Server performance has become a crucial issue for improving the overall performance of the World-Wide Web. This paper describes WebMonitor, a tool for evaluating and understanding server performance, and presents new results for realistic workloads.
WebMonitor measures activity and resource consumption, both within the kernel and in HTTP processes running in user space. WebMonitor is implemented using an efficient combination of sampling and event-driven techniques that exhibit low overhead. Our initial implementation is for the Apache World-Wide Web server running on the Linux operating system. We demonstrate the utility of WebMonitor by measuring and understanding the performance of a Pentium-based PC acting as a dedicated WWW server. Our workloads use file size distributions with a heavy tail. This captures the fact that Web servers must concurrently handle some requests for large audio and video files, and a large number of requests for small documents, containing text or images.
Our results show that in a Web server saturated by client requests, up to 90% of the time spent handling HTTP requests is spent in the kernel. These results emphasize the important role of operating system implementation in determining Web server performance. It also suggests the need for new operating system implementations that are designed to perform well when running on Web servers.
Contents
- Introduction
- Web Server Performance
- Experimental Environment
- Design of WebMonitor
- Results
- Concluding Remarks
- References
Introduction
With corporate Web sites getting millions of hits per day, performance of Web servers is becoming a critical issue. Web servers that do not respond quickly under heavy loads can slow down network connections, deny service for visitors and cause network failures. In order to improve Web server performance, we need to understand how server behavior differs in response to different type of requests, such as requests for small HTML documents, or for large audio and video files. We need to gain insight into server behavior under heavy load in the presence of such heterogeneous workload. In particular, we need to assess the impact of operating system implementation on server performance. This suggests the need for quantitative measurements that show how system resources are being utilized when servicing HTTP requests.
Despite the importance of measuring and understanding the behavior of Web servers, there are no freely available performance tools that give detailed information about server behavior. In this paper, we describe WebMonitor, a prototype tool for measuring and understanding server behavior. For an HTTP workload, WebMonitor measures activity and resource consumption, both within the kernel and in HTTP processes running in user space. It is implemented using an efficient combination of sampling and event-driven techniques that have low overhead (less than 4%), and therefore does not significantly perturb server behavior. Our initial implementation is for the Apache WWW server running on the Linux operating system.
We demonstrate the utility of WebMonitor by measuring and understanding the performance of a Pentium-based PC acting as a dedicated WWW server. We present results for a workload generated by WebStone [13], which is a configurable tool for benchmarking Web servers, available from Silicon Graphics. We parameterized the server workload generated by WebStone to capture the heterogeneous nature of HTTP requests, using values from [4]. Specifically, we used file size distributions with a heavy tail to capture the fact that Web servers must concurrently handle some requests for huge multimedia files and a large number of requests for small HTML and image documents. Such distributions occur in the size of files requested at servers, and in files requested by clients [4, 5]. This heterogeneity in workload stresses the limits of the underlying operating system much further than traditional applications [12]. One other important characteristic of our workload (and experiments) is that we do not reuse TCP connections for multiple HTTP requests, as described in [8] and the Apache documentation [11]. Thus, we open a new TCP connection for every request. We therefore capture the costs of servicing our workload under the ``worst case'' assumption of being unable to use persistent connections. The data collected by WebMonitor show that, in a Web server saturated by client requests, up to 90% of the time spent handling HTTP requests in spent in the kernel. These results emphasize the important role of operating system implementation in determining Web server performance.
The rest of the paper is organized as follows. Section 2 discusses the main characteristics of the Web that influence server performance and how this performance can be measured. The experimental environment we instrumented and measured and the workload we used to drive our experiments are described in section 3. In section 4, we present an overview of WebMonitor, the tool we implemented to measure and understand server behavior. Next, we use WebMonitor to measure the behavior of a busy Web server. The main results are presented in section 5. Finally, concluding remarks appear in section 6.
Web Server Performance
Web server performance can be analyzed from different viewpoints. For instance, a Web user's perception of performance has to do with fast response time and no connections refused. On the other hand, a Webmaster's perception of performance is oriented towards high connection throughput and high availability. Researchers are usually interested in identifying bottlenecks, i.e., saturated components of the system that limit performance of Web servers. What is common to all perceptions of performance is the need for quantitative measurements that describe the behavior of a WWW server.
Web server performance depends upon several factors: hardware platform, operating system, server software, network bandwidth and workload. There are various well-known methodologies for performance evaluation of computer systems, as pointed out in [7]. However, the WWW has some unique characteristics that distinguish it from traditional distributed systems [3, 4, 5, 9, 10]. Some of these characteristics have a profound impact on the performance of Web servers. First, the number of WWW clients is in the tens of millions and rising. The randomness associated with the way users visit pages makes the problem of workload forecasting and capacity planning difficult. The Web is also characterized by a large diversity of components; different browsers and servers running on a variety of platforms, with different capabilities. The variety of components complicates the problem of monitoring and collecting performance data. Finally, WWW users may experience long, variable, unpredictable network delays, that depend on the connection bandwidth and the network congestion.
It is fundamental in evaluating the performance of Web servers to have a solid understanding of WWW workloads. Web workload is also unique in its characteristics. Recent studies [4, ] have shown that file size distributions in the WWW exhibit a heavy-tail. This property holds for files requested by users, files transmitted across the network and files stored on servers. The document types accessed in the servers fall into six basic categories [5]: HTML, images (e.g., gif), sound (e.g., au and wav), video (e.g., mpeg) dynamic (e.g, cgi), and formatted (e.g., ps, dvi). It has been shown that file sizes vary in the range of
to
and that the tail weight of the distribution is increased by audio and video files.
Nearly all HTTP server implementations use a new TCP connection for almost every request. Workload studies [4] report that over 90% of client requests are for small HTML or image documents. The combination of these two facts explains a common phenomenon that has been noted during the operation of busy servers: the creation of a large number of short-lived processes [9, 10]. Short-lived processes represent new problems for performance monitoring, for operating systems do not provide facilities with enough accuracy to measure this type of processes.
Metrics
Latency and throughput at the server are the two most important performance metrics that WebMonitor measures. The rate at which HTTP requests are serviced represents the connection throughput. However, because the size of objects varies significantly, throughput is also measured in terms of bits (or bytes) per second. The time required to complete a request is the latency at the server, which is one component of client response time. time, also called latency. The average latency at the server is the average execution time for handling the requests. However, client response time also includes time spent communicating over the network, and processing on the client machine (e.g., formatting the response). Thus, client-perceived performance depends on the server capacity, the network load and bandwidth, as well as on the client machine. Finally, increased errors per second are an indication of degrading performance. An error is any failure in attempting an interaction with the server. For example, an overflow on the pending connections queue at the server is an error. This means that an attempt by a client to connect to the server will be ignored. As a consequence, the client will retransmit the connection request until there is available space in the queue or a predefined period of time expires. Thus, the most common measurements of Web server performance are:
- Connections/second
- Bytes/second
- Response time
- Errors/second
There are tools and resources to monitor Web servers and collect performance data at many levels. Measurement data that are commonly provided by current monitors can be grouped into two catagories [7]: system-level and server-level.
System-level monitors show system-wide resource usage statistics, such as CPU, memory and disk utilization. For example, the system-level behavior of a Web server can be monitored by operating system tools, such as UNIX/sar or NT/Performance Monitor.
Server-level statistics can be obtained from log files. Web servers can be configured to record information about all requests handled by the server. The logs have one line of information per request processed by the server. Each line contains the name of the host making the request, the timestamp the request was made, the filename of the requested object and size in bytes of the reply. Access logs are an important source of information for characterizing server workload. For example, in [4], the authors propose a characterization based on the document type distribution, the document size distribution, the document reference behavior, and the geographic distribution of server requests. Although useful for workload characterization purposes, Web server logs do not provide performance information, such as the elapsed time required for handling a request and resource usage required to process a request.
Despite the importance of measuring and understanding the behavior of Web servers, there are no freely available performance tools capable of pinpointing where time is spent in the processing of HTTP requests. This motivated us to design and develop WebMonitor, a tool that provides insight into the operation of a Web server.
Experimental Environment
This section describes the environment in which we carried out our Web server performance evaluation. We explain in detail not only the server architecture, but also the workload used to perform the measurements.
Our server platform is an Intel Pentium 75 MHz with 16 Megabytes of main memory and 0.5 Gigabyte disk. It has a standard 10 Megabit/second Ethernet card. Unix, Windows NT and Netware have all been used as Internet server operating systems. Each of them has advantages and disadvantages concerning relevant features such as high-end scalability, multimedia tools, fast file systems, management tools and security schemes. We chose Linux version 2.0.0, a Unix-like system distributed under the terms of GNU General Public License that runs on the Intel platform [14]. The server software is Apache [11], version 1.1.1, a public domain (and the most popular) HTTP server [6].
The Apache project has been organized in an attempt to answer some of the concerns regarding active development of a public domain HTTP server for UNIX. The goal of this project is to provide a secure, efficient and extensible server which provides HTTP services in synchronization with the current HTTP standards. Its was originally based on code and ideas found in NCSA HTTP server. It is ``A PAtCHy server'', since it was based on some existing code and a series of ``patch files'' or optional modules, that are compiled and linked to the main code. These modules implement the handling of most commands such as cgi scripts, proxy server support, authentication and access checking.
Apache can run from the inetd system daemon or in standalone mode. When running from inetd, a new copy of the server is started from scratch for each connection made to the server. Thus, there is high overhead per-connection. Therefore, in our experiments, we run Apache in standalone mode which exhibits much lower overhead.
In standalone mode, the server is started only after a pool of HTTP processes are spawned and waiting to service incoming requests. On startup, a predefined number of HTTP processes are spawned. Once running, the server increases or decreases this number depending on its load. A master process manages this pool of processes by periodically checking the number of idle child processes and dynamically adjusting this number to the current load. In the case of a very high number of idle processes, some of them die off. On the other hand, if there are fewer idle processes than a predefined lower bound, new processes are spawned. Thus, the server maintains a number of spare processes to handle transient load spikes. There is also a limit on the total number of simultaneous requests that can be supported; no more than this number of child server processes will be created. Each HTTP child process has a finite lifetime, limited by the number of requests it can handle. This helps reduce the number of processes when the server load decreases. In our experiments, the lower and upper bounds on the number of idle processes were set to 5 and 10, respectively; and the number of requests a child process serves before dying was set to 30. On startup, 5 child processes were spawned, and the maximum number of simultaneous requests supported was set to 150.
Apache is an HTTP 1.1 compliant Web server, since it can accept more than one HTTP request per connection. However, in our experiments, the number of KeepAlive requests per connection [11] was set to 0 (only one HTTP request was serviced per connection).
Benchmarking has been regarded as a useful approach for analyzing and predicting performance of computer systems. Several benchmarks have been proposed for measuring hardware and software speed, including compilers and operating systems. Instead of developing a benchmark suite to represent a specific Web workload, we decided to use a standard benchmark. The workload of a Web server basically consists of HTTP requests. WebStone [13] is a configurable client-server benchmark for HTTP servers, that uses workload parameters and client processes to generate HTTP traffic that allows a server to be stressed in a number of different ways. It makes a number of HTTP GET requests for specific pages on a Web server and measures the server performance, from a client standpoint.
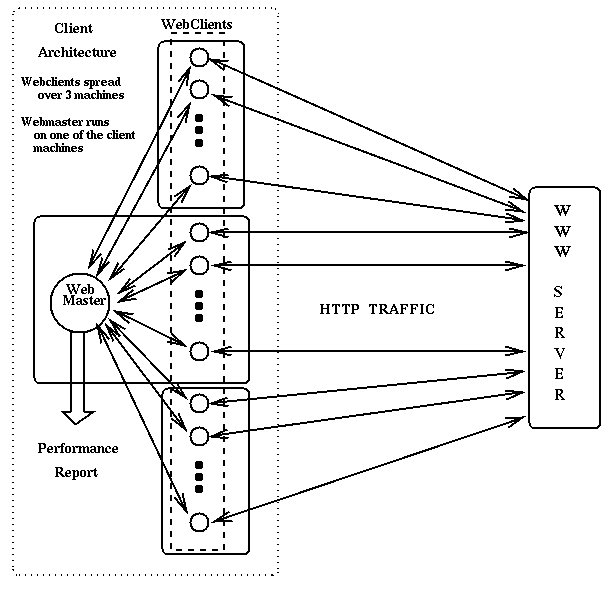
WebStone is a distributed, multi-process benchmark, where a master process (Webmaster) spawns, local or remotely, a predefined number of client processes (Webclients). Each client process generates HTTP traffic to the Web server and collects performance data during a predefined period of time. After all clients finish running, Webmaster gathers the data collected by each client and generates an overall performance report that represents the server behavior during the execution of the workload from the client standpoint. The Webclients and the Webmaster may or not run on the same machine. In our experiments, we spread Webclients over three machines: two SparcStation 20 (one with 128 MB of main memory running SunOS 4.1.4, and the other with 256 MB of main memory running SunOS 5.5) and one SparcStation Ultra (with 128 MB of main memory running SunOS 5.5). Load generation in WebStone is performed by successively requesting pages and files from the server as fast as it can answer the requests. A new request is sent out to the server immediately after a client receives the response from the previous request. If all Webclients are spawned on the same machine, there may be bottleneck at the clients if they can not generate requests at the same rate that the server can handle them. Figure 1 shows an overview the testbed in which we used WebStone as our workload generator.
WebStone clients measure both throughput and latency. The former is measured in bytes transferred per second and connections per second, and the latter represents the average response time to complete a request (viewed by the client). The workload is defined by the number of clients, and by a configuration file that specifies the number of pages, their size and access probabilities. Table 1 gives baseline information for the HTTP workload used in our first set of experiments. The parameters that define the workload are representative of the kinds of workload typically found in busy WWW servers [4]. It is worth noting that the set of files in this workload consumes 82% of physical memory. Furthermore, once the kernel and HTTP processes are also present in memory, we observe significant disk activity in our experiments.
Item Number of files Total File size (KBytes)
Average File size (KBytes)
Total Access Probability
Average Access Probability HTML 24 180 7.5 0.192 0.008 Images 29 385 13.28 0.754 0.026 Sound 20 3580 179 0.05 0.0025 Video 4 9216 2304 0.004 0.001
Table 1: Characteristics of an HTTP Workload
Design of WebMonitor
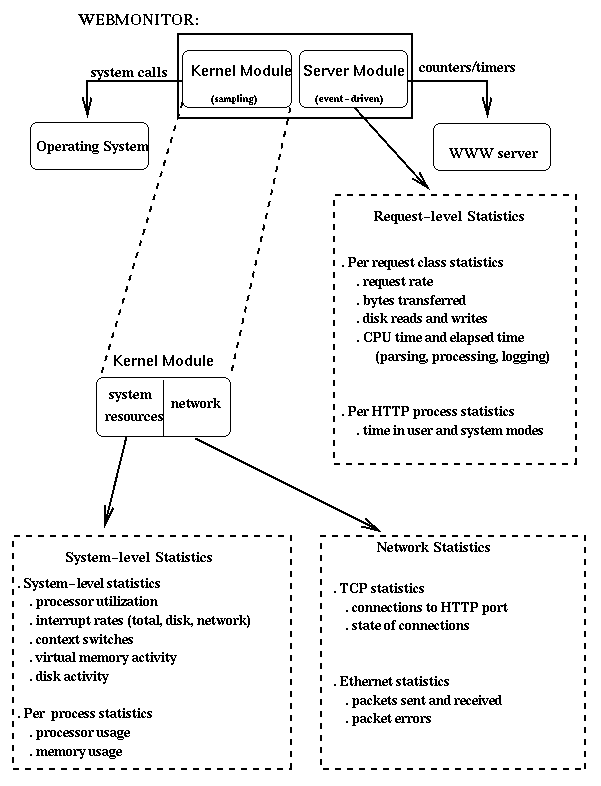
WebMonitor was designed with two main goals: Collecting performance data at different levels to yield a detailed and accurate understanding of server behavior, while keeping the overhead of monitoring the server as low as possible. It is composed of two main modules that differ in the way they interact with the system, the technique of instrumentation used and the nature of the data collected. Performance at the system level is important to understand how Web server operation affects the performance of the system as a whole. Data related to resource utilization at each main component of the system (CPU, memory, network, disk) are collected by Kernel Module, which runs independently of the Web server. The second module, the Server Module, collects useful information about server performance during the handling of HTTP requests. This module runs as part of the server and its code is linked with the server code itself. Figure 2 depicts an overview of WebMonitor.
Performance at the System Level
To understand how the operating system behaves during Web server operation, it is necessary to collect different resource usage data. This information is also useful for analyzing the relationship between server performance and operating system implementation. Processor utilization is one resource to be analyzed. The time the processor is busy is broken down into two components: time spent in user mode and time spent in system mode. These two measures allow one to understand how the system behavior is dependent on the operating system implementation. Disk activity is also very useful in understanding how much idle time is due to waiting for I/O operations, and how effective the disk cache is in avoiding disk transfers. A Web server continuously receives requests for access to many different files. Since many requests can be handled concurrently, the memory consumed by the HTTP processes and the kernel buffers (necessary to handle I/O operations) may be a bottleneck. Paging activity statistics, i.e., the number of pages transferred to and from disk, can be used to determine how memory usage influences system performance. Two other system statistics that imply resource consumption are interrupts and context switches. All of these statistics are collected by the Kernel Module (KM).
Since the operation of a Web server involves networking activity, the analysis of TCP/IP and Ethernet resources are essential for an accurate understanding of server performance. KM collects information related to communication through the Ethernet interface, such as the number of packets transmitted or received and the total number of errors that occurred during transmission or reception. Some specific errors are also collected separately in order to better identify possible bottlenecks: number of collisions and errors due to overflow in TCP/IP queues and buffers. Within TCP, statistics we collect also provide information about the number and state of TCP connections to the HTTP port. This TCP state information is useful for understanding ``lifetime'' of connections in the server.
In addition to the system-wide information gathering described above, KM also obtains information about specified processes (e.g., HTTP processes). The data collected are processor utilization, memory usage (percentage of the total memory available) and number of major page faults that caused pages to be read from disk. KM also counts the total number of copies of each monitored process and the number of copies waiting to run. In our experiments, we monitor not only the HTTP processes but also the kernel processes responsible for swapping (kswapd) and buffer cache management (update). However, since our results show that the vast majority of system resources are consumed by the HTTP processes, we only present results for these processes.
The Linux kernel keeps many of the statistics described above as internal counters, in its own private memory. They can be read by users through the /proc file system [14]. This is a ``virtual file system'' since information is not located in disk but in memory. A read of any file below /proc causes the information in kernel memory to be copied to user memory as a sequence of ASCII characters. Thus, to find specific data, it is necessary to parse a string for a specific keyword and then read one or more numeric value.
There is one important disadvantage to using /proc to gather kernel activity statistics. If one needs to collect information scattered throughout several kernel data structures, one must perform multiple reads (each of which is a system call), or read very large blocks of data out of the kernel. Both of these alternatives are very expensive. For example, data regarding each TCP connection are kept in a virtual file called /proc/net/tcp. To get the number and states of all connections in a specific port, it is necessary to parse the whole file. Since the number of connections during normal operation of the Web server can be very high (in the order of hundreds), to get this information through /proc would cause an unbearable overhead. Furthermore, to obtain information regarding specific processes through /proc would also incur high overhead. There is a directory for each process indexed by its process id. The data we gather for each process are located in a file under its directory. Thus, to collect data about all processes, one must perform at least one read system call for each process running on the machine.
The overhead of reading /proc is the main reason we decided to implement the KM using four system calls. These system calls are each called periodically to implement each of KM's main features. All of these system calls, summarize and return specific information about kernel activity in a single buffer [1]. All information is returned as a cumulative value since the last system boot, however, each buffer contains a field called uptime that records the time since the last boot. Therefore, it is possible to compute rates and percentages from the data returned by these system calls. This processing is done after data collection in our experiments in order to minimize overhead during data collection.
KM runs as a group of two to four processes, periodically collecting information through the system calls described above. The number of samples, the TCP port to be monitored, the number of different programs to be monitored and the name of them are parameters specified in a configuration file. The information collected is divided into four groups depending on the system call to be used: KERNEL_STATS, PROC_STATS, NET_STATS and CONN_STATS. For each group, it is possible to specify if it's enabled (i.e., the information is collected) and the interval of sampling. If both KERNEL_STATS and PROC_STATS are enabled and their intervals of sampling are equal, a unique process is spawned to collect both group of information. If not, one process is spawned for each group. The same is true for the other two groups of information. One log file is created for each group of information [1].
Performance at the Server Level
The Server Module (SM) is responsible for collecting performance data in the Web server. It is based on a trace of events that occur during the handling of HTTP requests. It is implemented as a library of routines compiled and linked with the server code. Calls to these routines were inserted at appropriate points in the server code. Through these calls, each HTTP process accesses internal counters and timers that keep data related to its performance.
The SM measures the number of bytes transmitted and connections established during a period of time. Thus, rates can be easily computed. SM also collects information regarding disk activity per connection: read and write operations, and the number of blocks read and written. Linux only keeps global disk activity statistics. We instrumented the kernel to record disk transfers on a per-process basis [1].
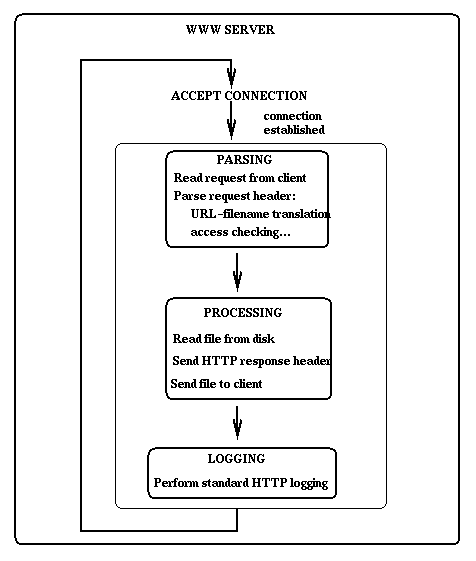
Recall that latency is the time spent at the server handling a request. The time measured by SM begins with the establishment of the connection between client and HTTP process and ends when the HTTP process is ready to handle the next request. SM collects both processor time and elapsed time. The former represents the time the processor was busy and the latter includes both processor and waiting times. We break latency down into three components: parsing, processing and logging, as shown in Figure 3.
Although the response is sent to client before logging begins, the time spent in this phase influences the server performance, since the HTTP process will not be free to accept a new connection until logging finishes. If a new request arrives during this interval, an idle HTTP process will be assigned to handle it or a new process will be spawned, increasing resource consumption.
All Linux timing routines are dependent on the timer interrupt rate. The resolution is on the order of 10 milliseconds [14], which is not accurate enough to account for the three components of execution time of very short requests. Thus, we had to instrument Linux kernel to improve accuracy of the measurement process. A ``stopwatch'' scheme based on the gettimeofday routine was implemented. This routine returns the elapsed seconds and microseconds since a predefined date. A higher resolution is achieved reading the time directly from the hardware timer. Two system calls, Start and Stop, were implemented to manage the ``stopwatch''. In order to measure the processor time of a process, the time between Start and Stop spent servicing other processes is discounted from the elapsed time measured by gettimeofday [1]. Thus, it is possible to measure processor time for very short requests.
Each server process collects statistics (throughput, disk operations, parsing, processing and logging times) for the requests that it receives and serves. In addition, the SM incorporates the concept of resource classes. Each request is categorized into one of several predefined classes depending on the size of the file requested. Classes are defined in a configuration file specifying the maximum file size for each class. The statistics collected by a server process are separated by class. Thus, while handling a request, a server updates the counters associated with the class of the request being serviced. In this manner, the SM generates cumulative information for each class and each server process. To keep overhead low, this information is written to disk by the server processes after 10 requests have been served. After data collection is complete, these cumulative values can be processed to generate other statistics such as averages, etc. Table 2 summarizes the main measurements obtained by WebMonitor.
Kernel Module Measures - general statistics
cpu_user(%) percentage of elapsed time spent in user mode cpu_sys(%) percentage of elapsed time spent in kernel mode cpu_idle(%) percentage of elapsed time CPU was idle reads/s total number of read operations (disk transfers) per second rblk/s total number of blocks read per second writes/s total number of write operations (disk transfers) per second wblk/s total number of blocks written per second pagein/s number of pages the system paged in (including those found in buffer cache) per second pageout/s number of pages the system paged out (including those found in buffer cache) per second interrupts/s number of interrupts from all devices per second net_intrpt/s number of interrupts from network interface per second disk_intrpt/s number of interrupts from disk driver per second context swtch/s number of context switches per second
Kernel Module Measures - process statistics
cpu(%) percentage of cpu used by all copies of the monitored program mem(%) percentage of memory used by all copies of the program started processes total number of copies of the monitored program running processes number of copies of the monitored program waiting to run
Kernel Module Measures - network statistics
rx_packets number of packets received per second tx_packets number of packets transmitted per second rx_errors number of errors during reception tx_errors number of errors during transmission number of TCP connections in each state
Server Module Measures
conn/s number of connections made to the server per second Mbit/s number of Megabits served per second reads/conn number of read calls per connection rblk/conn number of blocks read per connection cpu_parsetime processor time spent parsing the request cpu_proctime processor time spent processing the request cpu_logtime processor time spent performing standard HTTP logging e_parsetime elapsed time spent parsing the request e_proctime elapsed time spent processing the request e_logtime elapsed time spent performing standard HTTP logging Monitor Overhead
One of the main concerns in the design of WebMonitor was to keep overhead as low as possible. The response time (in seconds) and throughputs (connections/second and Mbits/second) measured by WebStone for the server with and without WebMonitor (KM and SM modules) are shown in Table 3. This table shows that the overhead introduced by the monitor is less than 4% for all three measures.
With WebMonitor Without WebMonitor Difference (%) Connections/second 17.35 17.96 3.51 Mbits/second 3.91 4.02 2.81 Response Time (seconds) 1.74 1.69 2.87 We also compared the cost of using our system calls against the cost of obtaining the same information through the /proc filesystem. Compared to WebMonitor system calls, collecting the same data via /proc is approximately 200 times more expensive for some system calls [1].
Results
One of the main goals of WebMonitor is to understand how time is spent servicing HTTP requests and how different components of the server platform are utilized. WebMonitor's modules address this goal by measuring server performance at different levels. KM measures CPU user and system time, and the rate at which different kernel services are invoked (e.g., read calls per second, interrupts per second, etc). SM measures CPU utilization and latency while handling requests, as well as per-connection use of some kernel services (e.g., read operations per connection).
We demonstrate the utility of our WWW server performance monitor at the most interesting operating point of the server - when it has just become saturated. To determine the saturation point, we ran experiments varying the number of WebStone clients that communicate with the server. Our results are for 30 clients that continously issue document requests to a single server over a 5 minute period. This configuration causes both the CPU and memory of the server to be utilized at levels greater than 90%. All results shown are average values from 15 experiments. We present results for a basic workload (workload A) described above. We then compare these results to those for a workload with smaller files (workload B).
Tables 4 and 5 show Server Module (SM) results for both workloads. Recall that SM groups performance data for different request classes, defined by file sizes. Thus, classes for the two workloads are different. Specifically, workload A is composed of files from 3 different classes (classes 1, 3 and 4). Class 1 requests (for HTML and image documents) are for small files; they have a mean size of 12.1 KB and make up the vast majority of the requests (i.e., 94.6%). Class 2 requests (for audio files) are moderate in size (168.8 KB on average) and amount to 5% of requests. Class 3 requests (for video clips) are large (2.3 MB on average) and make up only 0.4% of the workload.
Workload B is obtained by dividing the file sizes of workload A by a factor of 4. The resulting workload has 4 request classes (classes 0, 1, 2 and 4). Class 0 requests are for very small HTML files whose mean file size is 2.5 KB and amount to 84.2% of requests. Class 1 requests (13.8% of the requests) are for bigger HTML and images files, with mean file size equal to 11.8 KB. The mean file size of class 2 requests is 62.5 KB and this class makes up 1.6% of the requests. Class 4 requests are for moderate audio files (567 KB on average) and make up only 0.4% of the workload.
Workload A Class 1 Class 3 Class 4 conn/s 16.39 0.88 0.07 Mbit/s 1.55 1.16 1.26 reads/conn 0.04 3.43 53.41 CPU parsetime(ms)/conn 4.87 4.85 4.63 CPU processingtime(ms)/conn 19.16 148.86 2253.94 CPU logtime(ms)/conn 5.41 6.78 7.70 elapsed parsetime(ms)/conn 24.52 24.58 26.97 elapsed processingtime(ms)/conn 152.93 3785.74 58926.11 elapsed logtime(ms)/conn 785.16 962.11 951.53
Table 4: Server Module Results for Workload A with 30 Clients
The most interesting result in tables 4 and 5 lies in the last six rows, which show the processor and elapsed times of the three different phases of execution of an HTTP request. For both workloads, we can see that, in most cases, the vast majority of the time spent handling a request is spent moving the requested URL from the filesystem to the network (i.e., processing the parsed request). This is true of CPU time for all classes in both workloads. Furthermore, the elapsed processing time also dominates the elapsed parsing and logging time for moderate and large requests (class 3 in workload A and class 4 in both workloads). The CPU and elapsed processing times increase almost linearly with the mean file size. The other measurements shown in tables 4 and 5 that exhibit the same increase are the read operations per connection (reads/conn). This suggests that disk activity explains the increase in elapsed time for processing large requests, as one would expect. Comparing this measurement for both workloads, it is possible to see the difference in disk activity. For example, class 4 requests for workload B have a much smaller mean file size, and, as a consequence, a much smaller number of read operations per connection. One other interesting result is the distribution of network bandwidth among the classes. Note that even though the connections per second rate decreases with class number (for both workloads), the bandwidth that each class consumes on the network does not differ significantly (i.e., between 1 and 1.6 Mbps for workload A, and between 0.2 and 0.5 for workload B). Also, comparing network throughput numbers (Mbits/s) for both workloads, we see that workload A consumes more bandwidth. This is because when files are bigger (as in workload A), the fixed costs associated with servicing each HTTP request are proportionally smaller. However, the aggregate connection throughput (conn/s) is higher for workload B, as expected. In this case, each HTTP request is processed more quickly (yielding greater connection throughput), however, the fixed overhead per request prevents the connection throughput for workload B from being anywhere near 4 times the connection throughput for workoad A.
Workload B Class 0 Class 1 Class 2 Class 4 conn/s 21.82 3.54 0.41 0.11 Mbit/s 0.43 0.33 0.20 0.48 reads/conn 0.01 0.06 0.35 3.71 CPU parsetime(ms)/conn 4.14 4.15 4.27 4.04 CPU processingtime(ms)/conn 11.11 17.06 51.43 434.78 CPU logtime(ms)/conn 4.82 4.19 5.17 5.14 elapsed parsetime(ms)/conn 15.03 15.51 15.71 12.54 elapsed processingtime(ms)/conn 56.34 104.42 666.23 9971.47 elapsed logtime(ms)/conn 693.09 765.41 1025.69 1033.70
Table 5: Server Module Results for Workload B with 30 Clients
The SM results suggest that most of the CPU time consumed by the HTTP processes is spent in the kernel. In other words, the task of moving the requested URL from the filesystem to the network is the most expensive part of handling a request. Since both the filesystem and the networking code are in the kernel, one would expect time spent in the kernel to be greater than time in user space. To this hypothesis, we tested: we instrumented the HTTP processes to call getrusage after 10 requests, and record the user and system time per connection. These results showed that our HTTP processes, when stressed with workload A, consumed an average of 50 msec of CPU time in the kernel per connection, compared to only 5.2 msec in user space. For workload B, the system time was 24 msec and user time was 2.9 msec.
Kernel Module Results
Table 6 shows kernel module (KM) measurements for workload A. Note that the ratio of kernel time to user time is high (approximately 10:1), and consistent with the measurements for individual processes. Within the time spent in the kernel, it is also important to observe the frequency of certain kernel operations. For example, there are over 30 pages requested from disk (page-in's), 50 context switches, 1000 interrupts and several disk reads performed per second. However, there is also a significant number of disk writes. These are presumably due to paging activity and logging of HTTP requests. Note that the results for HTTP process activity (the last two rows in Table 6) and the measurements for the system as a whole agree. HTTP processes consume more than 90% of the CPU and more than 100% of memory (which indicates paging activity). The difference between the CPU time used by HTTP processes and the CPU time for the whole system is due to the activity of kernel processes (most notably kswapd and update), and the fact that the sampling interval for the processes is slightly shorter that the sampling interval for the whole system. The number of HTTP processes suggests that Apache's process management starts approximately 27 processes to service 30 concurrent connections, given our workload. However, an average of about 25 processes are active during our runs.
Performance data for the system as a whole
cpu_idle(%) 0.62 page-in/s 39.04 cpu_user(%) 9.06 page-out/s 2.01 cpu_system(%) 90.33 reads/s 7.29 interrupts/s 1037.02 writes/s 4.95 net_interrupts/s 608.30 ctxt/s 51.94 disk_interrupts/s 328.50
Performance data for HTTP processes
cpu (%) 93.67 started processes 27.70 mem (%) 106.53 running processes 24.90
Table 6: Kernel Module Results for Workload A with 30 clients
Table 7 shows KM results for a different workload with smaller files (workload B). Recall that workload B is obtained by dividing the file sizes presented in Table 1 by a factor of 4, but still using 30 clients. These results show that our main conclusion, the high ratio of system to user time, holds even when the sizes of the files being requested at the server are sufficiently small to reduce disk activity. For both system-wide and HTTP process results, we observe that system time is 8.6 times as high as the time spent in user mode. It is also important that high rate of some kernel services is also independent of the workload. For example, the number of disk writes, context switches and page-out's, are all about the same for workloads A and B. The number of started and running HTTP processes for workload B is only slightly smaller, and agrees with the percentage of CPU and memory they use. The main difference between the results for the two workloads is their disk activity. There are much fewer read operations and page-in's when the file sizes are reduced. Also, the number of disk interrupts handled per second drops significantly.
Performance data for the system as a whole
cpu_idle(%) 2.43 page-in/s 3.81 cpu_user(%) 10.20 page-out/s 2.34 cpu_system(%) 87.41 reads/s 1.03 interrupts/s 560.70 writes/s 5.54 net_interrupts/s 411.59 ctxt/s 43.33 disk_interrupts/s 49.11
Performance data for HTTP processes
cpu (%) 90.69 started processes 24.81 mem (%) 95.97 running processes 22.46
Table 7: Kernel Module Results for Workload B with 30 clients
Table 8 shows the number of packets received and transmitted by the Ethernet interface card for both workloads. The number of transmitted packets for the workload B is smaller than for workload A. Likewise, the number of received packets is smaller for workload B. This is presumably due to the fixed overhead associated with each request that prevents connection throughput from increasing proportionally with the decrease in file sizes in workload B. The measurements obtained by KM reported no errors in the server network interface during the experiments. This is consistent with the WebStone results that reported no errors on the client side.
Workload A Workload B Packets transmitted per second 442.82 273.77 Packets received per second 317.75 251.47
Table 8: Kernel Module network statistics for both workloads
The validation of the results collected by KM and SM was done through comparison with similar measurements obtained through the /proc filesystem and WebStone, respectively. The differences between them are less than 1% [1].
Concluding Remarks
Server performance has become a crucial issue for improving the overall performance of the World-Wide Web. This paper describes WebMonitor, a tool for evaluating and understanding server performance, and presents new results for realistic workloads.
WebMonitor measures activity and resource consumption, both within the kernel and in HTTP processes running in user space. WebMonitor is implemented using an efficient combination of sampling and event-driven techniques that exhibit low overhead (less than 4%). We demonstrate the utility of WebMonitor by measuring and understanding the performance of a Pentium-based PC acting as a dedicated WWW server. Our workload, generated by WebStone, uses file size distributions with a heavy tail. This captures the fact that Web servers must concurrently handle some requests for huge files and a large number of requests for small files.
Our results show that in a Web server saturated by client requests, up to 90% of the time spent handling HTTP requests is spent in the kernel. These results emphasize the important role of operating system implementation in determining Web server performance. Although this paper provides an important understanding of World-Wide Web server behavior under heavy load, the picture is far from complete. There is still the question of whether memory, I/O, or the CPU is the bottleneck for Web servers. The answer to this question will probably depend on the nature of the workload, however, there will continue to be a demand for server architectures that perform well for heterogeneous workloads. This suggests the need for new operating system implementations that are designed to perform well when running on Web servers.
The Authors
Jussara Almeida, graduate student, Universidade Federal de Minas Gerais, Brazil. Research interests include operating systems, distributed systems, load balancing and performance analysis of WWW server. Her current research involves investigating the interaction between WWW servers and operating system, focusing on new approaches to improve performance.
Email: jussara@dcc.ufmg.br<
http://www.dcc.ufmg.br/~jussara
Post: Depto. de Ciência da Computação,
Universidade Federal de Minas Gerais,
Belo Horizonte,
Minas Gerais 31270-010 - Brazil
Virgilio Almeida, Professor, Universidade Federal Minas Gerais, Brazil. Since 1989 Virgilio has been with the Computer Science Department at the Universidade Federal de Minas Gerais. Industrial positions held in the past include systems analyst at the Brazilian oil company. In 1996, Virgilio was a Visiting Professor at Boston University and in the first months of 1997, he was a Visiting Researcher at XEROX PARC, Palo Alto. Virgilio published many technical papers and is co-author of three books. His most recent book entitled Capacity Planning and Performance Modeling , was co-authored with Daniel Menasce and Larry Dowdy and published by Prentice Hall in 1994.
Research interests include performance modeling techniques, capacity planning, performance analysis of caching systems for large-scale distributed systems, workload characterization for WWW servers and clients, performance analysis and modeling of NT operating system, and effects of self-similar distributions on performance.
Email:virgilio@dcc.ufmg.br<
http://www.cs.bu.edu/associates/virgilio
Post: Depto. de Ciência da Computação,
Universidade Federal de Minas Gerais,
Belo Horizonte,
Minas Gerais 31270-010 - Brazil
David Yates, Ph.D., Assistant Professor, Boston University. David has 10 years experience in computer networks, including both research and development. Understanding and improving the performance and scalabiliy of the World-Wide Web has been the goal of David's recent research. His dissertation explored the appropriate networking support for shared-memory multiprocessor Web servers. The research issues he examined are important for supporting communication of continuous media, such as voice and video, as well as text and image data. As part of this work, he designed, implemented, and measured the performance of a parallel version of the Internet protocol suite. Prior to entering graduate school, David worked for six years in software development. He spent most of that time designing and implementing network protocols for commercial products.
Email: djy@cs.bu.edu
http://www.cs.bu.edu/faculty/djy
Post: Computer Science Department,
Boston University,
Boston, MA 02215 USA
Note
1. This work was partially supported by a grant from CNPq Brazil and by NSF grants CDA-9529403 and CDA-9623865.
References
- 1
- Jussara Almeida, Virgílio Almeida, and David J. Yates, 1996. Measuring the behavior of a World-Wide Web server. Technical Report CS 96-025 (November), Boston: Boston University.
- 2
- Jussara M. Almeida, Virgílio Almeida, and David J. Yates, 1997. "Measuring the behavior of a World-Wide Web server," In: Seventh Conference on High Performance Networking (HPN), pp. 57-72 (April), White Plains, N.Y.: IFIP.
- 3
- V. Almeida, A. Bestravos, M. Crovella, and A. Oliveira, 1996. "Characterizing reference locality in the WWW," Proceedings of IEEE-ACM PDIS'96 (December).
- 4
- M. Arlitt and C. Williamson, 1996. "Web server workload characterization," Proceedings of the 1996 SIGMETRICS Conference on Measurement and Modeling of Computer Systems (May).
- 5
- M. Crovella and A. Bestavros, 1996. "Self-similarity in world wide web traffic: Evidence and possible causes," Proceedings of the 1996 SIGMETRICS Conference on Measurement and Modeling of Computer Systems (May).
- 6
- Andrew Kantor and Michael Neubarth, 1996. "How big is the Internet?" Internet World, Volume 7, Number 12 (December),pp. 44-51.
- 7
- D. Menasce, V. Almeida, and L. Dowdy, 1994. Capacity Planning and Performance Modeling. Englewood Cliffs, N. J.: Prentice Hall.
- 8
- Jeffrey C. Mogul, 1995. "The case for persistent-connection HTTP," In: SIGCOMM Symposium on Communications Architectures and Protocols, pp. 299-313 (August), Cambridge, Mass.: ACM.
- 9
- Jeffrey C. Mogul, 1995. Network behavior of a busy Web server and its clients. Research Report 95/5 (October), DEC Western Research Laboratory.
- 10
- Jeffrey C. Mogul, 1995. "Operating system support for busy Internet servers," In: Proceedings of the Fifth Workshop on Hot Topics in Operating Systems, (May).
- 11
- D. Robinson and the Apache Group, 1995. APACHE - An HTTP Server, Reference Manual, at http://www.apache.org.
- 12
- R. McGrath T. Kwan and D. Reed, 1995. "NCSA's world wide web server: Design and performance," IEEE Computer, (November).
- 13
- G. Trent and M. Sake, 1995. WebStone: The First Generation in HTTP Server Benchmarking, (February), at http://www.sgi.com/Products/WebFORCE/WebStone/paper.html.
- 14
- M. Welsh, 1994. The Linux Bible. Yggdrasil Computing Incorporated, 2
edition.


Copyright © 1997, ƒ ¡ ® s † - m ¤ ñ d @ ¥