This article reports on the availability, domain distribution, percentage of Web sites versus Web pages, perceived value, and category of 31,400 Web–based resources selected by 50 public libraries in the United States and Canada. Eighty–seven percent of these resources were available, 60 percent were Web pages, and resources selected by 20 percent of the sampled libraries were finding tools such as general or subject specific search engines. Ninety–three percent of the resources were selected by just one of the 50 libraries; only 17 percent of the resources appeared to be primarily of local interest. The public may be unaware of these unique resources. The public library community must develop programs to increase the awareness and sharing of these evaluated resources.Contents
Introduction
Background
Sampling of Web–based resources
Characteristics of Web–based resources
Categories of Web–based resources
Comparison of attributes of unique and overlapping Web–based resources
Frequently selected resources
Discussion
Conclusions
Introduction
Since the Web emerged more than a decade ago, we have witnessed its phenomenal growth as a medium preferred for information discovery and delivery and its wide acceptance as a major source of scholarly, scientific, commercial, and entertainment information. The variety of information available via the Web ranges from that found in traditional, general reference sources to information contained in scholarly, government, and commercial sources.
The impact of the Web on the behavior of information–seekers led us to examine the attributes of Web–based information sources. In this study, we attempted to characterize resources that public library staff identify, organize and present as a value–added service for their users.
In addition, we wanted to measure the extent of overlap among public library Web–based collections. If the overlap was high, then it would suggest a duplication of effort in identifying, evaluating, linking, and updating links to Web resources. A low percentage of overlap among resources, however, would suggest there is a set of unique resources that are not centrally accessible and are likely to be unnoticed and unused by most public libraries. In either scenario, the library community would benefit from devising collective solutions that would allow libraries to share the investments individual libraries make when creating Web–based resource collections.
The fluid nature of resources on public library Web sites often causes them to resemble “vertical files” that library staffs create to supplement the library’s main collection. The resources in a “vertical file” connect users to a variety of materials containing local, government, “how–to,” unique, specific, current, and authoritative information (Sitter, 1992). Miller (1979), Sitter (1992), Spencer (1993) and others have pointed out the general value of vertical files for public libraries, while Anderson (2001) and Falk (1996) have explained the impact of new technologies on paper–based vertical file collections. Materials that could be traditionally found in the “vertical files” of public libraries, including time–sensitive information, are freely available in ever–increasing numbers on the Web and users are making use of them (Neuhaus, 1998).
This research also relates to the debate among academic librarians about the ways in which electronic collections are impacting — and will continue to transform — information provision. Younger (2002), for example, has noted a philosophical shift from physical collection development to meeting of user information needs through electronic resources.
File collections, print or Web–based, have not been characterized empirically. Hundreds of articles have addressed the impact of the Web on the services that public libraries provide. However, none characterizes Web–based information sources or reports on the extent of resource overlap among public library Web–based collections. This research seeks to fill these gaps.
Sampling of Web–based resources
Web site sampling
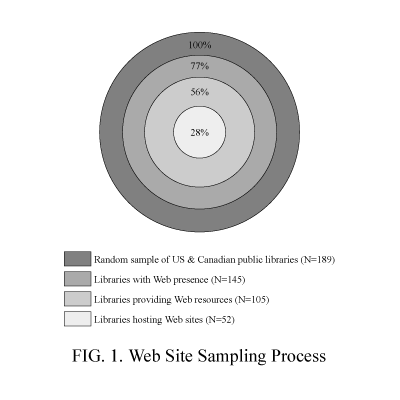
Previously, we reported our research into public library adoption of Web technologies, which was based on a random sample of 189 libraries from across the United States and Canada (Prabha and Irwin, 2003). In that study, we found that 145 libraries (77 percent) had a “Web presence,” defined as at least one official Web page describing library services. One hundred and five public libraries (56 percent) provided access to external Web resources. Fifty–two libraries (28 percent) provided Web services from servers they managed. One of the Web sites in the sample, however, did not yield any links and another site did not exist, although it was listed. Thus, the total number of public libraries that hosted their own Web services decreased from 52 to 50 (Figure 1).
We did not examine the content of library Web sites that were hosted by commercial services, municipal and county governments, state, provincial, and national libraries, or library systems. Inclusion of these Web sites would have resulted in a sample of Web resources that was not necessarily selected by library staff at the local library. Our selection of libraries hosting Web sites is analogous to choosing libraries that create their own vertical file collections.
For our earlier study, we gathered data on the populations served by the public libraries that had a Web presence (Prabha and Irwin, 2003). Data were available for only 124 of the 145 libraries [ 1]. For that study, we ranked the libraries for which this information was available by the size of the population served and then divided them into four groups of equal size (31 libraries in each group). The top quartile included libraries serving populations of 42,000 or more users while those in the second quartile served 16,000 to 41,999. Libraries in the third quartile served populations of 6,400 to 15,999 and those in the bottom quartile served fewer than 6,400.
We found that 64 percent of libraries in the top quartile hosted their own Web sites, 55 percent in the second quartile, 32 percent in the third quartile and 16 percent in the bottom quartile. This distribution shows that public libraries serving populations greater than 16,000 users are better represented in this study’s sample than libraries serving populations under 16,000.
Web–based resource selection
Web resources can be broadly grouped into two categories: internal and external. “Internal” Web resources are those created by the local library and exist on the library’s own site. They tend to be navigational tools, pointing users to library services and administrative information or, occasionally, to digital content created by local libraries. Because internal resources are not subjected to selection criteria they fall out side the scope of this study. We examined “external” Web resources; they reside on servers not under the jurisdiction of the local library. A program specifically developed for this study extracted a total of 39,960 links to external resources. The data collection procedure could not, of course, include resources that reference librarians add as bookmarks on their Web browsers. Web–based resources that require user authentication, namely proprietary aggregator services (e.g., EBSCO and Gale), were automatically excluded.
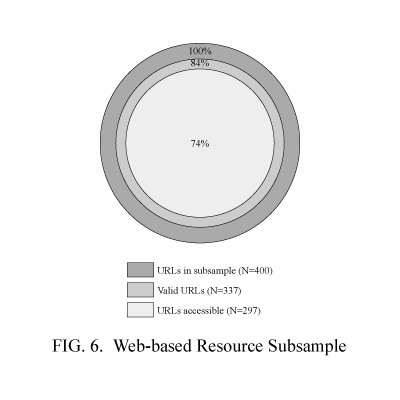
We drew a random subsample of 400 resources from the 39,960 harvested links for manual review. A sample of size of 384 resources {[n = (1.96)2 (.05)2 (.05)2 ]} was needed for a 95 percent confidence level. The manual review uncovered a number of irregularities and inaccuracies in the uniform resource locators (URLs), as well as duplicate URLs within individual libraries that went undetected by the link extracting software. These URLs included links to online public access catalogs that resided on separate servers under different addresses, but which we categorized as internal resources. Removal of these problematic resources reduced the subsample from 400 to 337.
The large number of problem URLs in the subsample led us to review the complete set of harvested links manually. When we removed the problem URLs, the number of links to external resources was reduced from 39,960 to 35,980. As shown in Figure 2, this number was reduced to 31,400 when duplicate URLs within each of the sampled libraries were eliminated. The next set of findings is based on these 31,400 Web–based resources.
Characteristics of Web–based resources
For the set of 31,400 Web–based resources, we recorded data on the following attributes: availability, top–level domain suffix, position of the resource within the Web structure, perceived value, and content.
Availability of resources
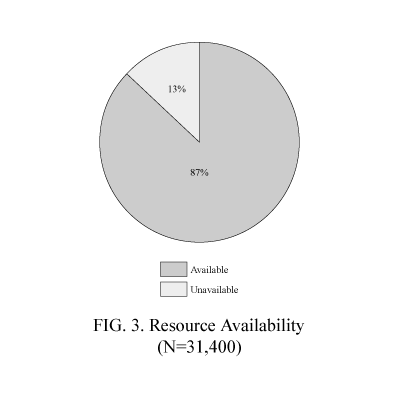
Many Web users experience the frustration of clicking on a link and, for one reason or another, not being able to access the desired resource. This issue prompted us to calculate the percentage of resources that were accessible. An automated process recorded the hypertext transfer protocol (HTTP) status code of each harvested link [ 2]. For our purposes, an HTTP status code of 200 indicated that the linked resource was accessible while a status code of 404 indicated a broken link (Fielding, et al., 1999). Figure 3 shows that 87 percent of the 31,400 Web resources were available.
Top level domains of resources
When the Web space was originally divided into domains (sectors), the domain suffix (e.g., the .org part of the URL http://www.oclc.org) associated an URL with a corresponding economic sector. For example, the Internal Revenue Service (IRS), a governmental agency, provides information at http://www.irs.gov, while the Ohio State University, an educational institution, is located at http://www.osu.edu. Generally, Web resources that have content primarily for commercial purposes would have an URL with a commerce suffix (.com), and the owners and creators of those sites would be commercial entities. Likewise, resources produced or presented by non–profit entities would have an URL suffix of .org.
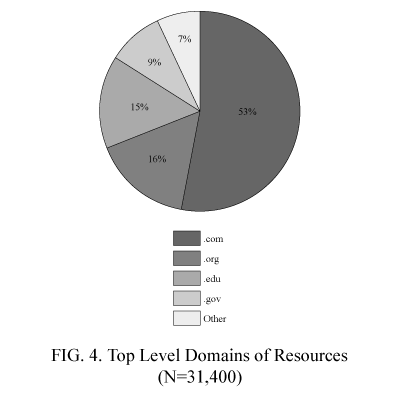
If the suffixes for URLs are assigned by sector, then the relationship between the Web hosts and the creators of Web resources could be surmised from the suffixes. We could then infer the provenance of Web resources, which would help us to evaluate their information. Top–level domain distribution of the Web resources is presented in Figure 4.
Education, government and non–profit sectors account for 40 percent of the resources. In contrast, 53 percent of the resources are in the commerce sector. These percentages, however, do not accurately reflect domain distribution because URL suffixes seem to be assigned or selected without considering the economic sector of the Web site’s creator. Nonetheless, we were able to observe a rough distribution among domain suffixes.
Position of resources
The relative position of a resource in the Web structure as a site or page is significant. It is similar to distinguishing between a whole work (e.g., a monograph) and its constituent part (e.g., a chapter). In the Web medium, the address http://www.irs.gov is a site, whereas the address http://www.irs.gov/newsroom, which is lower in the hierarchy, is a collection of pages, and http://www.irs.gov/newsroom/article/0,,id=118396,00.html is a page (O’Neill and Lavoie, 2000).
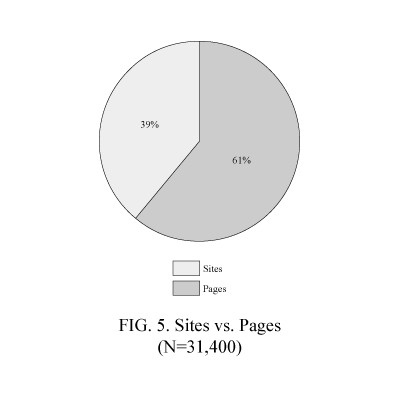
Whether a Web–based information source is categorized as a site, collection of pages or page is contextual. This attribute, without context, does not indicate the volume of content any more than the attribute monograph, in a physical medium, indicates the number of pages. We grouped collection of pages and pages together, as the distinction was not important for this study. We manually reviewed all 31,400 URLs to determine whether a given URL pointed to a site or a page. Thirty–nine percent of the links pointed to sites, while 61 percent pointed to pages (Figure 5).
Perceived value of resources
In scholarly literature, the number of times a journal article or a book is cited by other authors is regarded as an indicator of the relative influence or importance of the item. The greater the number of times an article is cited, the greater the impact of that article on scholarly communication.
Link analysis is similar to citation analysis. When applied to Web resources, link analysis identifies influential Web sites and pages. The value or importance of Web–based resources was measured by the number of times a particular resource was linked to (i.e., referenced by) other resources on the Web. Such links are referred to as “inbound links.” A program was written to search and retrieve from Google the number of inbound links to URLs of each resource in the sample. The number of inbound links in our sample ranged from zero to 667,000 — the largest number being for Adobe Acrobat Reader. The median number of inbound links was 72.
Categories of Web–based resources
We wanted the categories of resources to emerge inductively from the data. However, categorization was challenging because most resources contained a wide variety of information. Therefore, we organized the resources in a manner similar to the physical arrangement of materials in libraries (e.g., physically separating maps, periodicals, and audiovisual materials), paying attention to primary function and audience. Findings are based on the examination of the subsample of resources.
During the data verification process described earlier, the subsample of 400 links was reduced to 337. Of these, 303 information sources were accessible. However, six of the 303 resources required a library card number or IP authorization and, therefore, could not be examined. Thus, the number of unique resources available for categorization was reduced to 297.
Web–based resources that are used mainly for consultation — reference — accounted for 36 percent of the total number of sources. These resources tended to be finding tools (for example, search engines like Google and directories like the “Librarians’ Index to the Internet” at http://www.lii.org), reference sources (for example, dictionaries, encyclopedias and thesauri at http://www.bartleby.com and almanacs such as the CIA Fact Book at http://www.cia.gov/cia/publications/factbook/geos/pl.html), and readers’ advisory tools (such as bestsellers lists and recommendations by genre from Amazon and Barnes and Noble).
Table 1: Familiar categories of Web–based resources.
Resource Category Percent
(n=297)Reference 36 Recreational 36 Cultural/government 14 Digital equivalents of standard publications 11 Other 3
Another 36 percent of the Web–based resources contained content that would cater to users’ interests in hobbies and leisure pursuits. Cultural institutions and government bodies produced 14 percent of the resources. Digital equivalents of books and serials — the mainstay of library collections — comprised just 11 percent of the resources.
Comparison of attributes of unique and overlapping Web–based resources
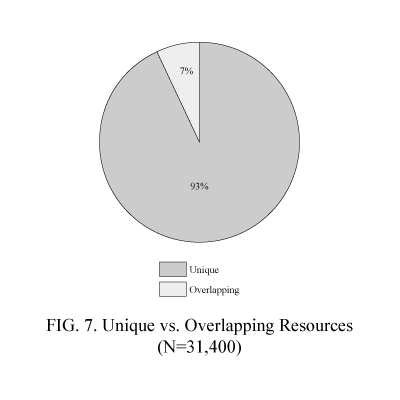
To recap, we examined a pool of 31,400 Web–based resources that were selected by 50 public libraries in the study. Though a single resource could appear multiple times on a library Web site, as noted before, we counted a resource only one time per library. Because we extracted resources from 50 libraries in the sample, the number of times a Web resource could be selected ranged from a minimum of one to a maximum of 50. Figure 7 shows that an overwhelming percentage of resources were selected by just one of the 50 libraries in the study sample.
Surprisingly, only 17 percent of the subsample presented information mainly of interest to the library’s local users. We had expected a far higher percentage of local resources, given that the overwhelming percentage of resources (93 percent) was unique.
We divided the 31,400 resources into three groups based on the number of times a resource was selected by the libraries in the sample.
- Group 1: 29,239 resources (93 percent) were selected by only 1 of the 50 libraries.
- Group 2: 2,100 resources (7 percent) were selected by 2 to 9 libraries.
- Group 3: 61 resources (0.2 percent) were selected by 10 or more libraries.
Of Group 1’s 29,239 unique resources, 87 percent were available. In comparison, 100 percent of the 61 resources in Group 3 were available, and 94 percent of Group 2’s were available. We see a similar pattern in the percentage of sites selected in each of the Groups. Table 2 shows that 33 percent of resources in Group 1 were selected at the site level. Comparable percentages for Group 2 and Group 3 were 64 percent and 95 percent, respectively. Median values of inbound links for the resources in the three groups are: 22 for Group 1, 2,260 for Group 2, and 20,800 for Group 3.
Table 2: Availability, Web hierarchy level and inbound links
of resources in the three groups.
Number of Libraries
Selecting a Web ResourceNumber of
resourcesPercent
availablePercent sites
(vs. pages)Median
number of
inbound
linksOne library (Group 1) 29,239 87 31 22 Two to Nine Libraries (Group 2) 2,100 94 64 2,260 Ten or more libraries (Group 3) 61 100 95 20,800 All 50 Libraries 31,400 87 39 72
Frequently selected resources
We examined the 61 resources selected by ten or more libraries in the sample. Top ranking resources were search engines, as shown in Table 3. Two of these, MapQuest and Cyndi’s List, are subject–specific resources.
Table 3: Top ranking Web resources.
Rank Selected resource Percent of
libraries
(n=50)1 Yahoo 52 2 48 3 AltaVista 42 4 Excite 38 5 Yahooligans 38 6 Lycos 36 7 HotBot 34 8 Dogpile 34 9 MapQuest 34 10 Cyndi’s List 32
Discussion
This study attempted to characterize the Web–based resources available on local public library Web sites that are managed by the libraries. Attributes selected for the characterization of these resources were availability, domain distribution, perceived value, and category.
An 87 percent availability rate for Web–based resources speaks well for the selection criteria public library staffs employ. This finding shows that public library staffs carefully select, check, and update links to resources. The high percentage of available resources is particularly remarkable considering 60 percent of the 31,400 resources selected are pages, which may not be as stable as sites.
We said that a site level resource is analogous to a monograph or a periodical and a page level resource is comparable to a chapter within a monograph or an article within a periodical. Since 60 percent of the resources were pages, public libraries appear to select resources that, in the print world, are treated as suitable for indexing as opposed to cataloging. This finding suggests that electronic vertical files may be similar to paper vertical files with respect to the granularity of the resources.
It is clear that when many libraries select a resource, its availability is likely to be high, as evidenced by the 100 percent availability of Group 3 resources. A frequently selected resource is likely to be a site, as opposed to a page, as 95 percent of resources in Group 3 were sites. Most frequently selected resources tend to be search engines, which are analogous to a library’s paper–based finding tools, such as indexes.
Link analysis showed that resources selected frequently by libraries are also referenced by a large number of other Web sources. Note the median number of inbound links is 20,800 for resources in Group 3 and 2,260 for resources in Group 2. These findings show that frequently selected resources in libraries share some commonalities.
Findings from the domain distribution are, perhaps, of lesser value than we had expected because domain suffixes are granted without careful adherence to the intent of the original domain division scheme. As mentioned previously, this scheme attempted to organize Web sites based on broad differentiation by economic sector.
Another important objective of this research was to determine the percentage of Web–based resources that were selected by multiple public libraries as an indicator of redundant work. The findings show that the magnitude of such resources among public libraries is only seven percent. In other words, Web–based resources in public libraries are predominantly unique (93 percent). This discovery suggests that these professionally selected resources are probably not noticed or used by most libraries and their users because they are not centrally accessible.
The overwhelming percentage of unique resources could possibly be attributed to the selection of a sizeable number of resources that are mainly of local interest. Our analysis, however, did not support this explanation. A manual analysis of a subsample of resources showed that just 17 percent of the resources had content that appeared to be of interest mainly to local clientele. Therefore, we suspect the high volume of unique resources was in part a function of the varying granularity of the resources selected, a conclusion that has been borne out elsewhere for certain academic libraries (Irwin, 2002).
Conclusions
For most of these libraries, the Web has become a place where subscription and free electronic resources (electronic vertical files) come together in an effort to meet users’ information needs. Electronic vertical files may be viewed as more visible and more easily accessible vertical files that keep users connected to their public libraries. Electronic vertical files have qualities absent in the static paper files, chiefly interactivity and connectivity, which are valued by users. These qualities probably make electronic vertical files more valuable than paper vertical files. By 2002, these electronic files had become an integral part of library services in 26 percent of the public libraries in the United States and Canada.
Since 93 percent of the 31,400 Web resources were selected by just one of the 50 libraries, it appears that a majority of professionally selected Web resources are available only to users of the selecting library. In other words, carefully selected and presented Web resources are not available to library users who only use their own public library Web sites. Public library leaders, perhaps, have an opportunity to address this community–level inefficiency and open these professionally selected resources to a broader constituency.
The importance public libraries place on developing common vocabularies for organizing and presenting Web–based resources does not seem to match the investment made in selecting, organizing and presenting these resources. Lack of attention to developing and implementing standards for these critical bibliographic functions could negatively affect user success rates in finding information. Adoption of standard vocabulary in Web page titles could help library resources achieve higher rankings in search engine retrievals, such as those determined by the Google PageRank algorithm (Brin and Page, 2000).
Use of public library Web–based collections by users, however, is not yet well understood. Studies on patron use of public library Web–based resource collections are needed. Which types of resources are used? How frequently are they used? What kinds of access points would improve use of Web resources among public library users? The answers to these questions would aid the evolution of Web–based collections in public libraries.
About the authors
Chandra Prabha is a Senior Research Scientist in the OCLC Office of Research ( http://www.oclc.org/research/) in Dublin, Ohio. Her research interests include user approaches to finding information resources, collection characteristics, and cataloging and interlibrary loan workflows.
Raymond Irwin was a Research Associate in the OCLC Office of Research at the time of the study. He holds a PhD in History.
Acknowledgments
Brian Lavoie and Andrew Houghton of OCLC Office of Research wrote the program for harvesting Web sites and calculating inbound links respectively. The authors are grateful to our colleagues — Robert Bolander, Ishwar Laxminarayan and Lawrence Olszewski — for their thoughtful comments on earlier versions of this article.
Notes
1. In the earlier study, a sample of 200 public libraries was originally drawn from the American Library Directory (2000). One hundred eighty–nine libraries in this sample met the definition of “public library.” Of these 189, 145 had some sort of official presence on the Web. Of the 145, 52 linked to Web resources, but only 50 linked to harvestable, external resources on the public Web.
2. Several classes of three–digit status codes were created for HTTP 1.1 under the auspices of the Internet Society. The 2xx class indicates that a client’s request was successfully received and processed. Though the presence of other codes does not necessarily indicate that a given resource is unavailable, in our analysis such codes were extremely rare. Therefore, a status of 200 was chosen as an indicator of accessibility.
References
Cynthia Anderson, 2001. “Vertical files: The super–eights of tomorrow?” The Book Report, volume 20, number 3 (November/December), pp. 36–37.
Sergey Brin and Lawrence Page, “The anatomy of a large–scale hypertextual web search engine,” at http://www-db.stanford.edu/~backrub/google.html, accessed 24 May 2005.
Howard Falk, 1996. “Computer–based vertical files,” The Electronic Library, volume 14 (August), pp. 365–368.
R. Fielding, J. Gettys, J. Mogul, H. Frystyk, L. Masinter, P. Leach, and T. Berners–Lee, 1999. “Hypertext Transfer Protocol — HTTP/1.1,” at http://www.ietf.org/rfc/rfc2616.txt, accessed 24 May 2005.
Raymond D. Irwin, 2002. “Characteristics of frequently selected free web resources in computer science: An exploratory study of academic libraries,” Science and Technology Libraries, volume 23, number 1, pp. 71–85.
Shirley Miller, 1979. The vertical file and its satellites: A handbook of acquisition, processing, and organization. Littleton, Colo.: Libraries Unlimited.
Chris Neuhaus, 1998. “Browser’s choice: A comparative use study of traditional and electronic vertical files,” Reference Services Review, volume 26, number 2 (Summer), pp. 79–86.
Edward T. O’Neill and Brian F. Lavoie, 2000. “Bibliographic control for the web,” Serials Librarian, volume 37, number 3, pp. 53–69.
Chandra Prabha and Raymond D. Irwin, 2003. “Web technology in public libraries: findings from research,” Library Hi Tech, volume 21, number 1, pp. 62–69.
Clara Loewen Sitter, 1992. The vertical file and its alternatives: A handbook. Englewood, Colo.: Libraries Unlimited.
Michael D.G. Spencer, 1993. Readings on the vertical file. Englewood, Colo.: Libraries Unlimited.
Jennifer A. Younger, 2002. “From the inside out: An organizational view of electronic resources and collection development,” Journal of Library Administration, volume 36, number 3, pp. 19–38.
Editorial history
Paper received 6 June 2005; accepted 15 July 2005.
HTML markup: Diana Duncan and Edward J. Valauskas; Editor: Edward J. Valauskas.


Copyright ©2005, Chandra Prabha and Raymond D. Irwin.
Characteristics, uniqueness and overlap of information sources linked from North American public library Web sites by Chandra Prabha and Raymond D. Irwin
First Monday, volume 10, number 8 (August 2005),
URL: http://firstmonday.org/issues/issue10_8/prabha/index.html