Performance-based approach
Second-degree price discrimination: Time-based approach
Third-degree price discrimination: Affiliation-based discrimination
Setting pricing strategies for individual information goods
Strategies for capturing incremental surplus from customers: Setting flat prices
Strategies for capturing incremental surplus: Symmetric and asymmetric quality adjustment
Summary
Introduction
The era of electronic processing, storage and distribution of information goods [ 1] has reduced the marginal costs of duplication and distribution of information goods. Nevertheless, information industries still have to cover large fixed costs needed to pay their managers, writers and the fixed costs of acquiring information. This means that the cost of creating the first copy of an information good remains very high, while the costs of making additional copies of the original document is nearly zero. For example, one incurs up to 70% of the total publication costs of an academic journal just to produce the first copy [ 2]. In some of these industries the use of marginal costs for determining the price of an information good may not guarantee the overall profitability of an organization. This cost structure suggests that it could be profitable for a producer to have multiple prices for the same information goods rather than a static pricing policy. For example, the customer who buys the first two information goods produced by a firm may have to pay a higher price than the customer who buys the 5,000th product. One could justify this policy on the grounds that it is more expensive to produce the first two copies than the 5,000th unit. Furthermore, different customers may have radically different (heterogeneous) valuations for the same information good [ 3]. While some individuals may be willing to pay $200 for a specific book, others may be willing to pay barely $100 for the product. Naturally, the idea of charging each customer the maximum price she or he can bear becomes attractive.
Unfortunately, these ideas are not that easy to implement. In the former case, customers may resist paying different prices for the same information good. Some might even buy the goods at the cheap price and try to sell it in the high-end market (black-market phenomenon). The problem with the latter idea, which focuses on customer valuation, is the lack of access to this kind of information. Even if customers had a defined valuation for each information good, a producer of information goods cannot guarantee that each customer would rate the information goods higher than the marginal costs of production. Producers manage these risks by providing self-selection opportunities for customers. Group-based flat pricing is one of the most common methods used to get customers to self-select themselves [ 4].
This paper extends current literature relating to self-selection strategies for information goods by framing current practices into systematic concepts. The paper identifies new approaches that could be, and are being, used to achieve second-degree and third degree price-discrimination concepts. The work differentiates features-based and performance-based discrimination approaches. Features-based differentiation exists when a producer reduces or deactivates certain features of an information good to create differences in quality. Performance-based discrimination is practiced when producers maintain almost all features of information products, while limiting the quality of the features of the output. The paper makes the argument that that performance-based discrimination offers better prospects for capturing higher profits from customers. The work concludes by presenting the concepts of affiliation-based discrimination, symmetric and asymmetric quality adjustments.
The use of differential pricing for self-selection
The purpose of differential pricing, from the perspective of the producer of information, is to maximize revenues and profits or to reduce losses. It also enables the process of customer self-selection. The risk of differential pricing is that it could lower the willingness of individuals, who otherwise could pay a higher price. From the customer's point of view, the attractiveness of differential pricing is the potential that he or she does not have to pay for a service that he or she does not value or use. However, customers also face a possible risk of paying higher prices for goods, in the event that differential pricing eliminates a whole category of low- or high-end customers. It seems reasonable to suggest that differential pricing has to be implemented with a clear focus of the gains and the losses that it creates. The next paragraphs analyze the first-, second-, and third-degree price discrimination approaches and the attempt to show how these existing ideas could be extended.
First-degree price discrimination
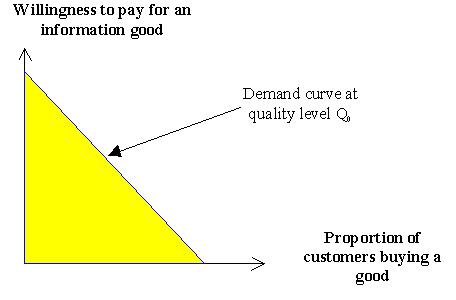
The ideal case of differential pricing would be the situation in which one can concurrently maximize the economic gains of information producers and that of the consumers. This case is presented in Figure 1 and is called first-degree price discrimination [ 5]. Under this condition the producer is able to charge different prices to each customer based on their willingness to pay. This pattern of pricing permits a producer to extract the entire surplus from a market. This outcome provides the best outcome for all customers and also the producer. It is called a Pareto efficient outcome, since the producer's profit can not be improved without harm to customers and the benefits to consumers cannot be increased without decreasing the gains of the producer. Unfortunately, producers cannot use perfect pricing discrimination in most markets. First, when there is perfect competition other competitors could force different pricing policies on the market. Second, the availability of different prices within the market for the same information products could induce some individuals to buy products at a low price and sell them at a higher price. Third, the proportion of customers willing to pay below marginal price for a good might greatly exceed those willing to pay prices higher than the marginal costs of making the good available.
Figure 1: Perfect price discrimination
In light of these concerns, the producer of information goods would have a strong incentive to create a new pricing policy that guarantees profits. Such a policy has to prevent of high-end customers from buying low-end products. This implies that a producer must justify differences in prices based on something that is correlated to customer's willingness to pay [ 6]. The concept of second-degree price discrimination (Pigou, 1920) provides producers with one method of achieving this goal.
Second-degree discrimination: Quantity-based approach
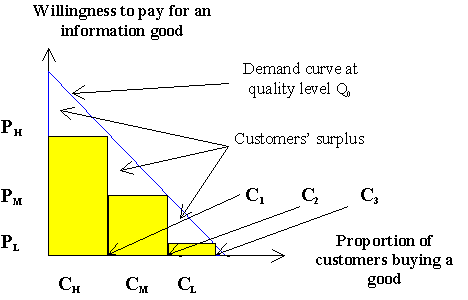
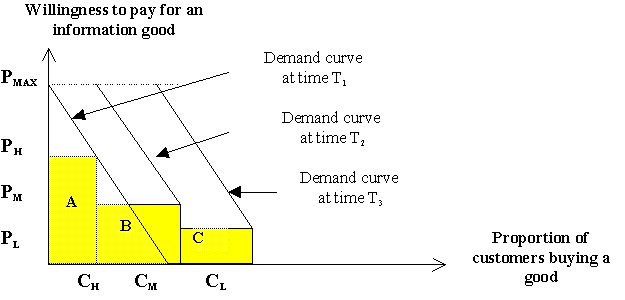
Traditionally, if a producer applies the second-degree price discrimination she or he will attach different prices to specific quantities of an information good. Everyone that buys the same quantity of an information good will pay the same price. Figure 2 presents a graphical representation of second-degree discrimination. The graph assumes that we have a situation in which a producer uses flat pricing (Pn) combined with fixed quantities (qn). In the graph, the first one-third of all customers (CH) buys the same quantity of an information good (q1) and therefore pays the same price (PH). The next one-third of all customers (CM) buys the same quantity of the information good (q2), but less than the first category and pay PM. The last one-third of all customers (CL) buys less quantity than the first two categories (q3) so they pay less than the previous customer classes. One can state the following: (q3 < q2 < q1) and (P3 < P2 < P1).
Figure 2: Second-degree price discrimination
Figure 2 shows the consequences of this kind of discrimination approach. In each customer category the producer is unable to capture all the profits. The triangular areas represent the uncaptured customers' surplus for each customer class, that is the amount the customer is willing to pay but he or she does not have to pay. The price that the producer charges for each quantity of the information good (set or number) is set based on the customers with the lowest willingness to pay per category, i.e. what customers C1, C2, C3, are willing to pay, that is PH, PM, PL. The uncaptured customer surplus is the price that the producer pays for avoiding the perfect price discrimination.
The advantage of second-degree quantity-based discrimination is that it can be used in cases where an indicator of a customer's willingness to pay is inaccessible to the producer. It also gives the producer the opportunity to set market prices that exceed the marginal costs of providing an information good. However, it might be unfair to compare this pricing policy to the perfect pricing discrimination case. When a producer chooses to pursue a perfect price discrimination policy, as discussed earlier, the business might collapse within a short time. However, one could compare this approach to the situation in which there is no price discrimination. Without a price discrimination policy, one could imagine a scenario in which low-end customers are not served or are not able to afford an information good [ 7]. Second-degree price discrimination could also be achieved when a producer intentionally alters the quality of an information good. This has been labeled quality discrimination or versioning by Varian (1997). However, Varian does not distinguish between features- and performance-based quality discrimination. In the next section both of these types of second-degree price discrimination will be compared.
Second-degree discrimination: Features-based approach
Many software organizations use the features-based approach to enhance their price discrimination policies. This is achieved by the deactivation of several functions of a software product that is being sold to a special category of customers, who are unwilling to pay to full price of the complete version of the product. Generally, these products with "reduced quality" offer users less features than the complete version. Similarly, some newspapers and other providers of online information allow "visitors" to preview only portions of the information that is available in their databases. This is achieved by restricting the number of features made available to the visitors. In other instances the features-based approach is realized by denying low-end customers access to special sections online that are password-protected. Other ways of limiting the features of an information good include restricting the size of information that could be processed or stored and by setting expiration periods for specific features. Producers also restrict the number of installations that could be achieved from a given product and limit the number of concurrent users that can use a product.
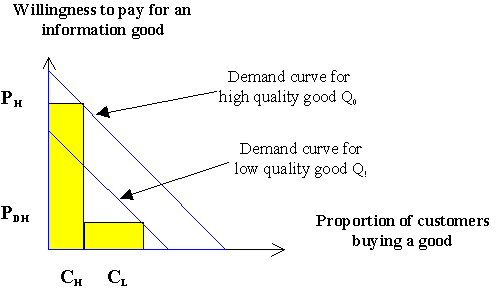
Figure 3 below presents the features-based price discrimination within a demand curve. One of the essential characteristics of the features-based quality discrimination is that it is unlikely to change the essential demand pattern for the full-featured version of a particular information good. Such policies are effective in attracting low-end customers to the reduced quality product. However, the approach is less effective in attracting individuals with a zero valuation for an information good. In the case represented in Figure 3, the producer has one price (PH) for its product and another price (PDH) for a version of the product with reduced or deactivated features.
Figure 3: Features-based price discrimination
The strength of this approach is that it allows the producer to get some value from customers who have a low valuation of the product, without hindering high-end customers from buying the full-version product. As depicted in the graph, the losses that the producer endures might be higher than in the previous quantity-based differentiation case ( Figure 2). The graph shows two lines representing the willingness of customers to pay for the two versions of the information good. Due to the deactivated features of the low-end copy of the product, the graph shows a drop in the willingness to pay for both high-end and low-end customers. The graph, for simplicity reasons, shows a proportional drop in willingness for all classes of customers. The vital characteristic of the graph is the fact that features-based quality modifications do not necessarily change the fundamental "willingness to pay" pattern of high-end customers interested in an information good. When features of a specific information product are partly deactivated, one could expect that the willingness of customers to pay for the degraded information good would be less than that of the complete good. Furthermore, while it is probable that some low-end customers may buy the low quality product, it is unlikely that individuals that are not interested in the information good would pay for the low quality one.
Second-degree discrimination: Performance-based approach
An organization could also use a performance-based approach to achieve quality-based discrimination. Performance is a distinct dimension that could be used to achieve quality discrimination, especially if it correlates with the customer's willingness to pay for an information good. Performance-based differentiation occurs when a producer does not reduce the features of information products, rather he or she alters the level of quality of performance of features. One could imagine a software product that serves the purpose of creating compressed electronic files. For this kind of software, the producer of the information good could manufacture two product models. The first with the capability to achieve 85% compression level while the low-end product achieves only a 50% compression ratio. This would be an example of performance-based quality discrimination. Furthermore, one could imagine information products that have been designed for scanning information or for viewing information. These kinds of information products could offer users different levels of performance relative to scanning quality or the speed at which information could be scanned. Also, a manufacturer could create two information products with different degrees of sensitivity to audio signals. These are just a few examples of performance-based discrimination. Digital music and digital images could be produced in different quality levels, which therefore limits the performance they could provide for the end-user.
Many of the examples listed thus far describe performance-based discrimination for software products. However, one could also identify possibilities for performance differentiation in electronic data. With respect to data, the performance level has to be defined in a meaningful manner. One dimension of the performance level of data is the degree of "direct or immediate usefulness" of information. Consider the situation in which a stockbroker needs to decide if to keep or sell thousands of shares. A high performance data would be the set of information that presents the decision-maker the most recent historical trend of all sell and buy activities of the shares. A lower grade information source would be data that aggregates all the activities of the industry of interest without the specific focus on the individual shares.
These examples are far from being exhaustive, but they do convey some ways in which an organization could use performance to discriminate between information goods. Figure 4 below presents the effect of using this discrimination approach. Unlike features-based discrimination, performance-based discrimination often has the potential to produce new willingness patterns for information goods and it also has the potential to attract new customers. This implies that performance-based differentiation, when used effectively, could be used to capture higher profits than features-based differentiation. One distinct peculiarity of performance-based discrimination is that it could generate new kind of customers if it is used to create customization.
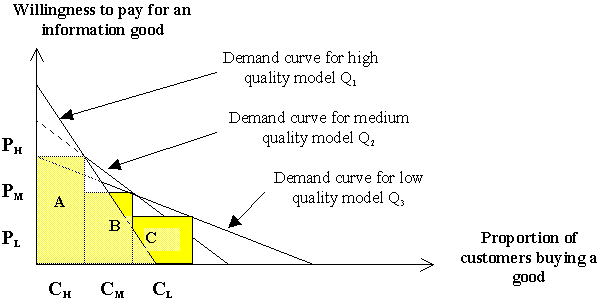
Figure 4: Performance-based discrimination
Performance-based discrimination permits information providers to keep the same features for all versions of a product while customizing (through the reduction of quality) the performance of an information good for targeted categories of customers. For example, information products could be targeted to the needs of professionals, hobbyists and amateurs. In Figure 4 the demand curves show three levels of performance quality. The customers represented by area "A" value the highest quality information good the most and pay a premium for it. These high-end customers are generally professionals. The area B represents customers who buy the medium quality product. The performance of the product was modified in a manner that permitted the producer to charge a lower price than would have been possible for version "A" of the good. In other words, the producer was able to reduce performances to the level that this group of customers (CM) would be willing to pay for and include those features that they valued and were willing to pay for. The same thing was done for customers represented by the "C" area. Using the performance-based approach, the information producer was able to extract a higher surplus than would have been possible using solely the features-based discrimination approach. When an information producer differentiates products based on their performance, it is vital for him or her to ensure the compatibility and upgrade-ability of these products (openness). The avoidance of openness could lower profits.
For example, Microsoft at one point in its history produced three different systems software for different groups of customers, namely the businesses, professional user, and the household users. The problem was that "Windows Me" systems software, aimed at household users, was neither reverse compatible to previous systems from Microsoft nor forward compatible to two higher quality systems from the same firm. The lack of compatibility caused severe installation problems for customers who sought to upgrade their systems. For this reason, an information producer should not create products with limited compatibility to other products just for the sake of capturing higher surplus from customers by "locking them in".
Second-degree discrimination: Time-based approach
Time is a criterion that is generally useful and meaningful for achieving product-price discriminations. This is especially true for information products that have long product life cycles or product life spans. For example, because newspapers have such a short life cycle, it would be a challenging proposition to use time-based approach for differential pricing in the industry. However, books or films are a different kind of information product because they have a longer life span than newspapers. The longer life spans of these information products makes the use of time-based pricing applicable. Based on the time-based approach, a theater charges a higher fee for new films than for older ones. Furthermore, videos are also made available for purchase and renting based on this concept. Book publishers also exploit this phenomenon. Generally, higher priced hard-copy versions of books are marketed before lower priced paperbacks. The Boston Globe found a limited way of exploiting time-based discrimination to exploit more profits from customers for its newspapers. The Globe releases an early edition of its Sunday paper with the Saturday edition. To some readers, there is a distinct advantage in examining classified ads slightly ahead of the majority of the Globe's customers. This approach is also being used in the cable industry effectively. A customer who watches a live transmission of a boxing event pays a premium to do so, while those who wait before watching the same event pay much less to do so. In all these cases the performance of the information good provider is constant, the only basis of differentiation is the timing of delivery of a given good. Figure 5 presents a simplified way of understanding the time-based discrimination approach. It is a simplified presentation because it is assumed that each customer benefits once from a given information good.
Figure 5: Time-based price discrimination
This is idealistic because, as we all know, an individual that sees a movie on its opening night still go back and see the same movie again days later. Furthermore, the graph depicts a scenario in which the demand curve or willingness to pay for an information good remains constant over time. This is also a simplification, especially for subjective information products such as movies. It is to be expected that the demand curve of some people would change as soon as they hear positive or negative comments about a product, like a movie.
As depicted in the graph, there is a maximum price for an information good. This price remains constant throughout the whole period, in most cases. Exceptions to this rule are time-based products that do not involve any kind of re-packaging. For example, a producer may charge a higher fee during the first two weeks of a teaching video product and be forced to reduce the fee with time. If the same information product were packaged differently as a DVD, audiocassette and digital video, all three versions could be offered consecutively or simultaneously at different prices over time. One characteristic of the time-based approach is that it permits an information provider the opportunity to find the best price for a specific information product, provided that the influence of competitive forces on price levels are minimal. This method could also be used to steer buying activities to specific phases of the life cycle of a product. The potential of this approach to capture customer surpluses depends on two primary factors. First, the life spans of information goods are important. Products with longer life spans would more likely generate more revenues over time than those with short life spans. Second, information products that could be packaged in multiple ways would capture more profit over time than those that cannot benefit from such packaging. However, these characteristics do not displace each other but are complementary. For example, while repackaging would enhance the profitability of movies, which generally have longer life spans, the repackaging of newspaper features might not extend the life span of the articles.
Third-degree price discrimination: Affiliation-based discrimination
This approach of differential pricing has been the focus of several economic researchers (Schmalensee, 1981; Varian, 1981; Schwartz, 1990). In the field of economics, third-degree pricing was defined primarily in terms of socio-economic or affinity-based pricing. When third-degree price discrimination is implemented, selected groups with a lower willingness to pay, e.g. senior citizens, students, veterans and others, are selected for special discounts. This kind of price discrimination is valid, but it is often implemented as a voluntary gesture. While one could argue that it is profitable for the society as a whole to have such practices, it might be difficult to prove that it will maximize profits or efficiency for all the firms that implement it. A more interesting approach is the affiliation-based third-degree price discrimination. It is an important type of third-degree price discrimination because it is presently widespread. Examples of this price discrimination approach include, frequent flyer discounts, automobile club discounts, travel club rebates and so on. Most of these systems have a common characteristic - an individual joins a club and pays an annual membership fee. Membership entitles individuals to 5-25% discounts at participating organizations and/or for selected products. The interesting trait of affiliation-based discrimination is that it is not based on the willingness to pay, rather on the willingness of individuals to pay less or save on every possible good. This kind of price discrimination works best in contexts in which capacity and time are inextricably connected, e.g. for the services industry. If a provider of information goods plans to implement the approach effectively, he or she must find a way to use the policies for low-end customers rather than for high-end customers. Such polices would also make sense when it is used for off-peak periods rather than high-peak ones. When used effectively, affiliation-based discrimination can help an organization capture profits from customers in areas where an organization contends with losses.
Setting pricing strategies for individual information goods
Based on the preceding sections, one could conclude that time-, performance- and features-based discrimination are the most valuable means of price discrimination for information goods. While each of these could be used to capture surplus from existing customers, the performance-based approach could be much more effective if it is customized for each class of customers for which it is designed. The features-based approach of deactivating selected features of a complete version is generally less costly to achieve or realize than the performance-based versions. However, degraded versions of information products may not attract as many customers as the performance-based customization would do. For time-sensitive information goods, the time-based price discrimination could be used only within specific time windows. The span of these windows is determined by specific constraints, e.g. duration of live events, seminars and meetings. Information products that are less time-sensitive can exploit the time-based price discrimination approach to maximize profits over time as well as capture profit from both new and repeat customers.
Strategies for capturing incremental surplus from customers: Setting flat prices
Generally, in the field of economics, most economic analysis about price and revenue is based on the premise of profit maximization (Adams and Yellen, 1976). Recent contributions in the area of information goods also emphasize this approach (Varian, 2000; Bakos and Brynjolfsson, 2000b).
Figure 6: Capturing surplus from clients
The question of maximizing profit is not the topic of this section. Instead I will attempt to use graphical analysis to show how producers could capture incremental surplus from their customers. This is not the first time a graphical approach has been used to analyze economic phenomenon. However, most contributions involving this approach analyze the bundling of goods (Adams and Yellen, 1976; McAfee, McMillan and Whinston, 1989). The graphical approach to be used here extends that of Varian (1997). I will attempt to use graphs to illustrate some of the ways that producers could discriminate goods and hence encourage better self-selection of customers. Though, this may not always lead to profit maximization, it does reveal alternate strategies that producers of information goods could use to incrementally capture more value or profit from customers.
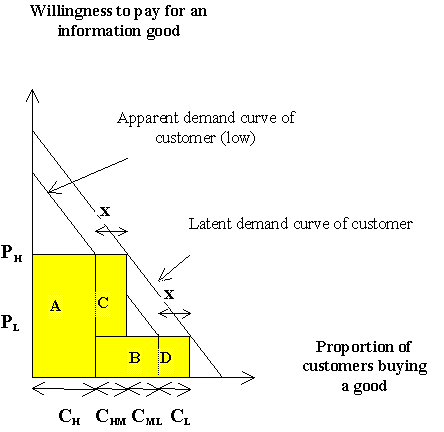
Figure 7: Surplus capture and latent demand
As shown earlier in this paper, the price that is charged each group of customers is the price that those customers with the lowest willingness to pay would pay. This means that a producer would not be able to capture all the profits that each customer offers the market. Figure 6 shows a simple diagram of the profits of an information producer. The producer operates on the basis of two flat prices, PH and PL. Generally, it is assumed in the literature that every customer has one demand curve (in this case a linear curve). This paradigm of thinking works fine as long as one is sure that the customer actually has a single demand curve. However, I propose in this paper that customers may have two or more demand curves. I analyze this possibility by postulating that there is another demand curve that I call the latent demand curve. This latent demand curve describes the willingness of a customer to pay fair price instead of a cheap price for an information good. Figure 7 shows the situation in which a producer is able to win just a handful of the (high-end) customers (CHM) from the low willingness group to pay the latent price that they consider to be fair. This is represented by area "C" in the graph. The low-end customers have also been enticed to pay the latent price - PL (with profits represented by area "D") than the lowest price which was zero. This price is higher than the apparent price expectations of members of the low-end customer group. The calculations below show that this increases the surplus that the producer captures.
Profits captured through latent price orientated pricing:
= A + B + C + D
= CH * PH + (CHL + CML) * PL + CHM * (PH - PL) + (CL * PL)
= CH * PH + CM * PL + CHM * (PH - PL) + (CL * PL)
But CH * PH + (CL * PL) - which represents the areas A' + B', in Figure 6. This was the profit that was captured when the apparent demand curve was used for pricing. The profits captured when pricing is based on the latent demand curve are higher that that from apparent demand curve by: CHM * (PH - PL) + (CL * PL).This means that a producer would capture more profits using the latent demand than if she or he were to the focus on the apparent demand curve. The impact of the latent demand curve on the profitability of a producer would be more significant, the larger the difference (x) between the apparent demand and the latent demand curves. The profits are also larger the higher the price (PH) being charged for the high-end information goods. I conclude based on this analysis that producers stand to gain more incremental profits if they are able to extract, not the apparent demand price, but the latent price that customers consider being fair price. This strategy is helpful when a producer sets flat prices for information goods.
Strategies for capturing incremental surplus: Symmetric and asymmetric quality adjustment
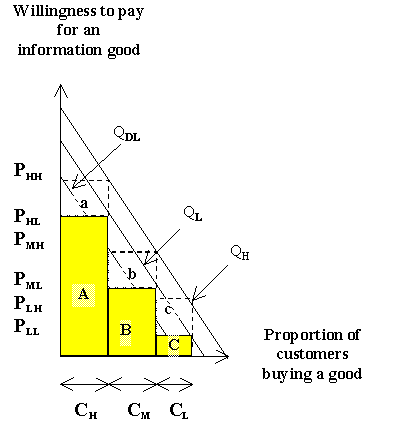
Varian (1997) indicated that the seller of goods can increase their profits and the price they charge to high-end customers by reducing the quality available to low-end customers. I will expand on this concept by introducing lines that represent quality in the graphs to be used. The quality lines in Figure 8 and Figure 9 represent quality levels for all information products that an organization offers. For example the dotted lines represent the high-quality information products offered to customers in each segment. The quality lines represent the highest quality (QH) in each segment, the lowest quality (QL) in each segment and the lowest quality reduction (QDL) permitted within each segment. One advantage of the graphical approach is its simplicity and intuitiveness. It also shows that quality reduction strategy is not only possible in the low-end area as suggested by Varian (1997). Theoretically, quality reductions could occur in each customer segment. While the argument could be made that the greatest quality difference occurs by increasing the quality of the high-end product and reducing the quality of low-end products, this option is by no means the only possibility, especially for those organizations with three or more products spread out over multiple customer segments.
Figure 8: Capturing surplus through symmetric quality-based discrimination
Figure 8 could be used to explore strategic options of a firm which has at least one information product in each segment. First, such a firm could position all its products on the low quality end of each segment. This would lead to a value capture represented by areas A, B and C. Second, the producer also has the option of offering top-quality product in all three segments. The surplus capture in this case increases to the sum of the areas A, a, B, b, C and c. Third, the final option that a producer has would be a mixed strategy. In this case she or he would offer in each segment, whatever quality is likely to generate the highest profits.
It is relevant to note that the quality lines in Figure 8 are parallel and are equidistant from each other. This is why I call it the symmetric quality-based discrimination approach. This approach would be relevant in situations in which the qualities of information products are defined in a coherent way in each customer segment. For example, three classes of checking accounts could be differentiated based on the level of interests paid by a banking institution and the periodic charges that customers pay for the account (see Table 1). The Table suggests that customers would self-select themselves into three groups. Within each customer segment, the bank could further discriminate between low, medium and high-end categories. Strategies that are similar to these could be developed for information products such as cable TV information, electronic information and other forms of information.
Premium Account Golden Account Standard Account Interest High (5%) to Low (4%) High (4%) to Low (3%) High (3%) to Low (2%) Annual charges High ($120) to Low ($80) High ($80) to Low ($40) High ($40) to Low ($0) Table 1: Discriminating bank accounts using the symmetric quality approach
The symmetric quality-based approach would be common in cases in which product discrimination could be achieved in each customer segment either at no cost or very cheaply. This is an important condition because one could expect that high-end customers would be willing to pay a higher price for quality enhancements than customers at the low-end would be willing to pay.
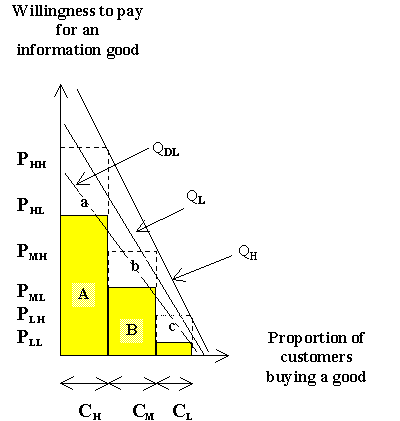
Figure 9: Capturing surplus through asymmetric quality-based discrimination
One would therefore expect that strategies based on the symmetric quality-based discrimination would be effective the more the producer is able achieve such differences using targeted policies. Whenever a producer has to invest extra costs to implement quality reductions, asymmetrical quality-based differentiation would be more appropriate.
Figure 9 shows a graph of the asymmetric quality-adjustment case. The central difference between the two approaches is the fact that the distance between the quality lines is no longer constant. The central advantage of this approach is that a producer can invest more money in quality enhancements for the high-end customer than for the low-end customer. This approach makes sense on three counts. First, customers at the high-end are generally more likely to pay a higher price for better quality goods. Second, the producer creates a situation where the differences between the high- and low-end goods are more perceptible. Third, the producer is more likely to offer profitable products in each segment since it can appropriately charge a higher price in segments where a lot more money was invested for quality enhancements. Table 2 shows an example of asymmetric quality-based discrimination for information goods. Both price and quality differences for the options reveal asymmetric tendencies. The Table shows three different information products which offer customers different levels of quality. The costs and restrictions were used to reinforce the symmetric conditions that were created by the design of varying levels of server software complexity.
Professional Web Server (Windows NT Server) Small Group Server (Windows NT Workstation) Single User Web Server (Personal Web Server Software) Cost $700-$1000 $250 Free (downloadable) Number of users Unlimited 10 1 Table 2: Discriminating Web server accounts using the asymmetric quality approach
Summary
This paper attempted to show how current practices of information product discrimination could be developed into certain fundamental concepts. The author formulated the features-, performance- and time-based discrimination approaches and provided examples of their applicability for information products. The comparisons of these concepts suggest that performance-based discrimination methods, over time, are more effective at gaining market share and increasing producer profits. The paper also explores the quality-adjustment practices of information producers and explores the differentiation between symmetric and asymmetric approaches of adjusting product quality. The analysis suggests that asymmetric quality adjustments are more perceptible than the symmetric quality adjustment methods.
About the Author
A. Dedeke is in the Department of Computer Information Systems at the Sawyer School of Management at Suffolk University in Boston, Mass.
E-mail: ndedeke@suffolk.edu
Notes
1. For the sake of clarity, this paper differentiates information goods from information services. Information goods are defined as entities that have been physically or technologically captured on an information platform or medium and are therefore easily priced, packaged and transported.
3. See Bakos and Brynjolfsson, 2000a.
References
W.J. Adams and J.L. Yellen, 1976. "Commodity bundling and the burden of monopoly," Quarterly Journal of Economics, volume 90, number 3, pp. 475-498.
Y. Bakos and E. Brynjolfsson, 2000a. "Bundling and competition on the internet," Marketing Science, volume 19, number 1 (Winter), pp. 63-82.J.Y. Bakos and E. Brynjolfsson, 2000b. "Aggregation and disaggregation of information goods: implications for bundling, site licensing and subscriptions," In: D. Hurley, B. Kahin, and H. Varian (editors). Internet Publishing and beyond: The economics of digital information and intellectual property. Cambridge, Mass.: MIT Press.
R.P. McAfee, J. McMillan and M.D. Whinston, 1989. "Multiproduct monopoly, commodity bundling, and correlation of values," Quarterly Journal of Economics, volume 104, number 2, pp. 371-383.
A. C. Pigou, 1920. The Economics of welfare. London: Macmillan.
R. Schmalensee, 1981. "Output and welfare implications of monopolistic third-degree price discrimination," American Economic Review, volume 71, pp. 242-247.
M. Schwartz, 1990. "Third-degree price discrimination and output: Generalizing a welfare result," American Economic Review, volume 80, pp. 1259-1262.
H.R. Varian, 2000. "Buying, sharing, and renting information goods," Working Paper, School of Information Management and Systems, University of California, Berkeley, at http://www.sims.berkeley.edu/~hal/people/hal/papers.html, accessed 3 March 2002.
H.R. Varian, 1997. "Versioning information goods," Paper at Digital Information and Intellectual Property Conference, at Harvard University (23-25 January).
H.R. Varian, 1996. "Differential pricing and efficiency," First Monday, volume 1, number 2 (August), at http://firstmonday.org/issues/issue2/different/index.html, accessed 3 March 2002.
H.R. Varian, 1995. "Pricing information goods," Research Libraries Group Symposium on Scholarship in the New Information Environment, at Harvard Law School (2-3 May).
H.R. Varian, 1985. "Price discrimination and social welfare," American Economic Review, volume 75, pp. 870-875.
Editorial history
Paper received 29 January 2002; accepted 26 February 2002.


Copyright ©2002, First Monday
Self-Selection Strategies for Information Goods by A. Dedeke
First Monday, volume 7, number 3 (March 2002),
URL: http://firstmonday.org/issues/issue7_3/dedeke/index.html