The paper addresses the issue of how online natural language question answering, based on deep semantic analysis, may compete with currently popular keyword search, open domain information retrieval systems, covering a horizontal domain. We suggest the multiagent question answering approach, where each domain is represented by an agent which tries to answer questions taking into account its specific knowledge. The meta–agent controls the cooperation between question answering agents and chooses the most relevant answer(s). We argue that multiagent question answering is optimal in terms of access to business and financial knowledge, flexibility in query phrasing, and efficiency and usability of advice. The knowledge and advice encoded in the system are initially prepared by domain experts.
We analyze the commercial application of multiagent question answering and the robustness of the meta–agent. The paper suggests that a multiagent architecture is optimal when a real world question answering domain combines a number of vertical ones to form a horizontal domain.
Contents
Introduction
Choosing a multiagent architecture
Multiagent protocol
Principal and accompanying agents
Design of the multiagent Q/A system
Evaluation of multiagent performance
Discussion
Conclusions
Introduction
The role of automated advisors in e–commerce and various financial and business services has dramatically grown in recent years. Fast and convenient access to information about particular products and services has become an important component of their marketing. In asking questions, a user obtains information or advice to make a proper choice, and, conversely, by processing users’ queries, e–commerce businesses obtain valuable data on the desired features of these products and services which may be shared with their producers and providers.
Based on 40 years of experience in deploying question answering (Q/A) systems, it is clear that satisfactory answers for typical users require full–scale linguistic processing. Questions of an average user are sufficiently complex to require substantial syntactic and semantic processing.
About six to eight years ago there was a new interest in using full–scale natural language processing to answer questions online. A series of companies have developed natural language technologies to tackle a new demand for question answering for e–businesses; the number of patents were growing exponentially. However, a few years ago it became clear that an implementation of full–scale question answering which provides accurate access to extensive and deep (vertical) knowledge is rather expensive and hard to scale up. The market niche of information access within a vertical domain, which was initially thought to be occupied by natural language question answering technologies, has been overtaken by keyword search portals. Regrettably, customer expectations of question answering accuracy in vertical domains have been downgraded.
Usually, the higher the quality of question answering (deeper knowledge and more precise answer), the higher the development cost. Each natural language technology resolves the conflict between low development cost, flexibility and scalability of superficial natural language processing and accuracy, understanding of complex questions, and access to deep knowledge of full-scale natural language processing with semantic analysis. Nowadays, there is a tendency to the former; however, a majority of users are still expecting to take advantage of the latter. The former approach is traditionally thought to be better suited for a horizontal domain (a bit of information about a wide area), the latter is only required to handle vertical domains (extensive knowledge on a narrow subject).
The question we address here is whether it is possible to build a question answering system with precision of a vertical domain and coverage of a horizontal domain. This paper introduces the multiagent architecture so that each agent is capable of answering questions in a vertical domain, whereas knowledge of the whole multiagent community covers a horizontal domain.
Question answering in e–commerce
We draw attention to the following steps in an overall customer transaction on an e–commerce site:
- Accessing various information – expert advice, reviews and comparison tools.
- Choosing the product or service.
- Order processing – payment, delivery, return, warranty arrangements etc.
- Customer feedback.
In terms of business solutions, question answering is focused on steps 1, 2 and 4. Natural language (NL) question answering systems advance the frontier of querying methodologies for textual documents and databases, overtaking the keyword– or menu–based systems. In this paper we will show that a multiagent implementation is quite natural for a Q/A system, primarily because of the necessity to consult multiple information sources. In this paper, we analyze the reasons why a multiagent architecture is required for a domain that is, on one hand, complex in terms of its cumbersome knowledge structure, and on the other hand, because of sophisticated queries, needs multiple "opinions" to be handled robustly.
Regarding the business model, companies use question answering means to attract current and potential customers to their Web sites. Adapting businesses towards an e–commerce style brings in additional motivations for using NL Q/A advisors. In terms of compensating for NL services, since the customers are used to having access to any kind of information for free, content providers in e–commerce are expected to purchase NL Q/A products. It has been verified that frequently users, who received valuable advice from a given portal, later order services from the portal’s parent company to fully take advantage of the information provided.
We address both technological and methodological issues of distributed implementations of Q/A and consider the applicable algorithms of multiagent interactions, which are independent of Q/A problems themselves. In semi–structured domains with heterogeneous knowledge sources, the problem of context management is much more crucial for application success than for domains with database knowledge representation, which are usually narrow and strictly circumscribed. The reader can see Brezillon, et al. (1997) for the examples of contextual knowledge–based expert systems in such domains as transportation operator support and food production.
The appropriate structuring of knowledge for commercial question answering systems is not always transparent. The representation of a domain needs to involve not only the information which is immediately specific to it, but also additional information from other, possible distant, domains, which might in the minds of questioners be associated with the main one. Determination of the proper domain(s) or domain component(s) (i.e. the query context) in real time is therefore the essential step preceding the construction of the formal representation of a query and matching it against the domain knowledge representation. The reader may consult Galitsky (2003) for a detailed description of a single–agent commercial NL Q/A system that will serve as a basis of our considerations. The technique of semantic headers is based on matching the formal representation of questions with that of answers, implemented via logic programming.
Why have we chosen the multiagent architecture? We believe that NL problems can be adequately posed and resolved in a vertical (strictly limited) domain. However, in the course of implementing the front ends of e–commerce portals, we discovered that their users require multiple domains to generate advice. Therefore, we found a means to link a number of domains using multiagent architectures, which allow modularization and scalability.
A number of systems have been built which provide NL Q/A functionality in a variety of vertical domains, using horizontal ontologies and attempting to use wide–vocabulary linguistic processing [ 1]. These kinds of approaches do not use multiagent architectures and instead target complex knowledge representation and sophisticated meaning disambiguation. We consider such systems, with fully formalized commonsense knowledge, as the main alternatives to what we offer in this paper.
The condition of logical completeness makes it harder to build an ontology for a vertical domain. As our experience shows, if we were to build a projection of a full–scale ontology like CYC onto our vertical domain, the resultant knowledge would be insufficient, in spite of the huge total number of clauses in CYC. Further advantages of the multiagent approach are thoroughly presented throughout the paper.
Choosing a multiagent architecture
We explore four approaches to managing multiple contexts in natural language understanding systems:
- Singleton – The notion of context is embedded into the reasoning machinery. A single agent determines the set of relevant contexts and activates the corresponding knowledge components.
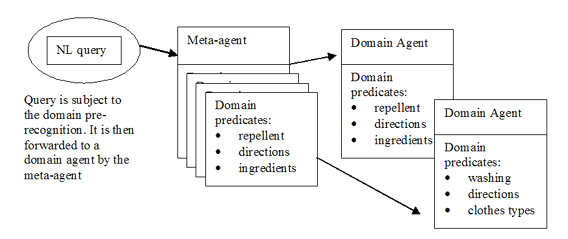
- Centralized – A multiagent architecture with a meta–agent (Q/A domain manager) that performs the context pre–recognition and readdresses the question to the chosen agents (see Figure 1a).
- Uniform (or democratic) – A multiagent architecture, where the agents exchange intermediate results of query processing and come up with a mutually agreed answer under the control of a meta–agent (see Figure 1b).
- Competitive – A multiagent architecture, where the meta–agent forwards questions to each agent for independent parallel processing, and chooses the best results.
All of the above approaches have been described in the literature on multiagent information systems. The first is the closest to the logical community and connected with an attempt to express the notion of context within a logical system (Akman and Surav, 1996; Bonzon, 1997). Performing query translation (into a formal representation language) and reasoning with it, a software agent needs to apply the logical rules of context change (McCarthy, 1993; Buvac, 1996). If domain knowledge is represented in a form where these context change rules are applicable, the expressiveness of knowledge representation would be reduced to a first–order language. Therefore, the first approach is least appropriate for a multiagent Q/A implementation.
Context (sub–domain) determination (before obtaining the exact class) is the traditional methodology of pattern recognition. Hierarchical representation of classes, such that the system first recognizes a broad class and then reveals narrower subclasses, has been approved as a valid architecture for recognition problems of various natures (speech, image, etc.) [ 2]. However, in question answering under complete or partial knowledge formalization, the complexity of context pre–recognition is similar to that of final answer recognition. Our experimental study of the comparative complexity of domain pre–recognition and of building a translation formula (a formal representation of the input NL question) showed that the respective complexities are practically the same: knowledge of both entities and their attributes is required to properly determine query context.
Fig. 1a: The centralized architecture of multi–domain NLP. Examples are from the drugstore.com domain: repellents and their properties. Under the centralized architecture (Figure 1a), the meta–agent performs the domain pre–recognition and determines the involvement of the domain agents. Then only the agents, initially selected by the meta–agent, process the question and attempt to provide answers. From a logical point of view, this is very similar to the first approach.
Below we will show that the uniform or democratic implementation of Q/A itself brings significant advantages, but requires the building of a full–scale multiagent environment where the agents have special reasoning capabilities in addition to semantic processing. Therefore we focus our paper on the evaluation of the fourth, or "competitive," approach as noted above.
Under the uniform or democratic architecture, all agents try to answer a question simultaneously, possibly exchanging results, and the meta–agent chooses the best one(s). There is a particular option under the uniform architecture where a request is directed to a first domain agent, appropriate from the user’s perspective, and the other domain agents are involved in accordance to the decisions of the first domain agent.
Let us consider a question from a generic pharmacy Web portal (for example, DrugStore.com): "How can I wash my pants after applying Ben’s repellent?" The question involves two domains: washing materials and repellents. It is natural kind of question that might appear from a user of an e–commerce retailer, searching for a suitable repellent. This is an easy case to identify the domains: the concept wash is from the former, and the concept repellent points to the latter. The scenario will be as follows.
The meta–agent pre–recognizes the set of domains {washing materials, repellents} from the totality of all those available. Then the query is directed to both of these domains, and as many absent parameters as possible will be found for the predicates wash(xclothestype, xwasher, xwashfrom, xcolor) and repellent(xname, xpower, xvolume, xprice, xinsects, xattribute, xduration, xingredients). Here, xclothestype, xwasher, etc. denote the semantic types of the predicates’ arguments. In our case, the only variable that gets substituted for the first predicates is xclothestype: wash(pants, xwasher, xwashfrom, xcolor).
However, the second predicate will instantiate all of its variables:
repellent($Ben’s Tick and Insect$, 100, 1.25, 3.99,
[mosquitoes,ticks,black_flies,biting_midges,sand_flies,
chiggers,fleas,stable_flies], all_day_protection, 10, [dEET(95), other_Isomers(5)]).Then the domain agents will exchange their results. The repellent agent cannot gain anything from the washing materials agent. On the other hand, the washing materials agent gets the value of xingredients from the repellent agent, having internal knowledge that the hierarchical semantic type xdrug includes xingredients (list of drugs, specific for the repellents) and xwashfrom (list of drugs, a washing material to help clean). So the washing materials agent substitutes xwashfrom with oil as the generalization of dEET and performs the search of xwasher, satisfying wash(pants, xwasher, oil, xcolor).
Fig. 1b: The uniform architecture of multi–domain NLP. Examples are from the drugstore.com domain: repellents and their properties. The scenario for the uniform architecture is supposed to lead to the same results, but in a different way. The user addresses the question to a single domain agent that makes its own decision about the involvement of the other agents. The addressee agent generates the series of translations and estimates the compatibility with its own knowledge representation and with the returned translations (query representations) of the other involved agents, which can in turn send a request to a new set of agents. The role of the meta–agent under the second approach is to eliminate the loop calls and to resolve the conflicts between the agents. For example we should eliminate the situations when either two agents involve the third one at the same stage with different intermediate translation formula, or when the called agent sends requests back to the calling agent.
Multiagent protocol
There are situations where more than one (fully–formalized) domain needs to contribute to an answer. Such multiagent settings may require multiple cycles. As an example, let us consider the query from an online movie shop When was the director of the movie Titanic born? This question involves two domains, which we refer to as Movie and Biography. Let us assume that these domains are given in advance. There are certain lexical units in the query that can serve as necessary conditions of the involvement of a particular domain. In our case, director (in any context) is linked with Biography, and movie with Movie.
The latter is expected to include information about movies: names of producers, directors, authors, actors, etc. The former contains the names and biographical data of well–known persons. As we see, the query links these two domains via the name of person: the same person, who was born, was the director of Titanic.
The system recognizes the latter domain using predicate movie (or predicate director, or the object titanic), and the latter domain, using predicate born. Note that predicate movie is unambiguous, but it does not necessarily occur in the query, while predicate director is unavoidable (would be explicitly mentioned in any query), but ambiguous (it could be present in the business domain as well). Domain pre–recognition can be based on the predicates and on their specific semantic types in case of occurrence in multiple fully formalized domains.
The important issue of multi–domain NL understanding is the sequence of query processing by each domain agent and the protocol of the result (current translation) exchange. In our example, for the first run, the output of the first agent is (director(X, titanic), X=j_cameron, X is a person) and that of the second one is (born(Y, D), Y is a person, D is year). Note that the agents’ outputs are formed as formal representations of query translations, which have been matched against the domain knowledge representation.
On the second run, the agents with partially uninstantiated predicates exchange their results. The second agent obtains the value for the first variable because it has a compatible (the same) semantic type. The first agent runs the resultant translation of a query director(j_cameron, titanic), born(j_cameron, D) against its knowledge representation to find the value(s) for D. Note that for each pair of predicates in a query translation there are either two equal variables or two variables linked by the constraint and expressed by the other predicates. In other words, each pair of predicates in a query translation formula is correlated. The multiagent system above was implemented using syntactic processing by (Katz, 1990), knowledge representation by the omnibase system (Katz, et al., 1999) and the semantic processor of the author.
We sketch the generic functioning algorithms of an agent, receiving and distributing currently obtained and satisfied query translations. Details on each step are dependent on the implementation of the linguistic processor and knowledge base and can be found elsewhere (e.g. Lenat and Guha, 1990; Hirst, 1988; Kiselj, 2001). We start with the case where there are no common predicates for distinguishing domains.
- Translate a query;
- Determine the knowledge sources for each predicate;
- Satisfy the translation formula (formal representation of a question);
- Obtain translations of the other agents and check the instantiated arguments of familiar semantic types;
- Perform additional instantiation of own translation with the foreign arguments;
- Satisfy the merged translation formula;
- Pass the satisfied translation formula to the other agents.
Indeed, the functioning of both meta–agent and agents in the multiagent environment needs to be more sophisticated. When there is a predicate belonging to more than one domain, an agent has to be able to match the foreign signatures (enumeration of predicate–specific semantic types of its arguments) for this predicate with its own signature. Besides, if more than one tuple (set) of objects satisfies a query, the search sequence (multiagent protocol) could be different for each tuple. For our example above, there are a number of movies named Titanic; each of them has its own director and his birth time [ 3]. If the biography database contains the records for each Titanic director, then the search is uniform. Otherwise, imagine that some directors are mentioned in cinematography bio database, and some are in the general biography database. Then the meta–agent is expected to be familiar with both knowledge sources and should independently determine the sequence of running the predicates of its translation formula against these sources.
- Translate a query, choosing the proper signatures of predicates (combinations of their semantic types);
- Determine the knowledge sources for each predicate;
- Satisfy the translation formula;
- Obtain the translations from the other agents and check the instantiated arguments of familiar semantic type. If there is a signature contradiction, formulate the signature hypothesis setting the correspondence between the own and foreign objects for the given semantic type;
- Reveal the contradicting values for the case of multiple occurrence of a predicate in own and foreign domains;
- Perform additional instantiation of own translation with the foreign arguments. Determine the sequence of search for each value of the object, obtained by a foreign agent.
- Satisfy the merged translation formula specifically for each obtained tuple of objects, satisfying the current translation formula;
- Pass the satisfied translation formula to the other agents.
Principal and accompanying agents
Any real–world domain is some combination of central topics (principle domains) and accompanying domains, helping to answer questions involving information not directly related to the central topics. The set of principle and accompanying domains (what we call agents from now on) is referred to as meta–domain. Particularly, in the meta–domain Family law we have the principle agents family & college, marriage & divorce, and wills & trusts. However, some questions to this meta–domain can be psychological or financial; therefore it is necessary to use additional psychological and financial domains. For example, the query How to file tax return after divorce, addressed to the Family law meta–domain, must involve tax knowledge. It seems reasonable to include some relevant tax knowledge into the divorce domain, but using the Tax domain itself is still required for some questions. It is very inefficient in terms of information redundancy, design reusability, and knowledge update viewpoints to incorporate rather "foreign" knowledge into each domain and to have portions of repetitive information in multiple domains.
Three–character code Agent name Domain source Domain size (questions/answers) IRS Main individual tax domain TeleTax topics 2,200/400 FRM Individual tax forms IRS references on how to fill forms 1,700/300 TIP Taxpayer’s tips Various Internet resources; E–mail with tax questions, submitted to TaxLogic, Inc. 400/100 SMB Small business tax Small business tax (IRS CD) 2,000/250 HRB Tax Topics, not addressed by the agents above E–mail with tax questions, submitted to H&R Block, Inc. 400/100 Table 1a: The agents for Tax meta–domain. See Figure 3 for the user interface to the Tax multiagent Q/A system. The reader may note that when we say that each domain is represented by an agent, we go far beyond just a software component with certain functionality. The agents that represent Q/A domains are capable of reasoning about the respective domain data (Wooldridge, 2000), forming mutual beliefs concerning knowledge of others, cooperating and resolving conflicts over which answer may be more relevant (involving the meta–agent).
Throughout this paper, we will be using examples from the Tax meta–domain, since it is one of the most complex domains for e–commerce Q/A (attracting customers to use online tax services).
Multiagent architectures deliver better domain coverage than single agent architectures, and optimize knowledge distribution between domains. To reduce the complexity of ambiguity resolution as a set of domains grows, semantically similar portions of knowledge are distributed between Q/A agents. These agents have the common domain environment (semantic types, overlapping set of predicates and values for their semantic types), but the domain information is presented from various perspectives. For some practical reasons [ 4], we have chosen the following coverage of tax knowledge ( Table 1a):
- the first agent knows the general data about taxes based on the publicly available TeleTax information;
- the second agent knows how to fill and file forms;
- the third agent provides longer answers for more specific topics;
- the fourth agent is responsible for small business tax;
- the fifth agent is designed to cover the rest of the topics, using the customer support database of H&R Block.
Distributed architecture allows us to generate better coverage of the domain, though the same information may be stored in several different viewpoints (to have more reliable coverage, redundancy to answers is unavoidable). For domain coverage robustness, it is fruitful to have multiple answers linked with the same concepts in a different manner in accordance to various domain scenarios. Since it is hard to separate these answers within a single agent, the solution is to distribute them between different agents. In terms of reliability of domain knowledge access, redundancy of answers within a multiagent system is better than within a single agent.
We proceed to the second suite of agents we have experience with, the legal ones. Legal domains require a multiagent architecture because it is capable of combining the heterogeneous sources of information from various areas of knowledge. Table 1b below enumerates the agents and their respective topics, which are different from each other to a much stronger degree than in the case of Tax agents: their content does not significantly overlap.
Three–character code Agent topic Domain size (questions/answers) FAM Family and college 2,200/400 DIV Divorce 1,700/130 WIL Wills and Trusts 400/100 PSI Psychology advice 1,300/150 IRA Retirement: IRA 2,000/250 K41 Retirement: 401(k) 400/100 Table 1b: The agents for the Family Law meta–domain. Principal (shown in bold) and accompanying agents, advising in this domain. Indeed, just DIV and WIL are the "pure legal" agents, others are financial and psychological advisers. The Tax and some legal meta–domains require multiagent architecture to a higher degree than other vertical domains, which include less complex and tightly interconnected topics. Note that the structure of the Tax multiagent system is different from the Family law one: the former is different coverage of the same topic, and the latter is the set of accompanying topics.
We outline the reasons a complex domain should be split into the subdomains in accordance to multiagent architecture.
- Splitting an extensive quantity of information into various agents supports Q/A accuracy. If answers are too semantically close to each other, then the likelihood of providing a slightly relevant answer instead of the exact one dramatically increases.
- Domain division with respect to viewpoints (or the way information is presented) and not with respect to addressed topics allows us to improve the expression of domain coverage. At the same time, this division gives us an ability to conceal the absence of certain knowledge by one agent, in case another agent is capable of providing the relevant answer.
- There are a series of development process advantages, when a domain is distributed between the knowledge engineers. It is very inconvenient to split a domain between knowledge engineers, so the multiagent architecture allows a single knowledge engineer to be responsible for a single agent, and the team is assigned to produce a domain.
- The multiagent approach increases system performance and scalability, when the agents reside in different processor units.
Design of the multiagent Q/A system
As we mentioned in the previous section, there are two architectures of content distribution between Q/A agents:
- Similar content is presented from the viewpoint of each agent;
- The content is extended by adding accompanying agents, where content overlaps insignificantly.
- Content is non–uniform with respect to degree of formalization, and is split accordingly to the Q/A (particularly, knowledge representation) mechanism.
Usually, if the knowledge sources distribution occurs because of different coverage (like in the Tax example), multiple agents for a given domain have the similar entity environment (signatures and semantic types) and are different with their semantic headers (combination of the entities). If a horizontal domain is comprised of multiple vertical domain agents, their signatures and semantic types have been designed optimally for respective portions of knowledge. Multiagent architecture is also tightly connected with the user interface.
There are a number of ways a customer may secure results from the multiagent Q/A system:
- The customer gets the first answer from the agent that has obtained a more specific (usually, a single) answer. The other agents may be initiated upon request (the areas of these agents are displayed). This approach is less time consuming and allows more control on the user side.
- The customer gets the first answer from the agent that has obtained a more specific answer or one with the highest confidence level. The other agents display the answer titles or abbreviated answers, which may be chosen for more details if the first answer is irrelevant.
- The customer gets one or two answers from the agents with the highest confidence level(s). The links to other answers are displayed with corresponding confidence levels. This approach allows higher control of the answers’ relevance, but has too much in common with the keyword search interface.
- All obtained answers are displayed (in the order of confidence levels) so that the customer first sees the enumeration of topics (titles) of these answers with references to their bodies.
Usually, specific domains and customer requirements determine the choice of a particular framework for the user interface. In any of these cases, the distributed architecture helps the customer to obtain more complete answers with higher relevancy without a loss of accuracy, and allows, if necessary, the application of manual choice to answer selection. Our experience shows that for simple questions, the right agent can deliver an appropriate answer quite frequently. The user takes advantage of the full–scale multiagent system functioning for complex queries, involving entities that may not be directly related to each other, where a single Q/A agent may be insufficient in any case.
When a domain is subject to the intense development, at a certain point the number of combinations is approaching the totality of all possible combinations of entities, and a pair of different answers may have close semantic headers [ 5]. Therefore, the domain becomes over–constraint (dense) and that decreases answer separation capabilities. It frequently becomes impossible to insert new answers, because their potential semantic headers are already assigned to existing answers. There are two ways to overcome the density problem: either to divide the set of semantic headers into two domains (agents) and keep development of both of them, or to start a new domain (agent) for additional answers.
To resolve the density problem, the splitting of a domain should occur, enforcing the migration of similar headers and their respective answers into different agents. It would not be helpful, from the density viewpoint, to split a domain into semantically close components (for example, to split the Tax domain into the property tax agent and sale of property agent), because each resultant agent would still be too dense. It is rather useful to choose two different perspectives from which to cover the domain and present knowledge, possibly about the same topic, from two different viewpoints. Therefore, knowledge engineers are encouraged not to avoid information redundancy when coding multiple agents about the same topic. For example, the Tax meta–domain is covered from a general perspective and from the perspective of filing tax forms (first two agents, Table 1a).
The difficulties of multiagent architecture are associated with the choice of the best answer in the case where the agents deliver multiple responses. One measure of an answer’s correctness (from the system’s perspective) is confidence level. Computation of the confidence level helps to decide which agent has delivered a more relevant answer, as well as to indicate the system’s own opinion of the relevancy of single agent domains. The confidence level is primarily determined by the complexity of the translation formula and by the degree to which it has been subject to attenuation to be satisfied by a semantic header (if this is the case). The confidence level is equal to the number of atoms of the translation formula.
The higher the number of atoms in the translation formula, the more specific is the expected answer, relative to the other agents; correspondingly, the confidence level increases. For simplicity, we assume that each atom in the translation formula has been matched by a "unique" atom in a semantic header (not by a corresponding variable). In other words, the estimate of the confidence level is based on the number of atoms assuming that each of them is under nonvar constraint in the target semantic header. For example, the confidence level of translation formula file(form, ira(distribution,_)) (IRS agent) is 4, and that of ira(distribution,form) is 3 (IRA agent does not know the word file and actually does not have to).
For multiple conjunctive members of translation formula, the confidence level averages through the members. Also, the higher the attenuation degree, the lower the resultant confidence level.
If the system is forced to find an additional atom to turn the translation formula into the satisfied one, the drop in confidence level reflects the degree that the choice of this atom is random. In our implementation, if an expression is subject to attenuation while deriving a satisfied translation formula, the confidence level drops below 1. Particularly, it is 0.5 if a predicate is found for its argument (for example appeal, extracted from a query with no words for predicates, is converted to audit(appeal,_)). The confidence level is 0.7 and 0.8 respectively if outer and inner atoms are replaced or added, irrespective of how many atoms in the formula.
We have observed the following relative to the functioning of meta–agent:
- Its complexity is determined by the context of a query. Therefore, the meta–agent does not perform domain pre–recognition or involve all assigned agents for any question.
- If a query indeed involves two domains then there is no algorithm to reasonably grade the answers of both agents, and both answers have to be provided. It seems to be very hard to logically distinguish which domain is addressed, if there are a pair of translation formulae provided by corresponding agents. If a customer does not exactly know from which domain advice should be derived, it is rather hard for the system to determine the right agent.
- There is a typical pattern of domain overlapping. If there is an intersection between domains, caused by a question, it usually lies in the center of one domain and at the boundary of another. We use some geometrical intuition in domain representation as a set of atoms. The central atoms are more frequent or, informally, more important ones.
We proceed to the issue of how agents (vertical domains) cover world knowledge. An interesting question is the topology of domain interdependence: if one develops a series of agents covering some large area of world knowledge, where would be the overlaps between areas?
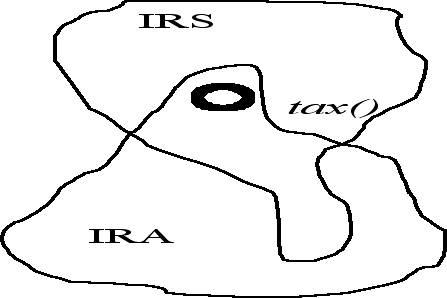
We performed a computational study of overlaps between agents in terms of the number of common lexical units. The normalized set of lexical units for each agent was built in financial and legal knowledge (normalization is required for the comparison of set elements). The normalization procedure also includes elimination of domaine–invariant lexical units (modal verbs, numbers, mental parameters, etc.). As a result we discovered that the lexical overlap between agents, which are "about the same," (for example, IRS and FRM) is 60 ±10 percent, and those who address different matters is 30 ±10 percent. These numbers seem to be quite surprising: one would expect them to be 80–90 percent for similar domains and 15–20 percent for different ones. Remarkably, we discovered that each pair of financial or legal domains is overlapped by the domain–specific terms. Note that the mentioned results were obtained using statistically sound data that is the result of thorough considerations of multiple knowledge engineers (see Figure 2).
Figure 2: The overlapping of two domains as sets with elements – atoms. Atoms, marginal for a domain, are likely to be central for another domain. For example, the concept of tax is marginal in the IRA domain, but evidently central in the tax domain (question What are the tax issues of IRA account while changing an employer: this question is rather about IRA (central concept) than about tax).
Evaluation of multiagent performance
In this section, we evaluate the functioning of a multiagent question answering system built around tax content. The system is intended to provide a financial advisory to attract customers to a tax portal for filing their tax returns using the site tools ( Table 2).
- Can I deduct expenses incurred when I visited a doctor?
- My doctor has ordered me insulin treatment. Can I deduct that cost?
- Is ship considered home?
- When do I need to file form 4952?
- How do I report the sale of property?
- What do I need to do if I’ve received Form 2439 from a regulated investment company?
- Where should I report profits from renting?
- When am I to use Schedule C–EZ (Form 1040) 2000 instead of Schedule C?
- How can I figure out my estimated tax?
- If I give my son a gift of $15,000, will I be heavily taxed?
- If I present somebody with a sum of money, does anybody need to pay taxes?
- If I give somebody a sum of money as a gift, will he be heavily taxed?
- Can I deduct car expenses?
- I am not a U.S. citizen; do I have to pay taxes?
- If my child is mentally challenged, are there any tax deductions we can take?
- How can I reduce my taxes?
- Whom can I claim as a dependent?
- Who can be considered dependent?
- What are the tax rules for earning money from a different country?
- If I use my phone for both business and personal use, how can I take the correct deductions?
- Tell me about home mortgage.
- When should I get a social security number for my infant?
- How should I show my foreign earnings?
- Are disability incomes taxable?
- Tell me about the rules for starting MSA.
- Should I pay any taxes for a car I won?
- Are tips considered part of my income?
- Can I rent an apartment and call it my second home?
Table 2: Sample questions to test multiagent functioning (See results in the Table 3 below).
FRM TIP K41 IRS MS2 IRA 1 + 4 + 2 - 0 + 4 -+ 3 -+ 2 2 -+ 1.5 + 2 - 0 +- 2 -+ 1 -+ 0.8 3 + 2 -+ 0.8 - 0 + 1 - 0 -+ 0.8 4 + 3 -+ 2 - 0 - 0 -+ 0.8 - 0 5 + 2.5 + 2 - 0 +- 2 -+ 0.8 -+ 0.7 6 + 3 -+ 0.8 -+ 1.5 -+ 3 -+ 0.8 -+ 2 7 + 4 + 2 - 0 -+ 0.8 - 4 -+ 0.7 8 + 5 - 0 - 0 -+ 0.8 -+ 3 - 0 9 + 1.5 + 2 -+ 1 + 1.5 -+ 0.8 -+ 0.8 10 + 3 + 2 - 0 -+ 2 -+ 0.8 -+ 0.8 11 -+ 0.8 -+ 0.8 -+ 2 - 0 -+ 0.8 -+ 0.8 12 -+ 0.8 + 2 - 0 + 2 -+ 0.8 -+ 1 13 + 3 + 2 - 0 -+ 2 -+ 2 -+ 0.7 14 + 0.8 +(-) 2 -+ 2 -+ 2 -+ 0.8 -+ 0.8 15 +- 6 +- 3 -+ 1 +- 2 -+ 0.8 -+ 1 16 + 2 -+ 0.8 - 0 +- 2 - 0 -+ 0.8 17 + 2 + 2 - 0 + 2 - 0 -+ 1 18 + 1 + 1 - 0 + 1 -+ 1.5 -+ 1 19 - 0 + 2 -+ 0 -+ 0.8 -+ 0.8 -+ 0.8 20 + 5 + 3 -+ 0 +- 2 -+ 0.8 2 21 + 2 + 2 - 0 -+ 1 -+ 0.8 -+ 0.8 22 +- 0.7 + 1 -+ 0.8 +- 1 +- 2.5 +- 1 23 -+ 0.8 + 1 - 0 + 2 -+ 2 -+ 0.8 24 -+ 0.8 + 2 - 0 + 2 -+ 2 -+ 0.9 25 - 1 + 1 - 0 -+ 0.8 -+ 0.8 - 0 26 +- 0.8 + 2 -+ 2 +- 3 -+ 0.8 -+ 0.8 27 + 2 + 1 - 0 + 1 -+ 0.8 -+ 0.8 28 - 0.8 +- 3 - 0 -+ 2 -+ 0.8 -+ 0.8 Table 3: Examples of functioning of the Tax multiagent system. Each column represents an agent (answer relevancy and confidence level), and each raw – a query. We use the following denotations to estimate an answer of a single agent.
+ correct answer: all necessary information available directly or via links, not too much additional irrelevant data; +- partially relevant: does not contain the direct answer, but has some information, useful to answer a query; -+ partially or absolutely irrelevant: the answer contains insignificant portion of knowledge, addressed by a query; - no answer; the answer, chosen by the meta–agent. In this section we present an example of a typical multiagent situation, when each agent is independently designed to handle its own content. The agents are combined to handle the TAX meta–domain, covering tax issues of investing in 401(k), IRA and mutual funds. We use three tax agents FRM, TIP, and IRS (see Table 2 above), 401(k) agent K41, mutual fund agent MS2 (MorningStar, Inc. content) and IRA agent IRA. Provided data was obtained before the system was finally adjusted to deployment at CBS MarketWatch and H&RBlock Web sites (Galitsky, 2001 and Figure 3).
We pose 28 randomly chosen tax questions (above) and analyze the competition between the agents for providing an answer. For each agent, we specify the actual correctness of an answer and its confidence level. For each question, we highlight the answer with the highest confidence level (the answer, actually delivered by the meta–agent). We are trying to avoid situations where the query context is wrongly recognized by the whole multiagent system: an answer by a foreign agent has the highest confidence level, and this answer is wrong (non–relevant). This situation occurs for questions 11, 14, and 18.
Figure 3: The user interface for the front end of e–commerce site of H&R Block, tax services provider, during year 2000 tax season. Advice was given to hundreds of thousands of H&RBlock’s customers until 2001. Currently, the generic tax system is available for demonstration at http://www.dcs.bbk.ac.uk/~galitsky/NL/book/ Ideally, if a question is foreign to the agent, it must return no answer or answers with low confidence level. For the majority of tax questions, the non–tax agents return confidence level below 1. This means that either no semantic header was successfully matched or it required attenuation of translation formula. In most situations, when the confidence level of foreign agents above is 1, the principal agents have the higher confidence levels. Exceptions from these rules deliver wrong answers: it happened for questions 11, 14, and 18.
For the used settings of the meta–agent, if there are two agents with the highest confidence level, the first one (on the left) delivers an answer. For the given meta–domain (as well as any meta–domain, involving more than three agents), it seems reasonable to provide two answers with the highest confidence level, making a shift in the answer size/probability of delivering correct answer balance. Note that all the queries above are within the Tax meta–domain.
Discussion
We have considered multiagent architecture for Q/A in poorly formalized domains earlier in this paper and demonstrated multiagent performance in the last section. Taking into account just the confidence level of each agent and reducing the interaction between them to a limited protocol is a simple yet efficient approach to multiagent Q/A. An alternative approach would be one where confidences are adjusted by asking auxiliary questions whose answers constrain the original answers; however, our user interface requirements do not allow these sorts of interactions.
To overcome the problem of obtaining a more robust answer in the multiagent environment, we build a model of multiagent interaction where Q/A is a result of resolving internal conflicts. Conflicts do occur since the translation formulae and resultant answers from different agents are inconsistent.
In various AI problems, conflicts among several agents within a multiagent system may arise from different reasons. For example, resource conflicts may occur when resources are limited or unavailable to all agents. In dynamic contexts, knowledge conflicts may be created by the incompleteness and uncertainty of the agents’ knowledge or belief. There may be differences in autonomous and heterogeneous agents’ skills and viewpoints that may generate conflicts if information secured by the agents are not comparable or if they come up with different answers to the same questions. Considering the last two cases, conflicts most often arise in the contexts where a unique standpoint has to be worked out, for example, situation assessment systems, multi–robot systems, intelligence systems, and decision aid systems. The focus of research on multiagent systems largely is based on conflict resolution via negotiation or constraint satisfaction.
We consider our Q/A agents as cognitive ones (having deductive abilities): they can represent objects, qualify them with properties, set out statements, and implement inferential processes. We enumerate the properties of ideal cooperative work among the agents:
- Common goal: the agents are only involved in the action of elaborating a common result (for instance, they do not try to manipulate each other and they are aware of that);
- Interaction capabilities: the agents understand each others language, the vocabulary is domain–limited and unambiguous;
- Obeying the protocol: different agents do not give their points of view at the same time;
- Observability: a current result (set of translation formulas) is available at each time either on a physical medium or using the task–independent clerk.
Q/A agents are not interchangeable (they have different points of view and get different information from their environment). From the multiagent settings perspective, these differences may allow a cooperative construction of knowledge to be achieved: conflicts hence are a means to go further than a mere concatenation of the agents’ initial knowledge bases.
Handling the context of a question
We use the concept of context on two levels: a context is a particular vertical domain (agent) in a multiagent system; also an entity exists within a context in a domain. In this section, we focus on the latter level. The meaning of a predicate (that represents an entity) is expressed via the set of all semantic headers including this predicate and only this set [ 6]. We remind the reader that semantic headers are formal expressions for answer annotations, which are matched with translation formulae. In accordance to the way semantic headers approximate textual knowledge, the meaning of a predicate is the set of those answers this predicate is able to separate, being instantiated with its attributes. An attribute (object) does not have an independent separate meaning; it forms a meaning when it is substituted into a particular predicate, reducing the set of answers for this predicate. The meaning for a pair of entities entering a translation formula is defined analogously as the set of answers this formula separates from the totality of other ones.
We define the contexts for an entity as a family of subsets of the set of answers for this entity ( Figure 4). These subsets are formed, taking into account the other domain entities. In accordance to our definition, attribute substitution does not change the context. It matches our intuition for a set of answers to be within a context from the prospective of a given entity. To approach the issue on how the contexts construct a domain, we state that domain answers are the union of all contexts for all entities. A domain is complete with respect to the context of its entities if any well–written formula from its atoms can be referred to a context [ 7].
Figure 4 depicts the contexts (sets of answers) for entity e1. The first (top left) context is derived using entity e1, the second – using entity e2. Note that the answers within a fixed context are distinguished by attributes a1 …a9.
We draw the comparison with the logical theory of contexts (Lenat and Guha 1990; McCarthy, 1993), more specifically – multidimensional context space. Their set of entities for a query fell into two categories:
- Entities pointing to the current context;
- Entities whose meanings are evaluated in that context.
In our case, the predicates for entities (1) are substituted into the metapredicates for entities (2). It is clear, that the categories (1) and (2) overlap in the general case. There is a pragmatic question: can one eliminate the entities of the first, but not the second category after the context has been determined, without affecting the translation semantics? As the computational evidence shows, it is not the case.
Figure 4: A set of answers; its subsets correspond to contexts. Naturally, the contexts (subsets) can overlap (not shown). Answers are associated with semantic headers (shown for some set elements). Contexts are determined by the entities (outermost in the semantic headers). Note that the other predicates may enter these semantic headers as conjunctive members. For the Tax domain, there is a traditional division of topics into enumerated contexts (so called "Teletax topics"). However, such division that is natural from the educational perspective is not very appropriate in terms of the uniqueness of the meanings in each context. The companion requirement for the context as a means to verify the formula validity poses the different principles for context creation as well.
Experience, accumulated while constructing the set of contexts for the general world knowledge (Lenat and Guha, 1990; McCarthy, 1993; Buvac, 1996), is found to be hardly appropriate for a narrow domain, where the general dimension of the domain space is significantly reduced and modified in accordance to domain specific features. It is very important for practical applications to relate the set of contexts to a domain; the logical definition of context by means of lifting the operator is insufficient for NL processing before the query translation is completed.
The context dimension can be defined (via connectedness) as the number of sets of predicates, irrelevant to the totality of other predicates. Context dimension can be naturally revealed based on the semantic types; two distinguishing dimensions cannot have inclusive semantic types. Besides, some context dimension can be associated with some order on the values of their arguments. In particular, highlighting of mental and non–mental (physical) dimensions brings in the powerful method of describing multiagent interactions in various physical worlds. The deductive means of mental and physical dimensions are very different; this fact strongly affects the reasoning machinery of the multiagent system (Galitsky, 2001). Division into order–based dimensions (temporal vs. spatial, points vs. fragments, etc.) is always necessary for correct domain representation. There are additional criteria for the utility of a dimension:
- Successful separation of mutually-irrelevant portions of knowledge from each other.
- Possibility to determine the intersections and unions of the dimension’s fragments.
- Division of large portions of knowledge into portions in accordance to the dimension’s fragments.
Points and fragments (especially critical ones) of a dimension correspond to semantically sound and familiar real–world entities and considerations.
There is a link with our semantically and pragmatically–accented deterministic approach to the statistical view of linguistic context (Zhai, 1997). Several heuristics approaches have been suggested to investigate linguistic context to identify lexical atoms from arbitrary NL text. We believe the technology of semantic headers can become more efficient when this operation is automated.
Our notion of context has rather static than dynamic, rather set–theoretic than reasoning or operational semantic nature. It reflects the fact that the problem of context management is resolved in this study while domain coding, and not in the process of real–time question answering.
How can we alternatively define the notion of context, when the setting of domains and subdomains has been established? Domains are distinguished based on informal, pre–formalized knowledge about their content, in spite of the fact that they can be identified based by a set of entities. On the contrary, contexts are the post–formalization divisions of domain knowledge, based on the formal expressions in the domain–specific language. It is very important for practical applications to relate context to a domain; the logical definition of context by means of lifting operator is insufficient for NL processing before the query translation has completed.
The context dimension is then defined as the set of predicates, irrelevant to the totality of other predicates. Context dimension is naturally revealed based on the semantic types; two distinguishing dimensions cannot have inclusive semantic types. Besides, some context dimension can be associated with some order on the values of their arguments.
In particular, highlighting of mental and non–mental (physical) dimensions brings in the powerful method of describing multiagent interactions in various physical worlds. The deductive means of mental and physical dimensions are very different; this fact strongly affects the reasoning machinery of multiagent system (Galitsky, 2001). Division into order–based dimensions (temporal vs. spatial, points vs. fragments, etc.) is always necessary for correct domain representation. The following is the additional criteria for the utility of a dimension:
- Successful separation of mutually–irrelevant portions of knowledge from each other.
- Possibility to determine the intersections and unions of the dimension’s fragments.
- Division of large portions of knowledge into portions in accordance to the dimension’s fragments.
- Points and fragments (especially critical ones) of a dimension correspond to semantically sound and familiar real–world entities and considerations.
Conclusions
As we have seen, multiagent implementation is adequate for NL Q/A systems, where the sources of knowledge are quite heterogeneous. It allows us to dramatically increase the robustness and relevancy for Q/A in a rather extensive domain. Indeed, the multiagent approach imitates Q/A in a horizontal domain, providing answer accuracy inherent to thoroughly developed vertical domains.
We choose multiagent architecture to move beyond answering the "pure" inner–domain questions: division of world knowledge into domains is conventional and may not fit user intuition. An agent cooperates with other agents in the sense of sharing a degree of confidence that an agent has actually understood a question and has found it relevant. This cooperation occurs under the control of the meta–agent.
It is worth illustrating Q/A architecture using an analogy with human agents. If a person is looking for advice, it is reasonable to consult multiple individuals, to obtain multiple opinions. Usually, real–world human agents have varies, and it is frequently impossible to tell in advance which agent is better to approach with a question. It is even better to allow these human "Q/A" agents to discuss with each other optimal answers, taking into account their respective confidence of answer relevancy. The architectural technique developed mainly for real–time reasoning systems, named experts sitting round a blackboard, is a good approximation of the coordination of activities for a number of agents (Erman and Lesser, 1975).
Multiagent implementation of Q/A is tightly connected with the notion of the context of an entity that appears only in semantic–based systems. We believe that context machinery is helpful when we are able to yield a meaning of an expression (given a predicate and its attribute) versus pure keywords with just individual meanings.
Our study provides an estimate of the complexity for a set of contexts of a real–world Q/A domain. The NL understanding technique is required to process up to four entities per query. Advanced semantic analysis with generality control (Galitsky, 2001) and expressive formal predicate language, extended with meta–predicates for knowledge representation and query translation, are sufficient to represent legal, financial, biological, and medical domains (Galitsky. 2002). A logical programming approach allows the expression of a sufficient number of contexts for an entity. This number exceeds 30 for the entities central to a domain.
As we discovered, more than 15 percent of irrelevant answers in a vertical domain occur because a user poses a question that involves foreign knowledge (that is, the query exceeds the domain bounds). Commercial evaluation of multiagent question answering demonstrated that this percentage can be reduced to six percent by the deployment of accompanying domains, using multiagent architecture. A reduction of incorrect answers is possible by involving more agents and improving the meta–agent functionality.
Horizontal question answering systems cannot provide as deep and accurate question answering as multiagent ones, incorporating numerous domains. Particularly, AskJeeves has less than 50 answers (or links) concerning tax topics. At the same time, the present approach delivers more than 2,000 answers on tax and associated topics. It is hard to imagine how a fully formalized "single–agent" ontology like CYC (Lenat and Guha, 1990) can represent and, furthermore, provide NL access to complex financial, business, or legal knowledge. Heterogeneous architecture — able to combine various data sources with deep analysis — is necessary for NL Q/A adapted to e–commerce sites.
A hybrid multiagent system with democratic architecture is an alternative to our approach. A multi–strategic and multi–source approach to Q/A, based on combining results from different answering agents searching for answers, has been suggested by Chu–Carroll, et al. (2003). These answering agents adopt fundamentally different strategies, one utilizing primarily knowledge–based mechanisms while another adopts statistical techniques. A multi–level answer resolution algorithm is presented that combines results from the answering agents at the question, passage, and/or answer levels. Experiments evaluating the effectiveness of the answer resolution algorithm show a 35 percent relative improvement over the baseline system in the number of correctly answered questions.
Since we have already built a wide spectrum of question answering domains, we are suggesting a reusable generic NL Q/A application and we believe it will be useful for any novel domain. The reader is advised to visit http://www.dcs.bbk.ac.uk/~galitsky/NL/book/.
About the authors
Boris Galitsky is a lecturer at the School of Computer Science and Information Systems at Birkbeck College, University of London, and CTO of Knowledge–Train, Inc.
Web: http://www.dcs.bbk.ac.uk/~galitsky
E–mail: galitsky [at] dcs [dot] bbk [dot] ac [dot] ukRajesh Pampapathi is a PhD student at the School of Computer Science and Information Systems at Birkbeck College, University of London.
Web: http://www.dcs.bbk.ac.uk/~rajesh/
E–mail: r [dot] pampapathi [at] dcs [dot] bbk [dot] ac [dot] uk
Notes
1. Particularly, using WordNet of Miller (1995), see also www.askjeeves.com, www.answerlogic.com, www.iPhrase.com, Harman (1996), and Lenat and Guha (1990).
2. See, for example, Fain and Rubanov (1995).
3. According to the Internet Movie Database, at http://www.imdb.com/, there are at least seven movies named exactly Titanic, appearing in 1915 (directed by Pier Angelo Mazzolotti), 1929 (directed by Ewald André Dupont), 1943 (directed by Werner Klingler and Herbert Selpin), 1953 (directed by Jean Negulesco), 1984 (directed by Lutz Büscher), 1993 (directed by Ray Johnson), and 1996 (directed by Robert Lieberman). Additionally, according to the Internet Movie Database, there are an additional 54 movies with Titanic as part of the movie title.
4. Specificity of knowledge sources; see Galitsky (2003).
5. Semantic headers are considered close if they are distinguishing by var/nonvar backtracking control; for example, one is the partial case of another.
6. Compare with traditional notions, e.g. Hirst (1988); Partee, et al. (1990); and, Keselj (2001).
7. We call a domain complete if it assigns each well–written formula with an answer.
References
V. Akman and V. Surav, 1996. "Steps toward formalizing context," AI Magazine, volume 17, number 3, pp. 55–72.
P. Bonzon, 1997. "A reflexive proof system for reasoning in contexts," Proceedings of the Fourteenth National Conference on Artificial Intelligence (AAAI–97), Providence, R.I.
P. Brezillon, C. Gentile, I. Saker, and M. Secron, 1997. "SART: A system for supporting operators with contextual knowledge," Proceedings of the International and Interdisciplinary Conference on Modeling and Using Context (CONTEXT–97), Rio de Janeiro, Brazil, pp. 209–222, and at http://www-poleia.lip6.fr/~brezil/Pages2/Publications/CONTEXT-97/index.html, accessed 30 December 2004.
S. Buvac, 1996. "Quantificational logic of context," Proceedings of the Thirteenth AAAI Conference Menlo Park, Calif., and at http://www-formal.stanford.edu/buvac/quantificational-logic-of-context.ps, accessed 30 December 2004.
J. Chu–Carroll, K. Czuba, J. Prager, and A. Ittycheriah, 2003. "In question answering, two heads are better than one," Proceedings of the HLT–NAACL, pp. 24–31, and at http://acl.ldc.upenn.edu/N/N03/N03-1004.pdf, accessed 30 December 2004.
L.D. Erman and V.R. Lesser, 1975. "A multi–level organization for problem solving using many, diverse, cooperating sources of knowledge," Proceedings of IJCAI–75, pp. 483–490.
V.S. Fain, and L.I. Rubanov, 1995. Activity and understanding: Structure of action and orientated linguistics. River Edge, N.J.: World Scientific.
B. Galitsky, 2003. Natural language question answering system: Technique of semantic headers. Adelaide, South Australia: Advanced Knowledge International.
B. Galitsky, 2002. "A tool for extension and restructuring natural language question answering domains," Proceedings of the 15th International Conference on Industrial and Engineering, Applications of Artificial Intelligence and Expert Systems: Developments in Applied Artificial Intelligence, Lecture Notes In Computer Science, volume 2358, pp. 482–492, and at www.dcs.bbk.ac.uk/~galitsky/pdf/iea02galitsky.pdf, accessed 30 December 2004.
B. Galitsky, 2001. "Semi–structured knowledge representation for the automated financial advisor," In: Laszlo Monostori, József Váncza and Moonis Ali (editors). Engineering of Intelligent Systems, Proceedings of the Fourteenth International Conference on Industrial and Engineering Applications of Artificial Intelligence and Expert Systems, IEA/AIE 2001, Budapest, Hungary (4–7 June), Lecture Notes In Computer Science, volume 2070, pp. 874–879, and at www.dcs.bbk.ac.uk/~galitsky/pdf/galitskyIEA01.pdf, accessed 30 December 2004.
D.K. Harman (editor), 1996. The Fourth Text REtrieval Conference (TREC-4). National Institute of Standards and Technology (NIST) Special Publication, 500–236. Gaithersburg, Md.: U.S. Dept. of Commerce, National Institute of Standards and Technology, at http://trec.nist.gov/pubs/trec4/t4_proceedings.html, accessed 30 December 2004.
G. Hirst, 1988. "Semantic interpretation and ambiguity," AI, volume 34, number 2, pp. 131–177.
B. Katz, 1990. "Using English for indexing and retrieving," In: P.H. Winston and S.A. Shellard (editors). Artificial intelligence at MIT: Expanding frontiers. volume 1. Cambridge, Mass.: MIT Press.
B. Katz, D. Yuret, J. Lin, S. Felshin, R. Schulman, A. Ilik, A. Ibrahim, and P. Osafo–Kwaako, 1999. "Integrating Web resources and lexicons into a natural language query system," IEEE International Conference on Multimedia Computing and Systems, volume 2, pp. 255–261.
V. Keselj, 2001. "Question answering using unification–based grammar," In Proceedings of the Fourteenth Biennial Conference of the Canadian Society on Computational Studies of Intelligence: Advances in Artificial Intelligence, Lecture Notes In Computer Science, volume 2056, pp. 297–306.
D. Lenat and R. Guha, 1990. Building large knowledge–based systems: Representation and inference in the Cyc project. Reading, Mass.: Addison–Wesley.
J. McCarthy, 1993. "Notes on formalizing context," Proceedings of the Fifth National Conference on Artificial Intelligence, and at http://www-formal.stanford.edu/jmc/context3/context3.html, accessed 30 December 2004.
G. Miller, 1995. "WordNet: A lexical database for English," Communications of the ACM, volume 38, number 11 (November), pp. 39–41.
B.H. Partee, A. ter Meulen, and R.E. Wall, 1990. Mathematical methods in linguistics. Dordrecht: Kluwer.
M.J. Wooldridge, 2000. Reasoning about rational agents. Cambridge, Mass.: MIT Press.
C. Zhai, 1997. "Exploiting context to identify lexical atoms – a statistical view of linguistic context," Proceedings of the International and Interdisciplinary Conference on Modeling and Using Context (CONTEXT–97), Rio de Janeiro, Brazil, pp. 119–129, and at sifaka.cs.uiuc.edu/czhai/pub/ctxt1997-lexatom.pdf, accessed 30 December 2004.
Editorial history
Paper received 8 November 2004; accepted 10 December 2004.
HTML markup: Christopher Day and Edward J. Valauskas; Editor: Edward J. Valauskas.


This work is licensed under a Creative Commons License.