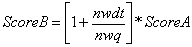The Web is continuing to grow rapidly and search engine technologies are evolving fast. Despite these developments, some problems still remain, mainly, difficulties in finding relevant, dependable information. This problem is exacerbated in the case of the academic community, which requires reliable scientific materials in various specialized research areas.We propose that a solution for the academic community might be a meta–search engine which would allow search queries to be sent to several specialty search engines that are most relevant for the information needs of the academic community. The basic premise is that since the material indexed in the repositories of specialty search engines is usually controlled, it is more reliable and of better quality.
A database selection algorithm for a specialty meta–search engine was developed, taking into consideration search patterns of the academic community, features of specialty search engines and the dynamic nature of the Web.
This algorithm was implemented in a prototype of a specialty meta–search engine for the medical community called AcadeME. AcadeME’s performance was compared to that of a general search engine — represented by Google, a highly regarded and widely used search engine — and to that of a single specialty search engine — represented by the medical Queryserver. From the comparison to Google it was found that AcadeME contributed to the quality of the results from the point of view of the academic user. From the comparison to the medical Queryserver it was found that AcadeMe contributed to relevancy and to the variety of the results as well.
Contents
Introduction
Related studies
Methodology
Findings and discussion
An algorithm for a specialty meta–search engine
Evaluation of AcadeME
Further research
Introduction
The Web is continuing to grow rapidly and has become a unique retrieval base for a large portion of the world’s population. This includes members of the academic community who use the Web to locate scientific and research materials to serve their information needs. Search engine technologies are evolving fast as well. There are three main types of search engines:
- Crawler–based search engines, such as Google and Altavista, which use programs that crawl the Web and create search engine indices.
- Web directories, such as Yahoo, which depend on humans for their hierarchical listings.
- Meta–search engines, such as Metacrawler and Vivisimo, which submit queries, in parallel, to several other Web search engines and display the search results to the user, usually after merging and ranking them in a single list. These may be thought of as second-generation search engines (Hanani and Frank, 2000).
Search engines — both crawler–based search engines and directories — can be further classified into two subcategories according to subject coverage: general search engines that cover a wide range of topics, and specialty search engines whose repositories focus on a particular field or topic, a target audience or a specific media type (Hanani and Frank, 2000). Because of this specialization, they often offer greater depth of coverage for a category than the general–purpose search engines. Because they are small relative to the general–purpose search engines they are often more reliable and stable (Sherman and Price, 2001).
Examples of specialty search engines are: LawCrawler- a legal search engine; PsycCrawler — a search engine specializing in psychology; Healthfinder — a medical search engine; Searchedu — a specialty search engine devoted to university and education–related Web sites; and, Search Adobe PDF Online — a search tool for articles in PDF format.
Despite the development of these search technologies, some problems still remain, mainly, difficulties in finding relevant, reliable information (Greenspan, 2002; Bedell, et al., 2004; Allen, et al., 2002; Berland, et al., 2001).
Search engines do not provide comprehensive coverage of the Web. Their crawlers simply cannot keep up with the explosive pace of Web growth. Crawling is an expensive operation. Therefore search engines limit the total number of pages in their indices as well as the frequency of re–crawl (Sherman and Price, 2001).
There is also the “Invisible Web,” often referred to as the “Deep Web.” The Invisible Web consists of high–quality authoritative information available via the Web, which general–purpose search engines cannot locate because of imposed technical limitations, or which they deliberately exclude from their indices because of resource problems. The largest portion of the Invisible Web consists of high–quality information for the academic community stored in Web accessible databases. The content in most of these databases is accessible by direct interaction with them. Regular crawlers solely designed to request and fetch Web pages cannot fill out the required fields in the interactive forms of these databases and therefore cannot retrieve information from them (Sherman and Price, 2001).
Another aspect of the Invisible Web is high–quality information for the academic community stored in certain types of formats such as PDF and postscript, in which most scholarly papers are posted to the Web. These formats are hard to index, requiring additional computing resources. General search engines intended to meet the needs of the general population preferred not to waste the time and expense of indexing files in this format (Sherman and Price, 2001). Recently, general search engines have been changing their policy about which formats to index and some of them have added PDF files and other file formats to their indices. Yet, policies vary on which non–HTML file formats to index. Moreover, general search engines dedicate portion of their results to commercial links and their search results are being manipulated to a certain degree by commercial Web sites (Spring, 2004). Consequently, the general problem of difficulties in finding relevant, reliable information on the free Web is exacerbated in the case of the academic community, which requires such materials in various specialized research areas.
Gelernter (2003) recommended turning to specialty search engines in order to delve deeper into relevant sites or to achieve better concept searches. She claimed that specialty search engines perform what most general engines cannot: extend the limits of Google.
Indeed, theoretically, specialty search engines can better meet the needs of the academic community. Because they focus on specific sources of information, specialty search engines often offer greater depth of coverage for the specific subject area than general search engines. They can also offer pages and file formats in which scholarly pages are stored and which could have been included in the general search engine indices but, as noted, are often deliberately excluded. Because they tend to have smaller repositories than general search engines their material is usually controlled, and hence is more reliable, and of better quality. They also tend to be updated more frequently than general search engines (Sherman and Price, 2001).
Yet, these specialty search engines have some drawbacks for the searcher. Apparently, most of them remain unknown to the majority of the population. Even if users are acquainted with them, they encounter many problems, particularly low recall since most of the specialty search engine repositories are small, requiring users to move from one search engine to another. They therefore need to know which ones to use and how to manage the different interfaces, whereas they would obviously prefer a single search engine.
In light of this situation, we propose that a solution for the academic community might be a meta–search engine that would allow search queries to be sent to several specialty search engines that are most relevant for the information needs of the academic community. A specialty search engine for this purpose is defined in this research in two ways:
- A focused directory or targeted crawler that provides access to material on a specific subject or domain from material found on the Web
- A "chunk" of a general search engine focusing on a certain subject area or domain with content often accessible through a specialized interface.
A Web site or a database with a search engine are excluded from this definition.
A specialty meta–search engine would utilize the advantages of both specialized search engines and meta–search engines, while minimizing their shortcomings for the searcher. Submitting queries to multiple specialized search engines simultaneously solves for the searcher the problem of not knowing the appropriate search engine for a particular topic and its URL, and that of learning its interface.
Through an independent relevance mechanism a specialty meta–search engine can enhance search precision and its meta feature can improve recall (i.e., retrieve more of the relevant results). Because of its specialized input it can search a greater portion of the Visible and Invisible Web, utilizing the specialized search engine potential to search particular specialized categories in greater depth, and to search a greater portion of the technically indexable Invisible Web.
Furthermore, due to its meta feature — submitting queries to other search engines using forms — it also has the potential to search the truly Invisible Web, i.e., information stored in rational databases which cannot be extracted without a specific query to the database, a task that general search engine robots cannot do (Sherman and Price, 2001). Consequently, a search engine of this type for the academic community would be user friendly and more efficient in terms of precision recall and quality of results.
To demonstrate the capabilities of this approach and confirm the main thesis that a specialty meta–search engine would contribute to the academic community in finding relevant quality materials, a prototype of a specialty search engine was developed.
In developing an appropriate model for a specialty meta–search engine suitable for the academic community, the search patterns of the academic community were first analyzed. The purpose of this analysis was to confirm the need for a specialty search engine and to identify the information behavior of this community. This is very important since identification of information needs and information behavior of specialty groups of users enables the development of efficient information systems tailored to these groups (Gaslikova, 1999).
In order to arrive at appropriate conclusions about the specialty meta–search engine, features of specialty search engines regarding retrieval effectiveness — precision, recall, overlap, and retrieval problems — were then identified.
The unique retrieval environment of the Web was taken into consideration as well, especially its dynamic nature coupled with its continuous rapid growth (Bharat and Broder, 1998; Gray, 1996; Lawrence and Giles, 1999; O’Neill and Lavoie, 2000), and the instability of its pages (Germain, 2000; Koehler, 1999, 2002; Bar–Ilan and Peritz, 2004). The conclusions were implemented in an algorithm for a specialty meta–search engine and, after developing a medical prototype AcadeME which illustrates the use of this algorithm — its performance was evaluated.
Hence, there were four stages in the research:
- Locating search engine use patterns of the academic community.
- Identifying the features of specialty search engines. This stage included a sub–stage of identifying relevant specialty search engines and storing their details in a special repository.
- Developing an algorithm for a specialty meta–search engine.
- Evaluating AcadeME — the specialty meta-search engine.
This article reports on these four stages, concentrating on issues relating to specialty search engines in general and on an evaluation of the algorithm and prototype developed, in particular, in order to confirm the main thesis that a specialty meta–search engine would contribute to the academic community in finding relevant quality materials. Analysis of precision failures played an important part in evaluation of the search engines in all the relevant research stages.
Related studies
The number of published studies focusing specifically on specialty search engines (as defined in this research) is surprisingly small, and they are more descriptive than empirical. Related studies deal usually with one search engine. In the latter group the research examines Deadliner — a specialty search engine that catalogs conferences and workshop announcements (Kruger, et al., 2000) and other studies describe techniques of various specialty crawlers (Chakrabarti, et al., 1999; Ding, et al., 2000; Glover, et al., 2001; Kleinberg, 1998; Lawrence and Giles, 1998; Lawrence, et al., 1999; Shakes, et al., 1997).
Since no comparative studies were found, it seems that those relating to specialty search engine are still in their initial stages. Moreover, it seems that most of the specialty search engines are first–generation search engines, and second–generation search engines, i.e., specialty meta–search engines, do not yet occupy a particular niche on the Web. No study describing a specialty meta–search engine, as was defined in this research, was found. Moreover, only a few referred in general to this topic and all in a marginal manner (Craswell, et al., 2000; Steele, 2001).
Other studies such as that of the aforementioned Gelernter (2003) deal theoretically with specialty search engines.
Our research has tried to verify empirically the aforesaid claims concerning specialized search engines and a meta–specialty search engine.
Methodology
Each stage will be presented in a separate subsection since the research methods differed.
Search patterns of the academic community
Our analysis of search engine use patterns covered four fields of research: medicine, life sciences, nursing and computer sciences. The focus of the hypotheses in this part of the research was on search patterns that could highlight the need for a specialty search engine, and its desired features in relation to interfaces, repositories and the ranking algorithm.
The following independent variables related to population characteristics were examined in this research:
- “Discipline&” — a nominal variable consisting of four categories: computer science, life sciences, medicine and nursing.
- “Academic status” — a nominal variable consisting of five categories: first degree student, second degree student, third degree student, academic staff and “others.”
- “Role” — a nominal variable consisting of three categories: research, teaching and "other.
- “Age”
- “Gender”
- “Computer literacy,” “Internet literacy” and “search engines literacy.” These variables are self–evaluation of competence with these systems.
- “Internet experience” and “search engines experience”
- Perceived user–friendliness of Internet and search engines.
- Perceived Internet and search engines efficiency.
- Information about search engines.
The dependent variables examined in this research were a group of variables related to search patterns:
- Variables related to “Internet and search engines use for general, research and teaching purposes.” These variables were measured by the number of monthly search sessions.
- The preferred search engine.
- Use of specialty search engines.
- How many search engines are used in a single search.
- Success in using search engines. Here, two variables were applied: I. “How many times, in general, the user found what he was searching for:” 100%, 90%, 80%, 70%, 60%, 50%, 40%, 30%, 20%, 10% and 0%. II. Last search success was measured according to five–point scale of search results ranging from a “very successful” to “I did not find relevant material.”
- “Requested materials in the Internet” — a nominal variable consisting of 12 categories: “research articles,” “conferences,” “Web sites of colleagues,” “various reference materials” such as encyclopedias and dictionaries, “libraries,” “search engines,” “sites of organizations,” “guide materials for scientific writing,” “addresses and phone numbers,“ “listservs and news groups,“ “free e–mail sites,” “others.”
- Material age (frequency of document update). An ordinal variable consisting of five categories: “current year,” “last three years,” “ten years,” “archive documents” and “the question of updating is not important to me.”
- (The material language) Choice of language. A nominal variable consisting of three categories: Hebrew, English and others.
- Subjects and topics searched. An “open” question. Users were asked to list topics they wished to find on the Internet.
- The search language. Use and perceived importance of the different search options:
“simple search,” “Boolean search,” “the modifier plus,” “the modifier minus,” “natural language,” “the proximity operator near,” “quotation marks with phrase,” “limiting the search by various fields,” “the refine technique,” “the truncation technique,” “the help system.”- The preferred search interface — A dichotomous nominal variable represented by two categories: “a form permitting a free search” known as “basic search” and a form, usually known as “advanced search,” for performing a structured search using predetermined language in a user fill–in template.
- Number of checked results.
- Using the same queries at different times for receiving updates.
The variables relating to use patterns were investigated at the univariate, bivariate and multivariate level. The main hypotheses at the univariate level were:
“much search engine use is for research purposes,” “general search engines are the most used and specialty search engines are unknown,” “most users utilize only one or two search engines in a single search,” “most search options are not used,“ “the number of search engine results checked is small,” and “success in search engine use is reasonable but there is still much to be done.”At the bivariate and multivariate level, the correlation between user characteristic variables (as independent variables) and search patterns (as dependent variables) was examined. The independent variables examined can be classified into two main categories: cognitive personal variables and discipline variable. The goal was to discover whether a specialty meta–search engine requires unique features for each discipline or whether its features could be common to all disciplines. Ten models (Multiple linear regression models/Logit models) dealing with various search patterns were investigated: “search engines use for general purposes,” “for research” and “for teaching purposes,” “use of various materials,” “the desired material language,” “the search language,” “the preferred search interface,” “using the same queries at different times for receiving updates,” “the desired material age,” and “the number of checked results.” Based on prior work in use studies it was hypothesized that two groups of variables — personal cognitive variables (Ables, et al., 1996; Tillotson, et al., 1995; Chu, 1994; Kaminer, 1997; Kraut, et al., 1996; White, 1995; Katz and Aspden, 1997; Morahan–Martin, 1998) and the discipline variable (Ables, et al., 1996; Lazinger, et al., 1997; Ray and Day, 1988) would be correlated at different levels with the various use patterns.
Data collection was done by a survey and by Transaction Log Analysis (TLA). The study began with a pilot study conducted on 30 users of the library of life sciences and medicine at Tel Aviv University, and five computer science students. The pilot study version of the questionnaire was revised and was then used for the research survey. The survey was conducted in the period June 2001–March 2002 among 600 random users at Tel Aviv University in the following fields of research: medicine, life sciences, nursing and computer science and at different academic levels. An original detailed questionnaire examining all the related variables was sent by e–mail, by regular mail and was also distributed in the classrooms.
The TL recorded the actual searching for information using search engines.
Unlike questionnaires, log files record user behavior simultaneously with user interaction with the system. Hence, use of the TLA research method contributed to the validity and reliability of the research findings. Results were analyzed statistically using SPSS and Stata.
Performance of the specialty search engines
In this second stage of evaluating the performance of seven specialty search engines, a comparative study was conducted. Its goal was to compare the performance of the seven specialty search engines selected for input to the specialty meta–search engine, in order to arrive at appropriate conclusions regarding an algorithm for the specialty meta–search engine.
The main features of these specialty search engines were investigated by conducting 106 queries in each search engine and evaluating the results using the relative recall [ 1], precision and F measure (the weighted harmonic average of recall and precision) for evaluation. Classical dichotomous relevance judgment (relevant or not relevant) was applied and the mean precision score of each search engine was computed.
The queries were real ones taken from the log file or reported by the users in the questionnaire. The results were evaluated by the investigator. An independent judge also checked twenty percent of the results for reliability. The search results were stored in a Microsoft Access database and the evaluation was done without knowing which search engine provided which results (The evaluation was done using Access forms. The name of the search engine didn’t appear in the form).
Relevance was regarded as topical, standing for “aboutness” (Mizzaro, 1997), but the relevance judgment was made from the point of view of academic information needs. We preferred this batch–mode of laboratory tests, i.e., the traditional system–oriented approach over the cognitive, behavioral user–oriented IR (information retrieval) approach (Harter and Hert, 1997; Bruijn, et al., 1999) — in which a real user with an information need interacts with the system — because this paradigm seemed to best suit our objective which was system design. User–oriented studies, on the other hand, seem to be directed at modeling the user’s search behavior (Spink, et al., 1998). Moreover, by adapting this batch–mode, we tried to avoid some drawbacks of the user–oriented approach, such as problems in assessing relevance (Vakkari and Sormunen, 2004) and the problem of search strategy, which can differ from user to user and cause retrieval failures and difficulties in attaining significance in quantitative results due to the fact that experiments tend to be very limited in scope or scale (Bruijn, et al., 1999).
Another challenging aspect of the evaluation is an analysis of search failures (Lancaster, 1969). The possible causes for precision failure (i.e., retrieval of irrelevant items) played an important part in this evaluation and contributed to identifying ways for further improvement of the performance of the specialty meta–search engine.
The failure analysis was performed by using an inductive strategy, i.e., each item was checked for relevancy and if it was found to be irrelevant the particular cause for the precision failure was identified. Then all the precision failures were classified into categories (see results section).
The overlap among the results of the seven search engines was investigated as well.
The main hypotheses relating to specialty search engines performance were:
- Most specialty search engines may suffer from low recall due to their small repositories. A meta–search engine that would use a number of search engines from the same domain could handle the recall problem efficiently.
- Specialty search engines may suffer from precision problems as well due to software and algorithm problems. A specialty meta–search engine with an independent relevance mechanism could handle precision problems as well.
Evaluation of AcadeME
The evaluation of AcadeME was conducted by comparing it to a general search engine — Google — and to a single specialized search engine — the medical Queryserver. Google was chosen to represent the general search engines because it was reported as the most preferred search engine by 45.2 percent of the research population in this study and is a highly regarded search engine. Queryserver was chosen to represent the specialty search engines mainly because it was one of the input search engines for AcadeME and the declared sources it uses for its results are reliable; thus the variable “quality of results” might be held constant. Since the emphasis was on the relevancy of the results, the contribution of AcadeME with its relevance mechanism could be assessed.
The comparison between Google and AcadeME was done by submitting the same 50 queries to each search engine, following the links of the top ten results of each query, and evaluating each site. The evaluation was conducted by the investigator. An independent judge also checked twenty percent of the results for reliability. The search results were stored in a Microsoft Access database and the evaluation was done without knowing which search engine provided which results (The evaluation was done using Access forms. The name of the search engine didn’t appear in the form).
The queries were real queries taken from the log file or reported by the users in the questionnaire and a relevance judgment was made from the point of view of academic information needs.
Several kinds of relevance judgment expressions were used. First a classical dichotomous relevance judgment (relevant or not relevant) was applied and the mean precision score of each search engine computed. In addition, a weighted scalar judgment using a three–level relevance scale was used. The degree of relevance was operationalized in the following categories:
- “Not relevant at all.” Pages not containing any information about query topic were deemed not relevant, even if they contained marginal information connected to some of the query terms. Dead links and copy pages (same content and same URL) were included also in this category, since the user is certainly not interested in such links, whereas mirror pages, which contain the same information, but have a different URL were counted as ordinary pages. Error reports, such as a non–existent page or no response, were also included in this category. Pages that were technically well retrieved but were irrelevant to the academic user were also included in this category. These pages included all the query terms but not in the desired context or with the desired meaning from the academic users point of view. (For example, when the query was "dolly", information about the singer/actress Dolly Parton was assigned to this category since the search was for material about Dolly — a lamb cloned from the cell of an adult sheep).
- “Partly relevant.” To be deemed partly relevant a page would have to give some information connected to the query. Pages relating in part to the topic were included in this category.
- “Highly relevant.” Any page which, on the basis of the information it provides, closely matches the query, is related to the topic from an academic point of view and discusses the themes of the topic exhaustively. Three criteria for Web site evaluation were applied: authority, coverage and updating. The relevance judgment was made from the point of view of academic needs. A page with scientific content played an important role in this evaluation. By defining fixed standard inclusion criteria for each category, consistency and greater objectivity were ensured.
Besides these two kinds of relevance judgment, all the items retrieved by each search engine were classified according to type. Three kinds of classification were applied:
- Commercial, scientific, popular, private, governmental and recreational.
- Scientific articles, Web pages with particularly good materials (such as: manuals, newsletters, representations, atlases) content pages and navigation pages.
- Visible Web and Invisible Web.
The causes for precision failure and overlap of the results in the two search engines were investigated as well.
The comparison between AcadeME and Queryserver was done by submitting the same 50 queries to each search engine and computing the mean precision score of each using classical dichotomous relevance judgment (relevant or not relevant) from the point of view of the academic user. In addition, the results of AcadeME from Queryserver were evaluated using a three–level relevance scale: highly relevant, partly relevant and not relevant at all (see above). The relevance judgment was made from the point of view of academic needs.
Further, all the items retrieved by AcadeME from Queryserver were classified according to type. The three kinds of classification used in the AcadeME and Google comparison as described above were applied.
An important procedure in this evaluation was the detection of the causes for the precision failures in each search engine.
Since Queryserver was one of the input search engines of AcadeME, these tests enabled us to examine the efficiency of the AcadeME algorithm in reducing retrieval errors and to evaluate AcadeME’s contribution to the search results.
Findings and discussion
Despite the extensive scope of the study and its findings the present report is limited to those findings in the various research stages that supported the need for a specialized search engine, emphasized its contribution to the academic community or were used as input in determining an appropriate algorithm for a specialty meta–search engine.
The emphasis is on issues related to specialty search engines. Hence, evaluation of the prototype developed will be described in detail in order to confirm the main thesis that a specialty meta–search engine could contribute to the academic community and to check the efficiency of the algorithm developed in reducing precision failure and in selecting relevant, reliable materials.
The findings are reported here according to the various stages of the research.
Search patterns of the academic community
Most of the hypotheses concerning search patterns of the academic community were confirmed and supported the need for a specialized search engine. These hypotheses related to the following subjects:
1. Search engine use for research purposes.
The hypothesis “much search engine use” is for research purposes was confirmed. It was found that there was considerable search engine use for research purposes. Among the 487 respondents, 58.1 percent used search engines for research purposes at least once per week. Only 10.4 percent of the respondents did not use search engines for research purposes. There was also considerable use of search engines for teaching purposes, although less than for research purposes.Analysis of the queries by topic also confirmed intensive use of search engines for research/teaching purposes. According to the survey findings, 80 percent (N=339) of the queries reported were for research purposes, whereas only 20 percent were for leisure purposes.
According to TLA, 69 percent (N=783) of the queries were for research purposes. These findings are in line with findings in the literature — increasing general use of the Internet by the academic community for research and teaching purposes (Adams and Bonk, 1995; Applebee, et al., 2000; Ashley, 1995; Bane and Milheim, 1995; Bruce, 1995; Health on the Net Foundation, 1999) and using search engines for research purposes (Stobart and Kerridge, 1996). However, a new discovery in this research was increased use of search engines in comparison to previous research, which found that browsing was the most dominant search pattern (Health on the Net Foundation, 1999; Wolcott, 1998; Gilad, 1999). This can be explained in the time of the research and in the rapid evolvement of search engines.
Furthermore, in contrast to previous research (Kraut, et al., 1996; White, 1995), which found that young people used the Internet more than older individuals, the present research found that people in the age group 18–25 use search engine less than those aged 46 and more. This can be explained by the nature of the population one which uses the Internet for research and teaching purposes — and in the fact that researchers, teaching staff and students preparing for advanced degrees use the Internet for these purposes.
2. Success in search engine use.
The hypothesis “success in search engine use is reasonable but there is still much to be done” was also confirmed. Over fifty percent (57.2 percent, N=493) of the respondents found what they needed in 80 percent or more of their searches, but still the percentage of success among 42.8 percent of the respondents was 70 percent or less. The most reported problem in using search engines was the inability to find relevant information. For 45.5 percent of the respondents, this problem was reported as the most annoying one.3. Specialty search engine use.
The hypothesis “general search engines are the most used and specialty search engines are unknow” was also confirmed. According to TLA, only 5.75 percent (N=783) of the queries were performed using specialty search engines. From the survey findings it can be concluded that the usage rate of specialty search engines is less than 6 percent. Among 114 respondents, who reported on the last search engine that they used, only three (2.63 percent) used specialty search engines. Data is given in Table 1.
Table 1: Search engines used by subjects in their last query (N=114).
Search engine Frequency (f) Percentage Wos 1 0.88 PubMed 9 7.89 Medline 4 3.50 Biological Abstracts 1 0.88 Omim 1 0.88 Total databases 25 21.92 Start 2 1.75 Tapuz 1 0.88 Nana 4 3.50 Zooloo 1 0.88 Walla 2 1.75 Total native search engines 10 8.77 CiteSeer 1 0.88 CNN 1 0.88 Gh2000 2 1.75 Total specialty search engines 3 2.63 Copernic 1 0.88 Go.com 1 0.88 Northern Light 1 0.88 Hotbot 1 0.88 Yahoo
13 11.40 Google Images
1 0.88 43 37.71 AskJeeves 2 1.75 GeoCities 1 0.88 Lycos
1 0.88 Goto
1 0.88 AltaVista
7 6.14 MSN 2 1.75 Yandex 1 0.88 Total general search engines
and portals (including meta)76 66.6 Total search engines 114 100
4. Number of search engines used in one search.
The hypothesis “most of the users use only one or two search engines in a single search” was also confirmed. It was found that most users use only one or two search engines during one search. According to TLA, 96 percent (N=783) of the queries were performed in one search engine. Only 3.2 percent of the queries were performed in two search engines and 0.5 percent were performed in three search engines. According to the survey findings, 44.6 percent of the respondents (N=424) used only one search engine, 88 percent used one or two search engines, and only 5.8 percent always used more than one search engine.An unexpected conclusion deriving from the various findings was that there is confusion among a portion of the research population between search engines and databases. For example, on the question “what was the last search engine you used,” 21.9 percent mentioned names of databases such as the medical database PubMed (see Table 1). The differences between the TLA and the survey findings in some variables, which can be explained by this confusion, supported this conclusion.
The above findings demonstrate the extensive use of search engines; the possibility of using unreliable materials especially in light of the confusion among a portion of the population between databases and search engines; the fact that specialty search engines remain unknown and unused; the common pattern of using only one search engine or two in one search — all point to the potential contribution of a specialty meta–search engine that would utilize, simultaneously, some of the repositories of specialty search engines, which usually contain reliable control materials.
Other findings were used as input for the desired features of the specialty meta–search engine. They related to the following:
5. Number of checked results.
The hypothesis “number of checked search engine results is small” was confirmed. According to the survey findings, 33.2 percent of the respondents checked only the first ten results or even less. Over sixty percent (66.4 percent) of the respondents checked up to twenty results, and 80.7 percent reported that they frequently found what they were searching for in the first page of results, i.e., within the top ten.Moreover, too much information was perceived to be a disadvantage rather than an advantage. Over forty percent (40.7 percent) of the respondents reported that “too much information” was a problem that annoyed them, and 22 percent reported this problem as the only one that bothered them in using search engines.
The TLA findings supported this trend. The number of checked results ranged from one result to 66. In 82.3 percent of the searches, ten results or less were checked.
6. Search language.
The hypothesis “most search options are not used” was confirmed. The most frequently used option was the simple search, i.e., entering a search term or multiple search terms without any operators. According to the survey findings, 81 percent of the respondents (N=420) used the simple search often/very–often and only five percent did not use the simple search option at all. The most frequently used option reported after the simple search option was the Boolean search; 40 percent (N=433) reported that they used this option. The least known search options were: the proximity operator “NEAR,” natural language and quotation marks for a phrase. Use of the help feature was very low — only 4.1 percent (N=381) used it “often/very-often.”There were significant positive correlations between the “use of the various search options” and their “perceived importance”; 87.1 percent (N=403) of respondents thought that the simple search option was “important/very-important.” Over sixty percent (67.4 percent, N=420) thought that the Boolean option was “important/very-important.” Pearson correlations between use and perceived importance regarding the simple and the Boolean search were 0.532 and 0.690 respectively (p=0.01). The trend of using the simple search is emphasized by the TLA findings. According to these findings, 73.3 percent used the simple search and only 5.7 percent used the Boolean operator. The differences between the TLA and the survey findings relating to the Boolean operators can also be explained by the confusion between search engines and databases by a portion of the surveyed population.
These findings concerning the extensive use of the simple search are in line with findings in the literature (Hoelscher, 1998; Jansen, 2000; Jansen and Pooch, 2000). Furthermore, it was reported in literature that use of more complex queries appears to have a very small impact on search results and may not be worth the increased effort required to learn the advanced search rules (Jansen, 2000) especially that some researches have criticized the Boolean model as being too complex for most users (Hildreth, 1989; Young and Shneiderman, 1993).
7. Preferred search engine interface.
A substantial number of respondents (63.4 percent, N=322) preferred the basic search interface, i.e., the search box for entering the search strategy, over the advanced search interface which allows the user to select the search options from a structured search form using predetermined language in a user fill–in template.8. Desired material language.
It was found that the most requested material was in English; 80.3 percent reported that they wanted material in English. According to the TLA, only six percent of the queries performed were in the native language.9. The desired materials
Research articles were the most requested materials; 83.07 percent reported that they wanted to find research articles. Various reference materials such as dictionaries and encyclopedias (43.91 percent), guidelines for scientific writing (38.97 percent), phone numbers and e–mail addresses (25.48 percent) and conferences (21.67 percent) were the most requested after research articles.10. Using the same queries at different times for receiving updates.
Over twenty percent (23.3 percent) used the same queries at different times for receiving updates very frequently and another 29.5 percent used them sometimes.Generally, the same trends relating to the above hypotheses were found by the survey and the TLA. The slight differences in some trends, such as using Boolean operators and number of the checked results can be explained by the confusion among a portion of the research population between search engines and databases.
The similarity between the survey and the TLA findings supports the validity and reliability of the research findings.
At the bivariate and multivariate level — a significant correlation was found between discipline and variables relating to the interface — such as preferring a structured search form over the simple search form by nursing staff and students. Whereas 63.4 percent of all the responders reported that the basic free box is the interface they preferred and according to the TLA 89.2 percent of the searches were performed in the basic search form, only 45.8 percent and 57.6 percent of the respondents from the nursing and the medical communities preferred the basic free box search over the advanced structured search form, respectively.
There was also a positive significant correlation between discipline and variables relating to search engine repositories, such as desired material age and desired material language. According to the findings, medical faculty staff and students are also interested in historical materials, while nursing staff and students are more interested in materials in the native language than others. Whereas 45 percent of all the respondents wish to find material from the current year, this percentage is much lower among the nursing and the medical communities (28.9 percent and 36.9 percent, respectively). While 80.3 percent of all the respondents reported that they wish to find material in English, and according to the TLA, only six percent of the queries performed were in the native language, only 47.4 percent of the members of the nursing community wish to find English material.
All other findings were common to all the research disciplines investigated, since no significant correlation was found between them and the discipline variable that would indicate a different treatment for each discipline.
All the above findings led to the following conclusions:
I. Conclusions relating to the interface of the specialty search engine
- The findings concerning a low number of checked search results along with the reported problem of not finding relevant information, on the one hand, and too much information displayed, on the other — all supported the need for displaying only the most relevant results and not too many.
- From the finding of high request for various reference materials and no correlation between the discipline and most of the reference materials, it can be concluded that reference materials are common to all disciplines and therefore it might be worth specifying a separate category in the specialty search engine for reference materials without connection to domain.
- The findings indicating considerable use of the same queries for receiving updates supported including an alert service as an option.
- The correlation between the medical and nursing disciplines and preferring a structured search supported including a structured search form in the specialty search engine for medicine and nursing in addition to a free search form.
II. Conclusions concerning repositories of the specialty search engine
- There is a need for specialized repositories for every domain. In addition, general reference as well as specific reference materials should be included.
- Taking into consideration the correlation between the variables “discipline” and “age of material,” indicating a greater need for historical materials in the medical than in other domains, it is recommended that, in addition to up–to–date materials, historical materials, too, be included in the repositories of a specialty meta–search engine for medicine.
- Taking into account the positive correlation between materials in the native language and the nursing discipline, it is recommended that materials in the native language be included in the repositories of a specialty meta–search engine for nursing.
III. Conclusions concerning the ranking algorithm
The basic premise is that the ranking algorithm should be supportive to the typical search patterns of Web searchers. The findings concerning extensive use of the simple search, not knowing many search options and not using the help feature — all supported the need to adjust the system to user needs as far as possible and hence to adapt the implicit AND rule. This means that when the user enters multiple search terms, the search engine assumes that the user wants pages matching all the terms. Moreover, it is recommended that the search engine consider the search as a proximity search, i.e., it favor pages in which the user search terms are close to each other.Overall these conclusions, deriving from search patterns, are identical to those deriving from an analysis of specialty search engine features.
Performance of the specialty search engines
The comparison between the seven specialty search engines focused on three main features: retrieval efficiency, typical precision errors and overlapping. From this comparison, conclusions relating to a specialty meta-search engine, the need for such a search engine and its desired features were drawn. The main findings related to the following subjects:
I. Efficiency of retrieval
The various search engines differ significantly in their retrieval efficiency. A significantly high correlation was found between the variable “search engine” and “precision” (0.542, p=0.000). This means that there are differences in the precision ratio of the various search engines. However, in most of the search engines the average precision is not high (60.7 percent) and the recall is problematic. The number of queries that returned 0 results was between 2 and 58 in the various search engines. F scores were not high in most of the search engines. Excluding Scirus with its large repository, it was found that F scores ranged between 12.95 percent and 48.24 percent. The relative recall rates of the seven specialty search engines examined ranged from 10.28 percent to 89.6 percent. Data on recall and precision is given in Table 2.
Table 2: Specialty search engines performance.
Measure search engine Precision Relative Recall F Relative score [2] E [3] Scirus 92.2 89.62 90.89 1.000 9.11 healthfinder 42.6 22.83 29.73 0.327 70.27 MedHunt 51.9 20.75 29.65 0.326 70.35 OMNI 88.2 25.38 39.41 0.434 60.59 MedWeb 88.6 19.72 32.26 0.355 67.74 Hardin MD 17.5 10.28 12.95 0.143 87.05 QueryServer 52.9 44.34 48.24 0.531 51.76
It was found also that sometimes search engines with low general scores are better than others for special queries. This makes sense since many search engines are specialized not only for the domain but for its sub–domains. For example, in medicine, NaturalHealthWeb.com, a specialized searchable directory of natural health and alternative medicine Web sites, would be better for queries in this subject than other specialty medical search engines with better general scores.
II. Typical precision failures
Precision failure is defined as non–relevant documents retrieved, i.e., the system failed to retrieve relevant documents only. An attempt was made to identify precision failures along with their causes. The reasons for the retrieval errors were then classified into four categories:
- The query terms appear partially in the title, the description or in the entire site.
- The query terms appear in the title, the description or in the entire site not in the right context, due to an undesired combination between the terms — failures identified in the literature (Lancaster, 1972) as false coordination or incorrect term relationships. Retrieval failures due to query terms not according with the desired meaning were also included in this category.
- Results not containing any relevant information at all. These results lead to irrelevant sites. Some of these results do not include any of the query terms in their title or in the description. Other results include search terms in their title or description which are apparently relevant but the link leads to sites with no connection to the query.
- Repeated items and not mirror sites, i.e., identical sites with the same URL. Identical sites with different URLs were not included in this category.
Data on the causes for precision failure in the input specialty search engines of AcadeME is given in Table 3.
Table 3: Causes for precision failure in input specialty search engines of AcadeME.
Search engine Query terms appear partly Query terms appear not in the right context Results not containing any relevant information Repeated items and not mirror sites Total N Hardin MD Frequency (f) 287 1 29 27 344 624 Percentage 83.4% 0.3% 8.4% 7.8% 100% MedHunt Frequency (f) 55 93 2 150 424 Percentage 36.7% 62.0% 1.3% 100% MedWeb Frequency (f) 5 2 5 2 14 236 Percentage 35.7% 14.3% 35.7% 14.3% 100% healthfinder Frequency (f)
284 35 319 568 Percentage 89.0% 11.0% 100% OMNI Frequency (f) 22 11 33 305 Percentage 66.7% 33.3% 100% Scirus Frequency (f) 29 12 16 5 62 1030 Percentage 46.8% 19.4% 25.8% 8.1% 100% QueryServer Frequency (f) 113 5 250 47 415 889 Percentage 27.2% 1.2% 60.2% 11.3% 100% Total Frequency (f) 795 31 428 83 1337 4076 Percentage 59.5% 2.3% 32% 6.2% 100%
A significant high correlation was found between “search engine” and “precision failure” (0.424, p=0.00), meaning that the reasons for precision failures differ in the various search engines. However, in general, many precision failures were found (39.4 percent of the records retrieved). Most of the precision failures in all search engines (56 percent) belonged to the category of “the query keywords appear partially.”
III. Overlapping between search engines Overlap was low (OR [ 4] =0.004), meaning that the search engines complement each other. Data is given in Table 4.
Table 4: Search engine overlap — odds ratio.
Overlap Overlap [5] Unique results [6] OR 17 4038 0.004
These findings reinforced the need for a specialized search engine which would contribute to retrieval efficiency.
The basic premise is that since the materials in specialty search engines are controlled and sponsored by reliable authorities, they are of high quality. But since these search engines suffer from a recall problem, presumably because of their relatively small repositories, a specialty meta–search engine that would search several search engines simultaneously might improve the recall rate, especially in light of the low overlap between search engines. A specialty meta–search engine with an independent relevance mechanism might contribute also to solving the precision problem.
The findings support the following features of a specialty meta–search engine:
1. An independent mechanism for ranking the results.
As noted above, specialty search engines also suffer from precision problems, presumably because of software or updating problems. This fact reinforces the need for an independent relevance mechanism. Most precision errors are caused by retrieval of pages that include only one search term of the search strategy. If this and other precision problems are taken into consideration, it may be assumed that the solution to most of the precision problems detected would be a specialty meta–search engine with an independent relevance mechanism that would give a higher ranking score to results that contain all the query terms and appear in closest proximity.2. A relatively small number of input specialty search engines.
The recall problem in most specialty search engines supposedly deriving from their small repositories reinforces the need to combine a considerable number of search engines as input to the specialty meta–search engine. On the other hand, due to the very low overlap between search engines and taking into consideration the resource problem involved in using a large number of search engines, it is possible to reduce the number of input search engines, especially if one or more of them has a large repository.3. Two separate indices in the knowledge base of the specialty meta–search engine as the best solution to the problem of choosing the best search engines.
One of the main functions of a meta–search engine is to select the best search engines for a specific query. As will be described below, our prototype used the “learning method” for selecting the best search engines, i.e., based on scores of queries results used in the past.
It was found that the best search engines are not always optimal for all queries, and sometimes for special queries search engines with lower scores are better. These findings reinforced the need for two separate indices in the specialty meta–search engine — an index for storing the general scores of each search engine and an index for storing scores for the query or terms of the query.
An algorithm for a specialty meta–search engine
Most of the above conclusions were implemented in an algorithm for a specialty meta–search engine. Another main factor that was taken into consideration in developing the algorithm was the dynamic nature of the Web.
The main problem of a specialty meta–search engine is the “search engine selection problem,” i.e., finding the search engines that perform best for a query (called “server selection&”). There are several methods for “server selection” reported in the literature. All of them can be classified in two main categories: methods based on frequencies of terms in the search engine repositories, and methods based on learning and use queries performed previously for evaluating the input search engines. The majority of studies that deal with the “server selection” problem belong to the former category (Callan, 2000; Craswell, et al., 2000; Callan, et al., 2000; French, et al., 1998, 1999a, 1999b; Yuwono and Lee, 1997). Only a few studies are based on the latter category of learning method (Dreilinger and Howe, 1997; Howe and Dreilinger, 1997; Fan and Gauch, 1999; Gauch, et al., 1996). Due to the dynamic nature of the Web, our preferred method for selecting the best search engines was the “learning method.”
The learning method was implemented in the algorithm developed; its main feature is the selection of the best search engines for a query based on continuously updated cumulative scores (of the results retrieved).
Implementation of the algorithm in a prototype
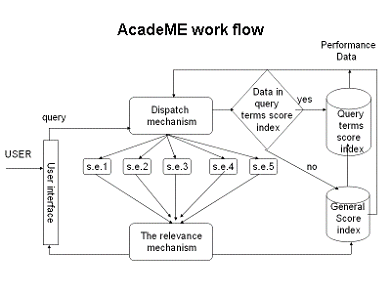
The proposed algorithm was implemented in a prototype of a medical specialty meta–search engine, called AcadeME. AcadeME is designed to query the most relevant search engines. The process of choosing the best search engines by AcadeME is illustrated in Figure 1 and described below.
Figure 1. AcadeME work flow. There were two stages in the AcadeME implementation. In the first stage — the preparation stage — initial scores for each of the input search engines were calculated and stored in its two indices: one for the general score of each search engine and the other for the query term scores. This was done by submitting 50 queries to each of the seven input search engines. The top ten results from each search engine were evaluated by the independent relevance mechanism of AcadeME. It is important to note that in this evaluation, based on the research findings and the experiments conducted, ranking of the results by the input search engines was ignored. Those experiments that supported the decision to ignore ranking of results by the input search engines compared prototype performance using two versions: one that took into account the search engines’ ranking of results and the other that ignored them. A significant correlation (0.264, p=0.000) was found between “version” and “precision.” In the version that ignored the input search engines’ ranking, precision was 91.5 percent, whereas in the version that took them into consideration it was 70.8 percent. Data is given in Table 5.
Table 5: Prototype performance using two versions (N=959).
Relevance version Relevant Not relevant Total First version with input search engines ranking Frequency (f) 339 140 479 Percentage 70.8% 29.2% 100% Second version without search engines ranking Frequency (f) 439 41 480 Percentage 91.5% 8.5% 100% Total
Frequency (f) 778 181 959 Percentage 81.1% 18.9% 100%
The procedure of giving scores to search results, ignoring the search engines’ ranking, was done in the following way. Firstly, each relevant result In the top ten results got the same initial score, 1/10; then the score of each result was calculated taking into consideration two main criteria: number of query terms in the title and description of each result among the top ten results, and retrieval of the result by more than one search engine. Based on the first criterion, the score for each result was calculated according to the formula:
where Score A is 1/10, nwdt stands for number of query terms found in the result title or the description, and nwq stands for number of words in query. According to this formula, a result that did not contain any query terms in the title or in the description remained with the initial score of 1/10, while a result that contained in its title or description one query term or more would receive a higher score of up to twice its initial score. The second criterion was retrieval of the result in more than one search engine. In this case the score of the result was the sum of the scores of the results in the various search engines, provided it was no higher than 1.
Thus, all the top ten result scores from all the input search engines were calculated. The general average score for each search engine was stored in the general score index and in the query terms index. In the second stage, that of running the real queries by the end users, the dispatch mechanism of AcadeME first selected the best five search engines for a query term based on the score in the query score index. If the query term was not in its database it would select the five search engines with the best general scores from the general score index. Then it evaluated the results from the five search engines according to the relevance mechanism described above. In this manner, all top ten result scores from the all the input search engines were calculated and only 60 percent of the results with the higher scores were considered relevant and displayed to the user. The results from the search engines were integrated and displayed in a unified format. The two kinds of scores — general score and term score — were stored repeatedly in the appropriate index. All this was done automatically.
With this procedure the data used by the search engine to evaluate the performance of the input search engines is continuously updated and AcadeME makes effective searching decisions over time as it accrues more knowledge. Moreover, it enables the search engine to be autonomic and not dependent on reports from the input search engine servers.
In conclusion, the main features of this search engine were:
- Selection of the best search engines for a query, based on their continuously updated cumulative scores. This feature is compatible with the dynamic nature of the Web and enables meta–search engine autonomy in relation to the input search engines.
- Two indices for storing search engine scores: scores for query terms and general scores for each search engine. Two indices were applied because it was found that a search engine with the best general score is not always the best one for every query term.
- An independent mechanism for ranking results according to relevance and automatic classification of the relevance of search engine results, based on the number of query terms included in the title of the result and its description and retrieval of a result by more than one search engine, while ignoring the ranking of the input search engines.
- Displaying the most relevant search results — but not too many.
As for technical aspects, the AcadeME system was implemented in Perl [ 7] and runs on a Windows 2000 platform. Queries are sent to remote search engines via HTTP [ 8] in a manner similar to that used for Web browsers. The software consists of a main search program running several processes simultaneously for searching and parsing the results of the various search engines. Each input search engine has its own module that handles its results, parsing [ 9] the relevant data and displaying them in a uniform manner: title, URL and brief description. A communication module serves the different search engines. The two indices are built automatically in a Microsoft Access database. Access to the database is via ODBC [10]. The Web server used by AcadeME is a local Apache server.
Evaluation of AcadeME
Evaluation of the performance of AcadeME confirmed the thesis regarding the importance of a specialty meta-search engine for the academic community.
Comparison between AcadeME and Google
I. Efficiency of retrieval
According to the dichotomous relevance judgment, the macro precision in AcadeME was 83 percent and in Google it was 76 percent, but according to the T test, the difference between the two systems in terms of precision was statistically insignificant.The differences between the two search engines are emphasized when an ordinal scale for relevance judgment is used. The results are presented in Table 6.
Table 6: Distribution of results according to relevancy in AcadeME and Google (N=1000).
Relevancy search engine Not relevant Partly relevant Highly relevant Total AcadeME Frequency (f) 85 87 328 500 Percentage 17.0% 17.4% 65.6% 100% Frequency (f) 120 191 189 500 Percentage 24.0% 38.2% 37.8% 100% Total Frequency (f) 205 278 517 1000 Percentage 20.5% 27.8% 51.7% 100%
A significant correlation (0.287, p=0.000) was found between “search engine” and “relevance.” According to the findings in Table 6, 65.6 percent of the results in AcadeME were highly relevant from the point of view of the academic user whereas in Google only 37.8 percent were highly relevant. Almost twenty percent (17 percent) of the retrieved items in AcadeME were not relevant compared to 24 percent in Google. In Google 38.2 percent of the retrieved items were partly relevant in comparison to 17.4 percent in AcadeME.
II. Typical precision failures.
The causes for precision failure in the two search engines were classified into six categories:
- The query terms appear partially in the title, the description or in the entire site.
- False Coordination.
- Query terms not according with the desired meaning.
- Results not containing any relevant information at all. These results lead to irrelevant sites. Some of these results do not include any of the query terms in their title or in the description. Other results include search terms in their title or description that are apparently relevant but the links lead to a site with no connection to the query.
- Dead links.
- Repeated results and not mirror sites.
Table 7: Causes for precision failure in Google and AcadeME.
Search engine Query terms appear partially False coordination Query terms don’t accord with the desired meaning Results don’t include any relevant information Dead links
Error messagesRepeated items and not mirror sites Total AcadeME Frequency (f) 18 30 5 5 22 5 85 Percentage 21.2% 35.3% 5.9% 5.9% 25.9% 5.9% 100% Frequency (f) 2 30 25 7 26 30 120 Percentage 1.7% 25% 20.8% 5.8% 21.7% 25% 100% Total Frequency (f) 20 60 30 12 48 35 205 Percentage 9.8% 29.2% 14.6% 5.9% 23.4% 17% 100%
The most notable finding is that the percentage of errors belonging to the category “query terms appear in the results but not in the desired meaning” is much higher in Google than in AcadeME. This is an expected result since AcadeME uses specialty search engines whereas Google is a general search engine. Such errors could be avoided if the user were aware of the fact that he is working with a general search engine and added a broad topic to a specific term. Since users enter very short queries (Jansen and Pooch, 2000), a given system needs to adapt to user information needs. AcadeME as a specialty search engine that meets these needs. Another notable finding is that the percentage of errors in the category “search terms appear partially” is much higher in AcadeME than in Google. This may be explained by the algorithms of the specialty search engines that are not always efficient in retrieving items that include all the search terms in the results. This becomes much more obvious when analyzing the specialty search engine failures (see Table 3). Compared to this data on the causes of retrieval errors in all seven specialty search engines, it may be said that AcadeME succeeded in reducing this error type but still its performance in this domain is inferior to that of Google.
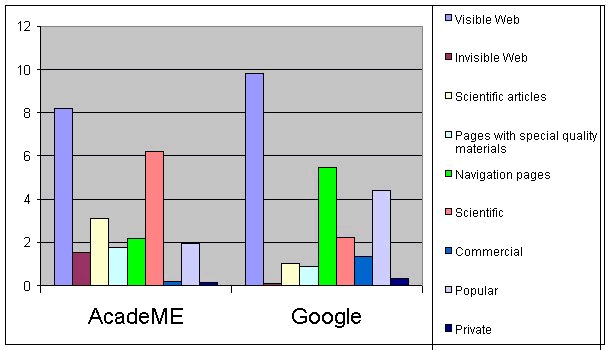
A statistically significant correlation was found also between “search engine” and “type of material retrieved.” A high percentage of reliable sites containing high–quality material, including scientific articles and material from the Invisible Web, were found by AcadeME. Nearly seventy percent (68 percent) of the items retrieved by AcadeME (N=462) were scientific compared to 24 percent in Google (N=465). Over thirty percent (33.5 percent, N=463) of the items retrieved by AcadeME were scientific articles compared to 10.5 percent (N=478) in Google. In Google, 15 percent of the items were commercial in comparison to two percent in AcadeME. In addition, a higher percentage of navigation pages (57.3 percent) were found in Google compared to AcadeME (23.3 percent).
With AcadeME, 15.8 percent (N=486) of the retrieved items were from the Invisible Web compared to 0.8 percent (N=495) in Google. Figure 2, which describes the average of the various types of pages in the top ten results in each search engine, reflects the main features of each engine.
Figure 2. The average of the various types of pages in AcadeME and Google The main features of AcadeME are as follows:
- Most of its results are from the Visible Web, though the average of Invisible Web pages is higher than that of Google.
- A high percentage of its results are reliable, scientific pages.
- A relatively high percentage is scientific articles.
The main features of Google are as follows:
- Most of its results are from the Visible Web.
- A high percentage of its results are navigation pages.
- A relatively high percentage is popular materials.
Yet, taking into consideration the low overlap of results (7.6 percent) and the high percentage of relevant results in Google, it may be said that these search engines really complement each other.
Comparison between AcadeME and QueryServer
The comparison between AcadeME and Google emphasizes AcadeME’s contribution to the quality of the results from the point of view of the academic user and indicates successful selection of input specialty search engines by AcadeME.
The comparison between AcadeME and a single specialty search engine, QueryServer, which was one of the input specialty search engines, emphasizes AcadeME’s contribution to relevancy as well as to the variety of results and highlights the efficiency of its relevance mechanism.
I. Efficiency of retrieval
AcadeME’s contribution is emphasized by comparing distribution of the results in the two search engines according to relevancy.
Table 8: Distribution of results in QueryServer and AcadeME according to relevancy (N=1000).
Search engine Not relevant Relevant Total AcadeME Frequency (f) 85 415 500 Percentage 17.0% 83.0% 100% QueryServer Frequency (f) 213 287 500 Percentage 42.6% 57.4% 100% Total
Frequency (f) 298 702 1000 Percentage 29.8% 78.2% 100%
A significant correlation (0.280 p=0.000) was found between the search engine and relevancy. In QueryServer, 42.6 percent of the results were not relevant compared to only 17 percent of the results retrieved by AcadeME. The average precision in AcadeME was 83 percent, with a S.D. of 17.6, whereas the precision in Queryserver was 57 percent, with a S.D. of 38.6.
II. Typical precision failures
AcadeME’s contribution is emphasized when comparing the causes for retrieval failure in the two search engines.Four types of retrieval failures were found:
- The query terms appear partially in the title, the description or in the entire site.
- Precision failures due to False Coordination or due to query terms not according with the desired meaning.
- Results not containing any relevant information at all.
- Repeated results with the same URL and not mirror sites.
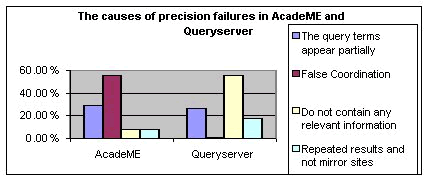
A significantly high relation (0.707 p=0.000) was found between search engine and retrieval failures, i.e., each search engines has typical retrieval failures. Data is given in Table 9 and illustrated by Figure 3.
Table 9: Causes of precision failure in AcadeME and QueryServer.
Search engine Query terms appear partially Incorrect Term relationship or query terms not according with desired meaning Not relevant at all Repeated pages and not mirror pages Total AcadeME Frequency (f) 18 35 5 5 63 Percentage 28.6 55.6 7.9 7.9 100 QueryServer Frequency (f) 41 1 86 28 156 Percentage 26.3 0.6 55.1 17.9 100 Total Frequency (f) 59 36 91 33 219 Percentage 26.9 16.4 41.6 15.1 100
Figure 3. The causes of precision failures in AcadeME and Queryserver. The most remarkable finding is that most of the precision failures in AcadeME are due to false coordination whereas most of the precision failures in QueryServer are due to results that contain no information relevant to the query. Usually the link in these results leads to sites that are reliable but are irrelevant to the query. Some of these irrelevant pages include the query terms but the subject of the page is not relevant to the query and others do not include the query terms at all. From a comparison of the frequency of failure of this kind between AcadeME and QueryServer, and taking into consideration the fact that QueryServer was one of the input search engines for AcadeME, it can be concluded that AcadeME, with its independent relevance mechanism, succeeds in reducing these retrieval failures. In AcadeME, 13.8 percent of the results of 50 queries were from QueryServer and none of them was a failure of the type “results that contain no information relevant to the query.”
The second frequent reason for retrieval failure in AcadeME was “the query terms appear only partially.” In QueryServer the percentage of results of this kind was relatively low but this was the main reason for precision failure in the seven input search engines of AcadeME (see Table 3). The findings above (Table 9) indicate that AcadeME, with its independent mechanism, succeeded in reducing remarkably this kind of precision failure, albeit not entirely.
III. Diversity of the results
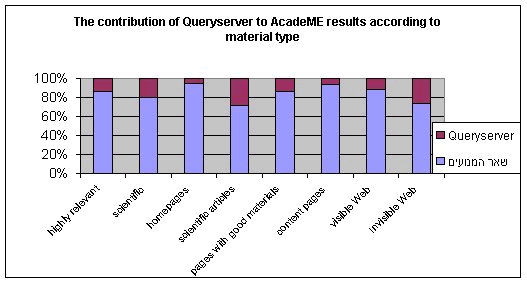
In addition to its contribution to results relevancy by filtering them, AcadeME contributes to their variety as well. A significant correlation was found between the seven input search engines and material type of the results retrieved. The diversity of the results is illustrated in Figure 4.
Figure 4. The contribution of Queryserver to AcadeME results according to material type. The meaning of these findings is that each search engine has a typical type of material, indicating that the selection of the specialty search engines by AcadeME was done well and efficiently.
To sum up, the hypotheses regarding the specialty search engines and the main thesis that a specialty meta#150;search engine would contribute to the academic community in finding relevant quality materials were confirmed. The comparison with Google emphasized mainly AcadeME’s contribution to the quality of the results from the point of view of the academic user. The comparison with QueryServer emphasized AcadeME’s contribution to the relevancy of results as well as to diversity of material types.
Further research
This research has contributed mainly to specialty search engine research, especially in light of the paucity of research pertaining to this field. It shed light on the use and the performance of specialty search engines and proposed a model of a specialty meta–search engine that was found to be effective. The database–selecting algorithm developed in this study can be utilized for other applications such as specialty meta–search engines for domains other than medicine (such as life sciences and computer science), and a meta–search engine for databases in the Invisible Web.
While this research contributes to retrieval on the Web by proposing an effective search engine model and providing an appropriate database selection algorithm for a meta–specialty search engine, it also represents a baseline for further work.
The emphasis in developing the prototype was on the database selection procedure and both query formulation and results presentation used in this prototype were quite simple but the information achieved in this research could be used to support more sophisticated system. The relevance mechanism could be improved as well.
Future studies that would overcome the limits of this research and enlarge its scope can be conducted. In these studies, all the conclusions found in this research and not implemented in AcadeME could be employed, such as: an alert service; a structured search form in addition to the simple search box; and, a special category for reference materials.
In addition, advanced techniques of Web mining, such as clustering and personalization, could be applied. A search language of the specialty meta–search engine could be developed by using a natural language interface, and various techniques could be used in order to improve the search results.
Since most of the retrieval errors in AcadeME are due to false coordination, an interesting research focus could be the development of a content–based specialty meta–search engine that would pre–download the top ten search results and consider the full HTML of each page when ranking them, using advanced techniques such as semantic as well as statistical analysis.
About the authors
Yaffa Aharoni is a reference and Internet librarian at Tel Aviv University Gitter–Smolarz Library of Life Sciences and Medicine. She holds a Ph. D. from Bar–Ilan Univrsity and a MLS degree and B.A. from the Hebrew University, Jerusalem . This article is based on her Ph.D. thesis, conducted in the Information Sciences Dept., Bar–Ilan University, under the supervision of Dr. Ariel J. Frank, Dept. of Computer Science, and Dr. Snunith Shoham, Dept. of Information Science Bar–Ilan University.
E–mail: YaffaA [at] tauex [dot] tau [dot] ac [dot] ilAriel Frank is a faculty member in the Department of Computer Science at Bar–Ilan University in Israel since 1984. He has served as deputy chairperson of his department for 15 years. He received his undergraduate, master’s and doctoral degrees in computer science from Bar–Ilan University, the Weizmann Institute (Israel), and SUNY at Stony Brook, respectively.
Ariel’s main areas of interest are: Internet Resources Discovery (IRD), Distributed Education (DE), Multimedia (MM), and Distributed Systems (DS). Ariel has served as chairperson and directorate member of the Israeli UNIX User Association (AMIX) for close to a decade. He has served as chair and committee member of numerous conferences and workshops, including a dozen such UNIX events and as organizing chair of seven Bar–Ilan International Symposium on Foundations of AI (BISFAI) conferences.
Snunith Shoham has a doctorate degree from the University of California, Berkeley, School of Library and Information Studies. She is a senior lecturer in the Department of Information Science. Bar–Ilan University. She was the Chair of the Department during 1998–2005. She has published the books Organizational Adaptation by Public Libraries (Westport, Conn.: Greenwood Press, 1984) and Library Classification and Browsing: The Conjunction of Readers and Documents (Brighton: Sussex Academic Press, 2000) as well as many articles on knowledge organization and Information gathering behavior.
Notes
1. Relative recall measures the proportion of relevant documents retrieved by one given search engine among all relevant documents retrieved by all search engines.
2. The relative score of each search engine in comparison to the highest score (1).
4. Odds ratio — The odds ratio is a way of comparing whether the probability of a certain event is the same for two groups. An odds ratio of 1 implies that the event is equally likely in both groups. An odds ratio greater than one implies that the event is more likely in the first group. An odds ratio less than one implies that the event is less likely in the first group.
5. Results (hits) found by more than one search engine.
6. Unique results (hits) found by one (and only one) search engine.
7. Perl (Practical Extraction and Report Language) — is an object oriented programming language especially designed for processing text. Because of its strong text abilities Perl has become a popular language for writing CGI scripts.
8. HTTP (Hypertext Transfer Protocol) — HTTP is the protocol for moving hypertext files across the Internet. It is the standard language used between a Web browser and a server to request a document and transfer its contents.
9. Parsing — The process of deciphering and manipulating input data and text so it can be used in a program. Usually regular expressions i.e., sets of symbols and syntactic elements are used in this process to match patterns of text.
10. ODBC (Open Database Connectivity) — A common standard application programming interface (API) of Microsoft for accessing a database. For example, an application can use ODBC to access a Microsoft SQL server, Oracle database server or Microsoft Access database.
References
E.G. Ables, P. Liebscher, and W. Denman, 1996. “Factors that influence the use of electronic networks by science and engineering at small institutions,“ Journal of the American Society for Information Science, volume 47, number 9, pp. 146–158.
J.A. Adams and S.C. Bonk, 1995. “Electronic information technologies and resources: Use by university faculty preferences for related library services,” College and Research Libraries, volume 56, number 2, pp. 119–131.
J.W. Allen, R.J. Finch, M.G. Coleman, L.K. Nathanson, N.A. O’Rourke, & G.A. Fielding, 2002. “The poor quality of information about laparoscopy on the World Wide Web as indexed by popular search engines,” Surgical Endoscopy, volume 16, number 1, pp. 170–172.
A. Applebee, P. Clayton, C. Pascoe, and H. Bruce, 2000. “Australian academic use of the Internet: Implications for the university administrators,” Internet Research, volume 10, number 2, pp. 1066–2243.
N.W. Ashley, 1995. “Diffusion of network information retrieval in academia,” Doctoral dissertation, University of Arizona.
A.F. Bane and W.D. Milheim, 1995. “Internet insights: How academic are using the Internet,” Computers in libraries, volume 15, number 2, pp. 32–36.
J. Bar–Ilan and B.C. Peritz, 2004. “Evolution, continuity and disappearance of documents on a specific topic on the Web: A case study of ‘informetrics’,” Journal of the American Society for Information Science and Technology, volume 55, number 11, pp. 980–990.
S.E. Bedell, A. Agrawal, and E. Petersen, 2004. “A systematic critique of diabetes on the World Wide Web for patients and their physicians,” International Journal of Medical Informatics, volume 73, numbers 9–10, pp. 687–694.
G.K. Berland, M.N. Elliott, L.S. Morales, J.I. Algazy, R.L. Kravitz, M.S. Broder, D.E. Kanouse, J.A. Muñoz, J.–A. Puyol, M. Lara, K.E. Watkins, H. Yang, and E.A. McGlynn, 2001. “Health information on the Internet: Accessibility, quality, and readability in English and Spanish,” Journal of the American Medical Association, volume 285, pp. 2612–2621
K. Bharat and A. Broder, 1998. “A technique for measuring the relative size and overlap of public Web search engines,” Proceedings of the Seventh International World Wide Web Conference, pp. 379–388.
H. Bruce, 1995. “The impact of Internet on academic teaching in Australia,” Education for Information, volume 13, number 3, pp. 177–191.
B. de Bruijn, R. Holte, and J. Martin, 1999. “An automated method for studying interactive systems,” at http://textomy.iit.nrc.ca/pubdl/debruijn1999.pdf, accessed 9 December 2005.
J. Callan, 2000. “Distributed information retrieval,” In: W.B. Croft (editor). Advances in information retrieval. Dordrecht: Kluwer, pp. 127–150.
J. Callan, A.L. Powell, C. French, and M. Connell, 2000. “The effects of query–based sampling on automatic database selection algorithms,” Technical Report CMU–LTI–00–162, Language Technologies Institute, School of Computer Science, Carnegie Mellon University.
M. Chakrabarti, M. van den Berg, and B. Dom, 1999. “Focused crawling: A new approach to topic–specific Web resource discovery,” Proceedings of WWW8 (Toronto), and at http://www.cse.iitb.ac.in/~soumen/doc/www1999f/html/, accessed 9 December 2005.
H. Chu, 1994. “E–mail in scientific communication,” Proceedings of the Fifteenth National Online Meeting (New York), pp. 77–86.
N. Craswell, P. Bailey, and D. Hawking, 2000. “Server selection on the World Wide Web,” Proceedings of the Fifth ACM Conference on Digital Libraries, pp. 37–46.
J. Ding, L. Gravano, and N. Shivakumar, 2000. “Computing geographical scopes of Web resources,” Proceedings of the 26th VLDB conference (Cairo, Egypt), at http://www.cs.columbia.edu/~gravano/Papers/2000/vldb00.pdf, accessed 9 December 2005.
D. Dreilinger and A.E. Howe, 1997. “Experiences with selecting search engines using meta–search,” ACM Transactions on Information Systems, volume 15, number 3, pp. 195–222; and at http://daniel.www.media.mit.edu/people/daniel/papers/ms.ps.gz, accessed 1 April 2000.
Y. Fan and S. Gauch, 1999. “Adaptive agents for information gathering from multiple, distributed information sources,” Proceedings of 1999 AAAI Symposium on Intelligent Agents in Cyberspace (Stanford University); and at http://www.ittc.ku.edu/~sgauch/papers/AAAI99.html, accessed 9 December 2005.
J.C. French, A.L. Powell, C.L. Viles, T. Emmit, and K.J. Pray, 1998. “Evaluating database selection techniques: A testbed and experiments,” Proceedings of the 21st ACM SIGIR Conference on Information Retrieval (SIGIR ”98), pp. 121–129.
J.C. French, A.L. Powell, and J. Callan, 1999a. “Effective and efficient automatic database selection,” Technical Report CS–99–08, Dept. of Computer Science, Univ. of Virginia, at http://www.cs.virginia.edu/~alp4g/publications.html, accessed 9 December 2005.
J.C. French, A.L. Powell, J. Callan, C.L. Viles, T. Emmit, K.J. Pray, and Y. Mou, 1999b. “Comparing the performance of database selection algorithms,” Proceedings of the 22nd ACM SIGIR Conference on Information Retrieval (SIGIR ”99), pp. 238–245, and at http://www.cs.virginia.edu/~cyberia/papers/SIGIR99.ps, accessed 2 April 2003.
I. Gaslikova, 1999. “Information seeking in context and the development of information systems,” Information Research, volume 5, number 1, at http://www.shef.ac.uk/~is/publications/infres/paper67.html, accessed 9 December 2005.
S. Gauch, G. Wang, and M. Gomez. 1996. “ProFusion: Intelligent fusion from multiple, distributed search engines,” Journal of Universal Computer Science, volume 2, number 9, at http://www.ittc.ku.edu/~sgauch/papers/JUCS96.html, accessed 9 December 2005.
J. Gelernter, 2003. “At the limits of Google: Specialized search engines,” Searcher, volume 11, pp. 26–31.
C.A. Germain, 2000. “URLs: Uniform resource locators or unreliable resource locators?” College and Research Libraries, volume 61, pp. 359–365.
A. Gilad, 1999. “Internet search patterns,” Unpublished master’s thesis, Tel Aviv University (Israel).
E.J. Glover, G.W. Flake, S. Lawrence, A. Kruger, D.M. Pennock, W.P. Birmingham, and C.L. Giles, 2001. “Improving category specific Web search by learning query modifications,” 2001 Symposium on Applications and the Internet (SAINT ’01), p. 23.
M. Gray, 1996. “Measuring the growth of the Web: June 1993 to June 1995,” at http://www.mit.edu/people/mkgray/growth/, accessed 9 December 2005.
R. Greenspan, 2002. “Health, finance sites lack credibility,” at http://www.clickz.com/stats/sectors/healthcare/article.php/10101_1496801, accessed 9 December 2005.
U. Hanani and A.J. Frank, 2000. “The parallel evolution of search engines and digital libraries: Their convergence to the mega–portal,” Kyoto International Conference on Digital Libraries (ICDL ’00), pp. 269–276.
S. Harter and C. Hert, 1997. “Evaluation of information retrieval systems: Approaches, issues and methods,” Annual Review of Information Science and Technology, volume 32, pp. 3–94.
C.R. Hildreth, 1989. Intelligent interfaces and retrieval methods for subject search in bibliographic retrieval systems. Washington, D.C.: Cataloging Distribution Service, Library of Congress.
C. Hoelscher, 1998. “How Internet experts search for information on the Web,” Proceedings of WebNet98 — World Conference of the WWW, Internet & Intranet.
Health on the Net Foundation, 1999. “Fifth HON survey on the evolution of Internet use for health purposes,” at ttp://www.hon.ch/Survey/ResultsSummary_oct_nov99.html, accessed 10 December 2005.
A.E. Howe and D. Dreilinger, 1997. “SavvySearch: A meta–search engine that learns which search engines to query,” AI Magazine, volume 18, number 2, pp. 19–25.
B.J. Jansen, 2000. “The effect of query complexity on Web searching results,” Information Research, volume 6, number 1, at http://informationr.net/ir/6-1/paper87.html, accessed 10 December 2005.
B.J. Jansen and U. Pooch, 2000. “Web user studies: A review of current and framework for future work,” Journal of the American Society of Information Science and Technology, volume 52, number 3, pp. 235–246; and at http://jimjansen.tripod.com/academic/pubs/wus.html, accessed 10 December 2005.
N. Kaminer, 1997. “Scholars and the use of the Internet,” Library and Information Science Research, volume 19, number 4, pp. 329–345.
J. Katz and P. Aspden, 1997. “Motivations for and barriers to Internet usage: Results of a national opinion survey,” Internet Research, volume 7, number 3, pp. 170–188.
J.M. Kleinberg, 1998. “Authoritative sources in a hyperlinked environment,” Proceedings of the ACM–SIAM Symposium on Discrete Algorithms; and at http://www.cs.cornell.edu/home/kleinber/auth.pdf, accessed 10 December 2005.
W. Koehler, 2002. “Web page change and persistence: A four year longitudinal study,” Journal of the American Society for Information Science and Technology, volume 53, pp. 162–161.
W. Koehler, 1999. “An analysis of Web page and Web site constancy and permanence,” Journal of the American Society for Information Science, volume 50, pp. 162–180.
R. Kraut, W. Scherlis, T. Mukhopadhyay, J. Manning, and S. Kiesler, 1996. “The HomeNet field trial of residential Internet services,” Communications of the ACM, volume 39, pp. 55–63.
A. Kruger, C.L. Giles, F.M. Coetzee, E. Glover, G.W. Flake, S. Lawrence, and C. Omlin, 2000. “DEADLINER: Building a new niche search engine,” Conference on information and knowledge management (Washington, D.C.).
F.W. Lancaster, 1972. Vocabulary control for information retrieval. Washington, D.C.: Information Resources Press.
F.W. Lancaster, 1969. “MEDLARS: Report on the evaluation of its operating efficiency,” American Documentation, volume 20, number 2, pp. 119–142.
S. Lawrence and C.L. Giles, 1999. “How big is the Web? How much of the Web do the search engines index? How up to date are the search engines?” at http://www.cs.biu.ac.il/home/search/studies/lawrence.htm, accessed 10 December 2005.
S. Lawrence, C.L. Giles, and K. Bollacker, 1999. “Digital libraries and autonomous citation indexing,” IEEE Computer, volume 32, number 6, pp. 67–71; and at http://citeseer.ist.psu.edu/aci-computer/aci-computer99.html, accessed 10 December 2005.
S. Lawrence and C.L. Giles, 1998. “Inquirus, the NECI meta search engine,” Proceedings of the Seventh International World Wide Web Conference, pp. 95–105.
S.S. Lazinger, J. Bar–Ilan, and B.C. Peritz, 1997. “Internet use by faculty members in various disciplines: A comparative case study,” Journal of the American Society for Information Science, volume 48, number 6, pp. 508–518.
S. Mizzaro, 1997. “Relevance: The whole history,” Journal of the American Society for Information Science, volume 48, number 9, pp. 810–832.
J.Morahan–Martin, 1998. “Women and girls last: Females and the Internet,” Proceedings of IRISS ’98, at http://www.sosig.ac.uk/iriss/papers/paper55.htm, accessed 10 December 2005.
E. O’Neill and B. Lavoie, 2000. “OCLC researchers measure the World Wide Web,” OCLC Newsletter, number 248, p. 25.
K. Ray and J. Day, 1988. “Students attitudes towards electronic information resources,” Information research, volume 4, number 2, at http://informationr.net/ir/4-2/paper54.html, accessed 10 December 2005.
J. Shakes, M. Langheinrich, and O. Etzioni, 1997. “Dynamic reference sifting: a case study in the homepage domain,” Selected papers from the sixth international conference on World Wide Web, pp. 1193–1204.
C. Sherman and G. Price, 2001. The invisible Web: Uncovering information sources search engines can’t see. Medford, N.J.: CyberAge Books.
A. Spink, H. Greisdorf, and J. Bateman, 1998. “From highly relevant to not relevant: Examining different regions of relevance,” Information Processing and Management, volume 34, number 5, pp. 599–621.
T. Spring, 2004. “Search tangles: Internet search is big business. But the drive for profits by search firms and the sites they index is taking its toll on the results in your browser,” PC World (August), http://www.pcworld.com/news/article/0,aid,116641,00.asp, accessed 10 December 2005.
R. Steele, 2001. “Techniques for specialized search engines,” at http://www-staff.it.uts.edu.au/~rsteele/SpecSearch3.pdf, accessed 10 December 2005.
S. Stobart and S. Kerridge, 1996. “An investigation into World Wide Web search engine use from within the UK — preliminary findings,” Ariadne, issue 6, at http://www.ariadne.ac.uk/issue6/survey, accessed 10 December 2005.
J. Tillotson, J. Cherry, and M. Clinton, 1995. “Internet use through the University of Toronto library: Demographics, destinations, and users’ reactions,” Information Technology and Libraries, volume 14, number 3, pp. 190–198.
P. Vakkari and E. Somunen, 2004. “The influence of relevance levels on the effectiveness of interactive information retrieval,” Journal of the American Society for Information Science and Technoogy, volume 55, number 11, pp. 963–969.
C.M. White, 1995. “Users and impacts of computer mediated communication: A survey of faculty in mass communication and related disciplines,” doctoral dissertation, University of Georgia.
M.S. Wolcott, 1998. “Information–seeking and the World Wide Web: A qualitative study of seventh–grade students’ search behavior during an inquiry activity,” doctoral dissertation, University of San Francisco, Faculty of the School of Education Learning and Instruction.
D. Young and B. Shneiderman, 1993. “A graphical filter/flow model for Boolean queries,” Journal of the American Society for Information Science, volume 44, pp. 327–339.
B. Yuwono and D.L. Lee. 1997. “Server ranking for distributed text retrieval systems on the Internet,” Proceedings of the Fifth International Conference on Database Systems for Advanced Applications (DASFAA ’97), pp. 41–49.
Editorial history
Paper received 20 October 2005; accepted 18 November 2005.

This work is licensed under a Creative Commons Attribution-NonCommercial-NoDerivs 2.5 License.Finding information on the free World Wide Web: A specialty meta–search engine for the academic community by Yaffa Aharoni, Ariel J. Frank and Snunith Shoham
First Monday, volume 10, number 12 (December 2005),
URL: http://firstmonday.org/issues/issue10_12/aharoni/index.html