by Björn Hermans 
Table of Contents | Previous Chapters | Next Chapters
Chapter 4: The Three Layer Model
Chapter 5: Past and Current Agent Trends & Developments
Bibliography
NotesIntroduction
"The information superhighway directly connects millions of people, each both a consumer of information and a potential provider. If their exchanges are to be efficient, yet protected on matters of privacy, sophisticated mediators will be required. Electronic brokers can play this important role by organizing markets that promote the efficient production and consumption of information. [ 40 ]"
Although the Internet provides access to huge amounts of information, the information sources, at this moment, are too diverse and too complex for most users to use them to their full extent. L. Daigle noted that "Currently, the World Wide Web (WWW) is the most successful effort in attempting to knit all these different information resources into a cohesive whole that can be interfaced through special documents (called Web pages or hyper/HTML documents). The activity best-supported by this structure is (human) browsing through these resources by following references (so-called hyper links) in the documents. [ 41 ]" Nevertheless, Daigle pointed out [ 42 ], "the WWW & the Internet do not adequately address more abstract activities such as information management, information representation, or other processing of (raw) information."
In order to support these activities with increasingly complex information resources (such as multi-media objects, structured documents, and specialised databases), the next generation of network services infrastructure will have to be interoperable at a higher level of information activity abstraction. This may be fairly evident in terms of developing information servers and indexes that can interact with one another, or that provide a uniform face to the viewing public (e.g., through the World Wide Web). However, an information activity is composed of both information resources and needs. It is therefore not enough to make resources more sophisticated and interoperable; we need to be able to specify more complex, independent client information processing tasks [ 43 ].
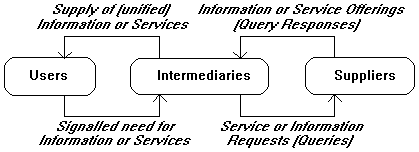
Daigle described an experimental architecture that can satisfy both needs as were just described [ 44 ]. In this architecture the information search process is divided into three layers: one layer for the client side of information (information searchers), one for the supply or server side of information (information providers), and one layer between these two layers to connect them in the best possible way(s) (the middle layer [ 45 ]).
Daigle is not alone in her ideas: several other parties are doing research into this concept or concepts very similar to it [ 46 ]. The Fact is that more and more persons are beginning to realise that the current structure of the Internet, which is more or less divided into two layers or parties (being users and suppliers) is more and more failing to be satisfactory.
Definition
Currently, when someone is looking for certain information on the Internet, there are many possible ways to do that. One of the possibilities that we have seen earlier, are search engines.
The problem with these is that:
- They require a user to know how to best operate every individual search engine;
- A user should know exactly what information he is looking for;
- The user should be capable of expressing his information need clearly (with the right keywords).
However, many users do neither know exactly what they are looking for, nor do they have a clear picture of which information can and which cannot be found on the Internet, nor do they know what the best ways are to find and retrieve it.
A supplier of services and/or information is facing similar or even bigger problems. Technically speaking, millions of Internet users have access to his service and/or information. In the real world however, things are a little more complicated. Services can be announced by posting messages on Usenet, but this is a 'tricky business' as most Usenet (but also Internet) users do not like to get unwanted, unsolicited messages of this kind (especially if they announce or recommend commercial products or services). Another possibility to draw attention to a service is buying advertising space on popular sites (or pages) on the World Wide Web. Even if thousands of users see such a message, it still remains to be seen whether or not these users will actually use the service or browse the information that is being offered. Even worse: many persons that would be genuinely interested in the services or information offered (and may even be searching for it), are reached insufficiently or not reached at all.
In the current Internet environment, the bulk of the processing associated with satisfying a particular need is embedded in software applications (such as WWW browsers). It would be much better if the whole process could be elevated to higher levels of sophistication and abstraction.
Several researchers have addressed this problem. One of the most promising proposals is a model where activities on the Internet are split up into three layers: one layer per activity.
Figure 2 - Overview of the Three Layer ModelPer individual layer the focus is on one specific part of the activity (in case of this thesis and of figure 2: an information search activity), which is supported by matching types of software agents. These agents will relieve us of many tedious, administrative tasks, which in many cases can be taken over very well, or even better, by a computer program (i.e. software agents). What's more, the agents will enable a human user to perform complex tasks better and faster.
The three layers are:
1. The demand side (of information), i.e. the information searcher or user; here, agents' tasks are to find out exactly what users are looking for, what they want, if they have any preferences with regard to the information needed, etcetera;
2. The supply side (of information), i.e. the individual information sources and suppliers; here, an agent's tasks are to make an exact inventory of (the kinds of) services and information that are being offered by its supplier, to keep track of newly added information, etcetera;
3. Intermediaries; here agents mediate between agents (of the other two layers), i.e. act as (information) intermediaries between (human or electronic) users and suppliers.
When constructing agents for use in this model, is it absolutely necessary to do this according to generally agreed upon standards: it is unfeasible to make the model account for any possible type of agent. Therefore, all agents should respond & react in the same way (regardless of their internal structure) by using some standardised set of codes. To make this possible, the standards should be flexible enough to provide for the construction of agents for tasks that are unforeseen at present time.
The three layer model has several (major) plus points:
1. Each of the three layers only has to concern itself with doing what it is best at. Parties (i.e. members of one of the layers) do no longer have to act as some kind of "jack-of-all-trades";
2. The model itself (but the same goes for the agents that are used in it) does not enforce a specific type of software or hardware. The only thing that has to be complied to are the standards that were mentioned earlier. This means that everybody is free to chose whatever underlying technique they want to use (such as the programming language) to create an agent: as long as it responds and behaves according to the specifications laid down in the standards, everything is okay. A first step in this direction has been made with the development of agent communication and programming languages such as KQML and Telescript. Yet, a lot of work has to be done in this area as most of the current agent systems do not yet comply to the latter demand: if you want to bring them into action at some Internet service, this service needs to have specific software running that is able to communicate and interact with that specific type of agent. And because many of the current agent systems are not compatible with other systems, this would lead to a situation where an Internet service would have to possess software for every possible type of agent that may be using the service: a most undesirable situation;
3. By using this model the need for users disappears to learn the way in which the individual Internet services have to be operated; the Internet and all of its services will 'disappear' and become one cohesive whole;
4. It is easy to create new information structures or to modify existing ones without endangering the open (flexible) nature of the whole system. The ways in which agents can be combined become seemingly endless;
5. To implement the three layer model no interim period is needed to do so, nor does the fact that it needs to be backward-compatible with the current (two layer) structure of the Internet have any negative influences on it. People (both users and suppliers) who chose not to use the newly added intermediary or middle layer, are free to do so. However, they will soon discover that using the middle layer in many cases leads to quicker and better results in less time and with less effort. (More about this will follow in the next sections.)
The "only" current deficiency of this model is the lack of generally agreed upon standards, such as one for the used agent communication language. Such standards are a major issue for the three layer model, as they ensure that (agents in) the individual layers can easily interface with (agents in) the other ones. Organisations such as the Internet Engineering Task Force (IETF) and its work groups have been, and still are, addressing this issue.
The Functions of the middle layer
Recently, a lot of work has been done to develop good user interfaces to the various services on the Internet, and to enhance existing ones. However, the big problem with most of the services is that they are too strongly aimed at catering for the broadest possible range of users. This approach goes all wrong as services become either too complicated for novice users, or too tedious and limited for expert users. Sometimes the compromises that have been made are so big, that a service is not really suitable for either of them. The Internet services of the future should aim at exactly the opposite with tailor-made services (and interfaces) for every individual user as the ultimate target. Neither the suppliers nor the users of these services should be responsible for accomplishing this, as this would - once again - lead to many different techniques and many different approaches, and would lead to parties (users and suppliers) trying to solve problems they should not be dealing with in the first place. Instead, software agents will perform these tasks and address these problems.
In this section it will be explained why the middle layer will become an inevitable, necessary addition to the current two layer Internet, and an example will be given to give an impression of the new forms of functionality it can offer.
Middle layer (agent) functions
"The fall in the cost of gathering and transmitting information will boost productivity in the economy as a whole, pushing wages up and thus making people's time increasingly valuable. No one will be interested in browsing for a long while in the Net trying in whatever site whatever information! He wants just to access the appropriate sites for getting good information."from "Linguistic-based IR tools for W3 users" by Basili and Pazienz
The main functions of the middle layer are:
1. Dynamically matching user demand and provider's supply in the best possible way. Suppliers and users (i.e. their agents) can continuously issue and retract information needs and capabilities. Information does not become stale and the flow of information is flexible and dynamic. This is particularly useful in situations where sources and information change rapidly, such as in areas like commerce, product development and crisis management.
2. Unifying and possibly processing suppliers' responses to queries to produce an appropriate result. The content of user requests and supplier 'advertisements' [ 47 ] may not align perfectly. So, satisfying a user's request may involve aggregating, joining [ 48 ] or abstracting the information to produce an appropriate result. However, it should be noted that normally intermediary agents should not be processing queries, unless this is explicitly requested in a query [ 49 ].
Processing could also take place when the result of a query consists of a large number of items. Sending all these items over the network to a user (agent), would lead to undesirable waste of bandwidth, as it is very unlikely that a user (agent) would want to receive that many items. The intermediary agent might then ask the user (agent) to make refinements or add some constraints to the initial query.
3. Current Awareness, i.e. actively notificate users of information changes. Users will be able to request (agents in) the middle layer to notificate them regularly, or maybe even instantly, when new information about certain topics has become available or when a supplier has sent an advertisement stating he offers information or services matching certain keywords or topics.
There is quite some controversy about the question whether or not a supplier should be able to receive a similar service as well, i.e. that suppliers could request to be notified when users have stated queries, or have asked to receive notifications, which match information or services that are provided by this particular supplier. Although there may be users who find this convenient, as they can get in touch with suppliers who can offer the information they are looking for, there are many other users which would not be very pleased with this invasion on their privacy. Therefore, a lot of thought should be given to this dilemma and a lot of things will need to be settled, before such a service should be offered to suppliers as well.
4. Bring users and suppliers together. This activity is more or less an extension of the first function. It means that a user may ask an intermediary agent to recommend/name a supplier that is likely to satisfy some request without giving a specific query. The actual queries then take place directly between the supplier and the user. Or a user might ask an intermediary agent to forward a request to a capable supplier with the stipulation that subsequent replies are to be sent directly to the user himself.
These functions (with exception of the second one) bring us to an important issue: the question whether or not a user should be told where and from whom requested information has been retrieved. In case of, say, product information, a user would certainly want to know this. Whereas with, say, a request for bibliographical information, the user would probably not be very interested in the specific, individual sources that have been used to satisfy the query. Suppliers will probably like to have direct contact with users (that submit queries) and would like to by-pass the middle layer (i.e. intermediary agent). Unless a user specifically request to do so (as is the case with the fourth function), it would probably not be such a good idea to fulfil this supplier's wish. It would also undo one of the major advantages of the usage of the middle layer: eliminating the need to interface with every individual supplier yourself.
At this moment, many users use search engines to fulfil their information need. There are many search engines available, and quite a lot of them are tailored to finding specific kinds of information or services, or are aimed at a specific audience (e.g. at academic researchers).
Suppliers use search engines as well. They can, for instance, "report" the information and/or services they offer to such an engine by sending the URL of it to the search engine. Or suppliers can start up a search engine (i.e. information service) of their own, which will probably draw quite some attention to their organisation (and its products, services, etcetera), and may also enable them to test certain software or hardware techniques.
Yet, although search engines are a useful tool at this moment, their current deficiencies will show that they are a mere precursor for true middle layer applications. In Chapter 1, we saw a list of the general deficiencies of search engines (compared to software agents). But what are the specific advantages of usage of the middle layer over search engines, and how does the former take the latter's limitations away (completely or partially)?
- Middle layer agents and applications will be capable of handling, and searching in, information in a domain dependent way. Search engines treat information domain-independently (they do not store any meta-information about the context information has been taken from), whereas most supplier services, such as databases, offer (heavily) domain-dependent information. Advertisements that are sent to middle layer agents, as well as any other (meta-)information middle layer agents gather, will preserve the context of information (terms) and make it possible to use the appropriate context in such tasks as information searches (see next point).
- Middle layer agents do not (like search engines) contain domain specific knowledge, but obtain this from other agents or services, and employ it in various sorts of ways. Search engines do not contain domain specific knowledge, nor do they use it in their searches. Middle layer agents will not possess any domain specific knowledge either: they will delegate this task to specialised agents and services. If they receive a query containing a term that matches no advertisement (i.e. supplier description) in their knowledge base, but the query does mention which context this term should be interpreted in, they can farm out the request to a supplier that indicated he offers information on this more general concept (as it is likely to have information about the narrow term as well) [ 50 ]. If a query term does not match any advertisement, specialised services (e.g. a thesaurus service, offered by a library) can be employed to get related terms and/or possible contexts. Or the user agent could be contacted with a request to give (more) related terms and/or a term's context.
- Middle layer agents and applications are better capable of dealing with the dynamic nature of the Internet, and the information and services that are offered on it. Search engines hardly ever update the (meta-)information that has been gathered about information and service suppliers and sources. The middle layer (and its agents), on the other hand, will be well capable of keeping information up-to-date. Suppliers can update their advertisements whenever and as often as they want. Intermediary agents can update their databases as well, for instance by removing entries that are no longer at their original location (it may be expected that future services will try to correct/update such entries, if possible). They may even send out special agents to find new suppliers/sources to add to the knowledge base. Furthermore, this information gathering process can be better co-ordinated (compared to the way search engines operate) in that a list is maintained of domains/sites/servers information has been gathered about (which avoids double work from being done).
- Middle layer agents will be able to co-operate and co-ordinate efforts better than search engines do now. The individual search engines do not co-operate. As a result of this, a lot of time, bandwidth and energy is being wasted by search engines working in isolation. Middle layer agents will try to avoid doing so, by co-operating with other agents (in both the middle as well as the supplier layer) and by sharing knowledge and gathered information (such as advertisements). One possibility to achieve this could be the construction of a few "master" middle layer agents, which receive all the queries and advertisements from all over the world and act as a single interface towards both users and suppliers. The information in advertisements and user queries is distributed or farmed out to specialised middle layer agents. These "master" middle layer agents could also contact supporting agents/services (such as the earlier mentioned thesaurus service), and would only handle those requests and advertisements that no specialised agent has (yet) been constructed for. In fairness it should be remarked that expected market forces will make it hard to reach this goal. We will come back to this in a later section of this chapter.
- Middle layer agents are able to offer current awareness services. Search engines do not offer such services as current awareness. Middle layer agents and applications will be able to inform users (and possibly suppliers) regularly about information changes regarding certain topics.
- Middle layer agents are not impeded in their (gathering) activities by (suppliers') security barriers. Many services do not give a search engine's gathering agents access to (certain parts of) their service, or do - in case of a total security barrier such as a firewall - not give them access at all. As a result of this, a lot of potentially useful information is not known to the search engine (i.e. no information about it is stored in its knowledge base), and thus the information will not appear in query results.
In the three layer model, suppliers can provide the middle layer with precise information about offered services and/or information. No gathering agent will need to enter their service at all, and thus no security problems will arise on this point.
An Example of a future middle layer query
To give an idea of how the middle layer can contribute to (better) solve queries, we will have a look at a fictitious example.Mister Jones wants to buy another car, as his old one has not been performing very well lately. The old car is a Ford, and as Mr. Jones has been very pleased with it, the new car will have to be a Ford as well. However, as he turns to his personal software agent for information, he (unintendedly) does not ask for information about "Fords" that are for sale, but about "cars". So the user agent sends out a query to an intermediary agent for information about cars which are for sale.
The intermediary agent checks its database for advertisements that mention information about "cars", "sale" and "for sale". It sends out requests to suppliers offering this information. The individual supplier's responses are unified into a single package, and maybe the entries are sorted according to some criteria [ 51 ]. Then they are sent to the user agent.
The user agent receives the response ("answer") from the intermediary agent, and presents the information to mister Jones. The user agent soon discovers that he only looks at those entries that are about Fords, so it concludes that he is interested in "Fords", rather than in "cars" in general. As a result of this, it sends out a new query, specifically asking for information about "Fords".
The intermediary agent receives the query, and finds that it has no advertisements in its database yet, that mention Fords. The intermediary agent may now be able to resolve this query because the query of the user agents mentions that one of the attributes of a "Ford" is that it is a kind of automobile, or - if this is not the case - it could send out a query to a thesaurus service asking for more general terms that are related to the word "Ford" (and get terms such as "car" and "automobile" as a result of this query). The agent can then send a query to one or more suppliers which say they offer information about "cars" and/or "automobiles", specifying it wants specific information about Fords.
Supplier agents that receive this query, and which indeed have information about Fords, will then send back the requested information. Furthermore, the supplier's agent can now decide to send a message (i.e. 'advertisement') to the intermediary agent, telling it that it offers information on Fords as well. The intermediary agent, again, unifies all responses into a single package, and sends it to the user agent, which will present it to the user.
This is just one way in which such a query might be handled. There are many alternative paths that could have been followed. For instance, the user agent might have stored in the user model of mister Jones that he owns a Ford, or that he has quite often searched for information about Fords. So in its first query it would not only have requested information about "cars", but about "Fords" that are for sale as well.
What this example shows us, is how agents and the middle layer/three layer model can conceivably contribute to make all kinds of tasks more efficient, quicker, etcetera.
Computer and human intermediaries
Introduction
"Electronic brokers will be required to permit even reasonably efficient levels and patterns of exchanges. Their ability to handle complex, albeit mechanical, transactions, to process millions of bits of information per second, and to act in a demonstrably even-handed fashion will be critical as this information market develops. [ 52 ]"When necessary, human information searchers usually seek help from information intermediaries such as a librarian. More wealthy or more hasty information searchers, e.g. large companies and institutions (for which "time is money"), call in information brokers [ 53 ]. Both types of information searchers realise it is much better to farm out this task to intermediaries as they possess the required (domain-specific) knowledge, are better equipped to do the task, or because it simply is not their core business. It is only logical to follow this same line of thought when information on the Internet is needed.
The availability of safe payment methods on the Internet (which make it possible to charge users of an information service for each piece of information they download) will be a big incentive to make use of electronic intermediaries (and agents in general too) as searching for information and/or services in an "unintelligent" way will then not only cost time, it will also cost money. Moreover, weighing the pros and cons of several information providers becomes a very complicated task if you have to take their prices into account as well: (intermediary) agents are (very soon) much better at doing this compared to their human user, especially as they can take the various user preferences into account as well when deciding which provider is most suitable, and they are better able to keep an overview of all the possible suppliers (and their prices).
Five important limitations of privately negotiated transactions are given which intermediaries, whether human or electronic, can redress [ 54 ]:
- Search costs.
It may be expensive for suppliers and users to find each other. On the Internet, for example, thousands of products are exchanged among millions of people. Brokers can maintain databases of user preferences and supplier (i.e. provider) advertisements, and reduce search costs by selectively routing information from suppliers to users.
Furthermore, suppliers may have trouble accurately gauging user demands for new products; many desirable items or services may never be offered (i.e. produced) simply because no one recognises the demand for them. Brokers with access to user preference data can predict demand.
- Lack of privacy.
Either the "buyer" or "seller" may wish to remain anonymous, or at least to protect some information relevant to an exchange. Brokers can relay messages without revealing the identity of one or both parties. A broker can also make pricing and allocation decisions based on information provided by two or more parties, without revealing the information of any individual party.
- Incomplete information.
The user may need more information than the supplier is able or willing to provide, such as information about product quality or customer satisfaction. A broker can gather product information from sources other than the product or service provider, including independent evaluators and other users.
- Contracting risk.
A consumer (user) may refuse to pay after receiving a product, or a supplier may give inadequate post-purchase service. Brokers have a number of tools to reduce risk:
1. The broker can disseminate information about the behaviour of providers and consumers. "The threat of publicising bad behaviour or removing some seal of approval may encourage both producers and consumers to meet the broker's standard for fair dealing";
2. If publicity is insufficient, the broker may accept responsibility for the behaviour of parties in transactions it arranges, and act as a policeman on his own;
3. The broker can provide insurance against bad behavior.
(The credit card industry already uses all three tools to reduce providers' and consumers' exposure to risk.)
- Pricing Inefficiencies.
By jockeying to secure a desirable price for a product, providers and consumers may miss opportunities for mutually desirable exchanges. "This is particularly likely in negotiations over unique or custom products, such as houses, and markets for information products and other public goods, where free-riding is a problem. Brokers can use pricing mechanisms that induce just the appropriate exchanges" [ 55 ].
The Internet offers new opportunities for such intermediary/brokering services. Both human as well as electronic brokers are especially valuable when the number of participants is enormous (as with the stock market) or when information products are exchanged. Electronic brokers can offer two further opportunities over human ones. Firstly, many brokering services require information processing; electronic versions of these services can offer more sophisticated features at a lower cost than is possible with human labour. Secondly, for delicate negotiations, a computer mediator may be more predictable, and hence more trustworthy, than a human one [ 56 ].
Intermediary/Broker Issues
Intermediary agents (i.e. brokers) force us to address some important policy questions [ 57 ].
- How do we weigh privacy and censorship concerns against the provision of information in a manageable form?
Whenever information products are brokered, privacy and censorship issues come to the fore. An electronic intermediary or agent can be of great help here, as it can more easily perform potentially troubling operations involving large amounts of data processing;
- Should intermediaries be allowed to ask a fee for their services?
Should providers or intermediary services be permitted to charge fees, even if the information providers may not or do not? "Much of the information now exchanged on the Internet is provided free of charge and a spirit of altruism pervades the Internet community. At first glance, it seems unfair that an intermediary should make a profit by identifying information that is available for free, and some Internet user groups would likely agitate for policies to prevent for-profit brokering." But so long as the use of brokering services is voluntary, it helps some information seekers without hurting any others: anyone who does not wish to pay can still find the same information through other means, at no charge. Moreover: one pays for finding, not for the information itself. This is a well known problem also in the traditional/paper world.
- Should intermediary activities be organised as a monopoly (for the sake of effectiveness) or should competitive parties provide them?
With intermediary, but especially with brokerage services, there is a tension between the advantages of competition and those of monopoly provision. Firstly, a competitive market with many brokers will permit the easy introduction of innovations and the rapid spread of useful ones. Because of the rapid spread, however, the original innovator may gain little market advantage and so may have little reason to innovate in the first place. Patents or other methods of ensuring a period of exclusive use for innovations may be necessary.
Secondly, some services may be a natural monopoly (because of the nature of the services or information they deal with). Similarly, auction and other pricing services may be most effective if all buyers and sellers participate in the same market. One solution might be for all evaluations to be collected in one place, with brokers competing to sell different ways to aggregate them.
More generally: some aspects of brokering may be best organised as monopolies; others should be competitive.
Human versus Electronic Intermediaries
Some think that computer (i.e. agent) intermediaries will replace human intermediaries. This is rather unlikely, as they have quite different qualities and abilities. It is far more likely that they will co-operate closely, and that there will be a shift in the tasks (i.e. queries) that both types handle. Computer agents (in the short and medium term) will handle standard tasks and all those tasks that a computer program (i.e. an agent) can do faster or better than a human can. Human intermediaries will handle the (very) complicated problems, and will divide these tasks into sub-tasks that can (but not necessarily have to) be handled by intermediary agents.It may also be expected that many commercial parties (e.g. human information brokers, publishers, etcetera) will want to offer middle layer services. Although the most ideal situation would be one where the middle layer has one single contacting point for parties and agents from the other two layers, it is very unlikely that this will happen. However, this is not such a big problem as it looks, as it will also keep the levels of competition high (which very likely leads to better and more services being offered to both suppliers and users). Also, having more than one service provider in the middle layer does not mean that efforts will not be co-ordinated and that parties will not co-operate, as doing so not only enables them to offer better services, they will also be able to cut back on certain costs.
It lies outside the scope of this paper to treat this subject in more detail. Further research is needed into this area, among others to make more reliable predictions about future developments with regard to these ("intermediary") issues.
An Example of a middle layer application: Matchmaking
Daniel Kuokka and Larry Harada describe an agent application whereby potential producers and consumers of information send messages describing their information capabilities and needs to an intermediary called a matchmaker [ 58 ]. These descriptions are unified by the matchmaker to identify potential matches. Based on the matches, a variety of information brokering services are performed. Kuokka and Harada argue that matchmaking permits large numbers of dynamic consumers and providers, operating on rapidly-changing data, to share information more effectively than via traditional methods.Unlike the traditional model of information pull, Matchmaking is based on a co-operative partnership between information providers and consumers, assisted by an intelligent facilitator (the matchmaker). Information providers and consumers update the matchmaker (or network of matchmakers) with their needs and capabilities. The matchmaker, in turn, notifies consumers or producers of promising "partners". Matchmaking is an automated process depending on machine-readable communication among the consumers, providers, and the matchmakers. Thus, communication must occur via rich, formal knowledge sharing languages [ 59 ].
The main advantage of this approach is that the providers and consumers can continuously issue and retract information needs and capabilities, so information does not tend to become stale and the flow of information is flexible and dynamic. This is particularly critical in situations where sources and information change rapidly.
There are two distinct levels of communication with a matchmaker: the message type (sometimes called the speech act) and the content. The former denotes the intent of the message (e.g., query or assertion) while the latter denotes the information being exchanged (e.g., what information is being queried or asserted).
There is a variety of message types. For example, information providers can take an active role in finding specific consumers by advertising their information capabilities to a matchmaker. Conversely, consumers send requests for desired information to the matchmaker. As variations on this general theme, the consumer might simply ask the matchmaker to recommend a provider that can likely satisfy the request. The actual queries then take place directly between the provider and consumer. The consumer might ask the matchmaker to forward the request to a capable provider with the stipulation that subsequent replies are to be sent directly to the consumer. Or, the consumer might ask the matchmaker to act as an intermediary, forwarding the request to the producer and forwarding the reply to the consumer [ 60 ].
Since the content of requests and advertisements may not align perfectly, satisfying a request might involve aggregating or abstracting the information to produce an appropriate result. For example, if a source advertises information about automobiles while a consumer requests information about Fords, some knowledge and inference is required to deduce that a Ford is an automobile. Such transformation of data is an important capability, but its addition to a matchmaker must be carefully weighed. If knowledge about automobiles were added to a matchmaker, similar knowledge could be added about every other possible topic. Obviously, this would quickly lead to an impractically large matchmaker. Therefore, a matchmaker as such does not strictly contain any domain knowledge. However, a matchmaker is free to use other mediators and data sources in determining partners. Thus, it could farm out the automobile/Ford example to an automobile knowledge base to determine if a match exists.
To evaluate and test the matchmaking approach, two prototype matchmakers have been built. The first matchmaker was designed and prototyped as part of the SHADE system, a testbed for integrating heterogeneous tools in large-scale engineering projects. It operates over formal, logic-based representations, and is designed to support many different types of requests and advertisements. A second matchmaker was created as an element of the COINS system (Common Interest Seeker). The emphasis of this matchmaker is on matching free text rather than formal representations.
Both matchmakers run as processes accepting and responding to advertisements and requests from other processes. Communication occurs via KQML, which defines specific message types (historically known as performatives) and semantics for advertising and requesting information. KQML message types include simple queries and assertions (e.g., ask, stream, and tell), routing and flow instructions (e.g., forward and broadcast), persistent queries (e.g., subscribe and monitor), and information brokering requests (e.g., advertise, recommend, recruit, and broker), which allow information consumers to ask a facilitator (Matchmaker) to find relevant information producers.
These two types of matchmakers were developed separately due to the differences between their content languages (logic vs. free text), and the resulting radical impact on the matching algorithms. They could, in principle, be integrated, but just as a matchmaker uses other agents for domain-specific inference, it is preferable to keep them separated, rather than creating one huge matchmaker. If desired, a single multi-language matchmaker may be implemented via a simple dispatching agent that farms out requests to the appropriate matchmaker. This approach allows many matchmakers, each created by researchers with specific technical expertise, to be specialised for specific classes of languages.
Experiments with matchmakers have shown matchmaking to be most useful in two different ways:
1. Locating information sources or services that appear dynamically; and 2. Notification of information changes.
A third benefit, that of allowing producers of information to actively seek potential consumers, has only been partially demonstrated. Nevertheless, provided that user (but also producer) privacy can be guaranteed, this capability can attract the attention of many information providers [ 61 ]. Yet, even though matchmaking has proven very useful in the above applications, several important shortcomings have been uncovered. Whereas queries can be expressed succinctly, expressing the content of a knowledge base (as in an advertisement) is a much harder problem. Current formal content languages are adequate for the simple examples shown above, but to go beyond advertising simple attributes quickly strains what can be represented. Additional research is required on ever more powerful content languages. The COINS matchmaker is, of course, not limited by representation. Here, the efficiency and efficacy of free-text matching becomes a limiting factor.
It should be noted that Matchmaking is a special type of middle layer application as it does not use any domain-specific knowledge. It also is not an agent application really: it farms out tasks/queries to specialised, or otherwise most suitable agents for that specific problem (i.e. query). Matchmakers could, however, play an important role as a sort of universal interface to the middle layer for both user as well as supplier agents or agent applications as they do not have to figure out which middle layer agents are best to be contacted.
Summary
The current two layer structure of the Internet (one layer for the demand side/users, and one layer for the supply side/suppliers) is getting more and more dissatisfactory. For tasks, such as an information search, tools like search engines have been created to circumvent many of the problems (and inefficiencies) that arise from this structure. However, search engines will only do as a short-term compromise. In the medium and long term, they will become increasingly insufficient and incapable to deal with future user and supplier needs and demands.A very promising solution for the whole situation is to add a third, intermediary layer to the structure of the Internet. This will enhance and improve the functionality of the Internet in many ways. Per layer, agents can be employed that can offer just the functionality that each layer needs. The main task of the middle layer is to make sure that agents and persons from different layers can communicate and co-operate without any problems.
It is not clear at this moment how many parties will be offering these services, and who exactly those parties will be. It may be expected that there will be quite a lot of parties (such as publishers and commercial information brokers) that will want to offer these services. (Internet) Users will not think too deeply about these two questions: they will want a service that delivers the best and quickest results, against the lowest possible costs. The one that is best at matching these needs, will be the one they use.
The three layer model is a very powerful and versatile application for the agent-technique; although individual agents can offer many things, they can offer and do so much more when employed/combined in this way. However, before we can really use the model, quite some things will need to be settled, decided and developed: a number of standards, a solid (universal) agent communication language, etcetera.
Introduction
To be able to make predictions about the next step(s) in the development of agents and the agent technique, several factors have to be considered. In this chapter the past and present of agents is given a closer look. There are several parties and factors that are related to these, and they will be looked at in the next sections.The first factor, which will be looked at rather briefly in the next section, is about links between developments in the area of computers (in general) and agent technology.
Secondly, we will have a closer look at the human factor in agent developments: agent users, the suppliers & developers of agents, and the government. In these sections it will be clarified why there is not such a thing as the user or the supplier, and what benefits governments can get from the agent technology.
Lastly, past and current developments on and around the Internet will be subject to a more detailed scrutiny. Each section will start with the state of affairs and general remarks with regard to that its subject and will then move on to indicate the links between this factor or party and the agent-technique.
Most of the information in this chapter, is of a rather general nature, and could just as well have been put in the next chapter. However, this would have resulted in one, huge chapter, which does not make it all very comprehensible or readable. Instead of that, it has been chosen to structure it the way it is now: divided over two chapters, where chapter five built a basis for, and raises questions about, issues that are discussed in chapter six [ 62 ].
Computers and the agent-technique
The developments on and around the Internet are bearing a strong resemblance to the development of computers and their interfaces. In the very beginning, computers were hardly user-friendly, they were commandline-driven and had no form of on-line help whatsoever. Slowly this changed when the first help functions were added. One of the most important changes has been the introduction of the Graphical User Interface (GUI), which enabled a much more abstract view on the operation of a computer. The popularity of computers, particularly that of home computers or PCs, is largely due to the introduction and further developments of the GUI.The Internet developments have followed this pattern in many ways. At first there were not many people using it, and most of them were highly educated users who were well capable of working on it without much support or nice interfaces. With the introduction of the Internet's own "graphical user interface" - the World Wide Web in combination with its graphical browsers - this changed drastically. From that moment, even novice users are able to use the various Internet services without having to know how each individual service should be used.
After the introduction of GUIs on computers followed a massive production of all kinds of applications and programs, most of which exploited GUI capabilities as much as possible. The same is bound to happen on the Internet too. The major difference between these applications and the applications that have been written for PCs and the like, is that the former will have to be more flexible and robust. To put it more boldly: they will have to be more intelligent to be able to function properly in the dynamic and uncertain environment the Internet is known to be.
Agents are meant to do precisely that.
At this moment, agents are offering this functionality in a very simple form. The chosen form is usually that of a forms-based interface, or that of a so-called wizard. These latter wizards, which are basically small background processes, may be considered as simple predecessors of real agents, as they are very straight-forward (they are usually driven by a set of if-then rules) and are neither very intelligent nor are they autonomous.
How this is all (expected or predicted) to change, will be described in chapter six.
The User
At this moment, most users of the agent technique are researchers and a small part of the WWW user population [ 63 ]. But who will be the users of the future, and what will their needs and demands be? This is an important question, as user-acceptance of agents (leading to user-demand) is one of the key factors for agent success.SRI International has conducted a psychographic research into the users of the World Wide Web [ 64 ]. The effort of this research was to augment standard demographics (such as age, income and gender) with a psychographic analysis of the WWW users¾[ 65 ]. They have used their own psychographic system (VALS 2) to explore the psychology of people's choices and behaviour on the WWW.
What makes the results of their research interesting, apart from the unusual (psychological) approach, is their finding that the Web has two very different audiences:
"The first is the group that drives most of the media coverage and stereotypes of Web users, the "upstream" audience. Comprising 50% of the current Web population, this well-documented group are the upscale, technically oriented academics and professionals that ride on a variety of institutional subsidies. Yet because this group comprises only 10% of the US population [...], their behaviours and characteristics are of limited usefulness in understanding the future Web.
The second Web audience comprises a diverse set of groups that SRI calls the Web's "other half." Accounting for the other 90% of U. S. society, these groups are where Internet growth will increasingly need to take place if the medium is to go mainstream."
Although this research comprises US users only, it still indicates that it would be a bad policy to talk and predict about the needs, preferences and motivations of the WWW/Internet user, as there is a broad variety of (types of) users. It is therefore important to find out which of these groups will be the most dominant and most important ones. This could even mean that groups of users have to be accounted for in the future, that are not using the WWW and the Internet right now:
"Many information-intensive consumers in the US population are in the other-half population rather than the upstream population. These particular other-half consumers report the highest degree of frustration with the Web of any population segment. Although they drive much of the consumer-information industry in other media, they as a group have yet to find the Web particularly valuable."
The "information have-nots" (a term coined by SRI) are not able to use the Internet and its services as result of a low income, but because of limited education. Tackling this problem requires an approach that is completely different from the one that is used at this moment to ensure that everybody can use the "information highway".
Agent technology can be brought into action here. Not that agents can solve the entire problem as described, but they can do their bit by making usage of the Internet (and computers as well) more user-friendly and easier. At this moment a lot of research is done in the area of so-called interface agents. These are agents whose main purpose is to provide an easy-to-use interface to complex systems such as the Internet, but also to computers in general. By means of such things as animated characters, computers and all kinds of other systems are given a more human appearance. This will make it easier for both novices and experts to operate them.
The Suppliers & The Developers
As much as there is not such a thing as the user, there also is not such a thing as the developer or the supplier. Until recently, developers of Internet applications and techniques were mostly (academic) researchers. With the emergence of the Internet as a commercial market, many other parties are starting to do research and develop techniques and applications for the Internet:"The emergence of the Internet and the World Wide Web has created a heightened demand for intelligent software agency. From a functional perspective, utilisation of the Web is moving from a scattered browsing model to an efficient point-to-point information transfer medium. This trend has (and is) driving the intelligent agent development from academic research environments and proprietary corporate uses to mass commercial usage." - "Intelligent Agents: a Technology and Business Applications analysis" by Mark Nissen
Moreover, many suppliers of information and/or services play a double role as they are (becoming) developers as well.
This has its effects on developments in the agent technique. Aspects that were of minor importance in the past, such as profitability of a technique and whether or not it meets a certain market or user demand (and how well this demand has been met), are becoming major issues now. Companies use the Internet and agent-based applications as a means to draw attention to other products they sell (e.g. like Sun Microsystems who use the Java technique to sell more Internet servers [ 66 ]) or as a profitable extension of existing products (e.g. like IBM who are developing agents to extend their groupware and network software packages).
So, predicting tomorrow's developments depends strongly on who is leading developments today. A commercial 'leader' will want agents to have quite different characteristics compared to, say, academic researchers. An overview of these differing aims is given in the following table:
Commercial developers' aims:
Non-commercial developers' aims:
1.
The aim usually is to move on to the practical implementation as soon as the related theory has been sufficiently worked out (i.e. theoretical research should be sufficiently elaborated, but does not need to be exhaustive, at least not immediately);
Non-commercial developers will (most probably) first do extensive research into a complete (and well-defined) concept or application, before moving on to sub concepts and the practical implementation (if they move on to this stage at all);
2.
Agents should be profitable - somehow - within a foreseeable period of time;
Agents may turn out to be profitable (or have potential to be so), but this is not an explicit aim;
3.
User/market demand(s) plays a very important role in the development process. Because of this importance however, unforeseen applications or demands may be overlooked;
Theoretical soundness, robustness and completeness are most likely to be important factors in the development process. User/market demands usually do not come into play until the practical implementation stage is reached (and may not be always that well known). Research may also tend to stay in the theoretical stage too long;
4.
Commercial developers will probably not be extremely interested in developing generally agreed upon, open standards (unless this standard is the one they have invented themselves).
The aim (although not always explicitly) is to come to general/open standards, or at least reach a consensus on vital issues, as this makes it easy to work together with other groups and share results (preventing duplicate work/research from being done).
Neither of these two "extremes" is very desirable: agents should not remain "an interesting research object" until eternity, but neither should research be aimed at merely scoring quick results.
A lot of attention should be paid to the demands of users (and other parties) in 'the real world'. However, care should be taken that not only the needs of the largest or the most profitable user groups are catered for, but also those of smaller groups and even of user communities that have yet to be discovered.
Some developers find that the development and support costs of agents are about the same as with other forms of development [ 67 ]. Most developers create applications for a single domain. Because they control the domain [ 68 ], they can manage the costs of development and support. In the report, developers predict an increase in cost once agents become mobile, irrespective of whether one single agent model (i.e. all agents use the same language, such as Telescript) or several models are used [ 69 ].
Furthermore, most vendors indicated that agent-empowerment will make a difference, but they are (still) struggling to help their user community (existing and prospective) understand what the agent-enabled applications could do. "In some markets, such as network management, "agents" are a required item to sell (even though experience-to-date shows limited user adoption of the agent capabilities)."
The Government
It is currently impossible extract one single governmental policy or vision with regard to the Internet from all the individual policies: there are as many visions of the information future as there are sectors of the economy helping to create them.What can be more or less concluded is that at this moment, governments [ 70 ] and politicians are not interested in agent technology per se. However, most of them state in their future plans for the Internet (or National Information Infrastructure (NII) [ 71 ] in case of the United States) that both individuals (or civilians) as well as companies and institutions should be able to make maximum use of it: users of the Internet should have free access to a broad variety of information (such as information from the government) and be able to chose from an equally broad variety of services. Services and information which every company or institution should be enabled to offer freely (with as little restrictions as possible).
But what use is all this information when users (i.e. civilians) are not able to find it, or are not able to access the Internet at all? How do users find out if (and which) services are being offered, and - if they find them - will they be able to use them (properly)?
To all appearances it seems that, although governments and politicians do not say it in so many words, agent technology - preferably combined with the three layer model as seen in chapter four - is a powerful and versatile tool that could be used to achieve this aim. Many application areas (and applications) are sketched in the various policy plans, each of them presupposing there to be a powerful, "intelligent" technology that makes it all possible: agent technology may very well be what they are looking for (but it is - for the time-being - unknown to them).
For instance, it has been stated that the development of applications for the "National Information Infrastructure" will be predicated on two other developments [ 72 ]. The first is "creating the underlying scaleable computing technologies for advanced communication services over diverse bitways, effective partitioning of applications across elements of the infrastructure, and other applications support services that can adapt to the capabilities of the available infrastructure". The second one is much more interesting with regard to agents (and more clearly linked to it), and is almost identical to the aims and (future) possibilities of agent technology and the three layer model:
"... creating and inserting an intelligent service layer that will significantly broaden the base of computer information providers, developers, and consumers while reducing the existing barriers to accessing, developing, and using advanced computer services and applications. In parallel with these activities, a more effective software development paradigm and technology base will be developed. This will be founded on the principles of composition rather than construction, solid architectures rather than ad hoc styles, and more direct user involvement in all stages of the software life cycle."
As we saw earlier, it is not low income that has kept, and is keeping, certain communities from using the "Information Superhighway", but a lack of (certain) education or skills. Agents could be used in an attempt to bridge this gap, and to prevent the government from only addressing the needs of a small part of the civilians of the information society:
"... Actualizers (highly educated persons who work in academic or technical fields) [...] are what all the excitement is about when "the consumer Internet" is invoked. The problem is that the fast-growing consumer Internet that most observers anticipate will saturate the Actualizer population relatively quickly, leaving the question of who drives continued growth. [ 73 ]"
Moreover, the fact that the government in most countries is both one of the biggest suppliers as well as one of the biggest consumers of information stresses the need even more for governments to address this problem. Currently, they are usually doing this rather passively by financing projects of large companies, hoping that they will come up with the techniques and applications to handle the situation. In the future, it may be better if governments started to play a more active role, just like the active role they are pursuing with regard to (general) Internet developments.
The Internet & The World Wide Web
Which important Internet developments can currently be observed?
1. The number of people using the Internet is growing rapidly: in the early years of Internet (the eighties and the very beginning of the nineties) most of its users were researchers and (American) public servants. These users were highly educated, were familiar with computers and/or networks, and knew how to use the various Internet services.
However, most of the users that step onto the Internet today are computer novices, they do not necessarily have a very high level of education, and are only partially familiar with the possibilities and techniques of networks in general and the Internet and its services in particular;
2. The number of parties offering services and information on the Internet has grown rapidly: an increasing number of companies, but also other parties such as the government, are starting to offer services on the Internet (usually through the World Wide Web). The amounts of money that is invested in 'Internet presence' and the like have been increasing since 1993 (when businesses and media start to take notice of the Internet); To get an idea of just how rapid the number of hosts [ 74 ] on the Internet is growing: in January 1996, compared to January 1995, the number of hosts had doubled to a staggering number of over 9 million Internet hosts. See Zakon's Timeline for further and more detailed information [ 75 ];
3. The growth in the number of people using the Internet is outrunning the increase of available bandwidth: although large investments are being made in faster connections (for instance by replacing coaxial or copper wires by optical fibre) and more powerful backbones [ 76 ], the demand for bandwidth is outrunning the supply by miles. User, especially those Internet users that have been working on the Internet since the early days, are complaining about the overcrowdedness of the Internet, which leads to moments where it is nearly impossible to connect to servers or where transferring data takes ages. Internet users will have to live with this 'inconvenience', as it seems most unlikely that the growth of bandwidth will catch up soon with user growth;
4. Since 1995 the World Wide Web is the most popular Internet service: up till 1995 e-mail used to be the most used service on the Internet. However, because it is user-friendly, easy to use, and looks "cool" and attractive, the World Wide Web has taken over first place (the WWW is declared as one of the two technologies of 1995 [ 77 ]). Moreover, the WWW can serve as a sort of "umbrella" to put over other Internet services such as FTP or Gopher. Interfacing with a software archive through the WWW is much easier than using FTP itself: the user can usually do most (if not all) of the work with only a mouse and does not need to know the various commands to move around the archive and download (i.e. get) software from it. The same goes for most of the other Internet services [ 78 ]. Through the World Wide Web, users gain access to sheer endless amounts of information and services. This is one of the most important reasons why (big) companies are starting to offer services and information on the WWW: when interesting information is combined cleverly with corporate (commercial) information, a company can gain massive exposure to users (all of which may very well be potential customers) and collect all sorts of information about them (for instance through feed-back given by the users themselves);
5. The emerging technologies of 1995 are mobile code (such as Java), Virtual environments ( VRML) and collaborative tools.
What influence do these developments have on agent technology and/or how are they linked to it? One of the most remarkable developments is the high popularity of the World Wide Web. This popularity seems to indicate the need of users for a single, user-friendly interface that hides most (or even all) of the different techniques (actually: services) that are needed to perform certain tasks on the Internet:
"The Web appears to provide what PC owners have always wanted: the capability to point, click, and get what they want no matter where it is. Whereas earlier manifestations of the information revolution bypassed many people who were uncomfortable with computing technology, it appears that the Web is now attracting a large cross section of people, making the universality of information infrastructure a more realistic prospect. If the Web is a first wave (or a second, if the Internet alone is a first), it is likely that further advances in utility and application will follow. [ 79 ]"
Developers of browser software are jumping onto this trend by creating increasingly versatile software packages. For instance, the newest version of Netscape - the most popular browser at this moment - can be used as an WWW browser, but also as a newsreader (for using Usenet) and a mail program (to send and receive e-mail). In fact, the booming popularity of the WWW is largely due to the versatile browsers that have been written for it.
Agents can offer this functionality as well. Better still: they can do it better with improvements such as greater software and hardware independence, extended functionality and flexibility. And they can easily be combined with open standards (such as the three layer model).
The World Wide Web may very well be considered as the first step or stepping-stone towards using more sophisticated technologies (e.g. intelligent software agents) and developing open standards for the Internet.
A growing problem on the Internet at this moment, is the availability of bandwidth. A salient detail in this matter is the fact that currently agents are partly the cause of this. A specific class of agents - information gathering agents, called worms and spiders, which are used to gather information about the contents of the Internet for use in search engines - are consuming quite a lot of bandwidth with their activities. The major reason for this is the fact that for every individual search engine a whole bunch of such agents is gathering information. The gathered information is not shared with other search engines, which wastes considerable amounts of bandwidth [ 80 ]. However, as agent technology evolves this will change. Agents can then be brought into action to help reduce the waste of bandwidth [ 81 ]. This reduction is achieved by such things as:
- Executing tasks, such as searches, locally (on the remote service) as much as possible. The agent only sends the result of a search over the Internet to its user;
- Using results and experiences of earlier performed tasks to make future executions of the same task more efficient, or even unnecessary. Serious attempts are being made where agents share gained experience and useful information with others. Many user queries can then be fulfilled without the need to consult (i.e. use) remote services such as search engines;
- Using the "intelligence" of agents to perform tasks outside peak-hours, and to spread the load on the Internet more evenly. Furthermore, agents are better at pinpointing on which hours of the day there is (too) much activity on the Internet, especially since this varies between the days of the week as well.
More on this subject will follow in the next chapter.
Summary
This chapter has made general remarks to issues, parties and factors that are involved in the development of agents and agent-enabled applications. This has been done by looking at events from the (recent) past & present, which give us an insight into what has already been accomplished. Using the information from chapter five, we can now move on to chapter six to see what all is (most likely) going to be accomplished in the future and near-future.
Bjorn Hermans is currently working as an Internet Application Engineer at Cap Gemini B.V. in the Netherlands. This paper originally appeared as his thesis for his studies into Language & Artificial Intelligence at Tilburg University. Hermans' e-mail address is hermans@hermans.org and his Web site can be found at http://www.hermans.orgAcknowledgements
There are many persons that have contributed to the realisation of this paper, and I am very grateful to all those who did.
There are a few persons that I would especially like to thank: Jan de Vuijst (for advising me, and for supporting me with the realisation of this thesis), Peter Janca, Leslie Daigle and Dan Kuokka (for the valuable information they sent me), and Jeff Bezemer (for his many valuable remarks).
Literature
D. D'Aloisi, D. and V. Giannini, 1995. The Info Agent: an Interface for Supporting Users in Intelligent Retrieval, (November).
The High-Level Group on the Information Society. Recommendations to the European Council - Europe and the global information society (The Bangemann Report). Brussels, (May).
L. Daigle, 1995. Position Paper. ACM SigComm'95 - MiddleWare Workshop (April).
Daigle, Deutsch, Heelan, Alpaugh, and Maclachlan, 1995. Uniform Resource Agents (URAs). Internet-Draft (November).
O. Etzioni and D. S. Weld, 1994. A Softbot-Based Interface to the Internet, Communications of the ACM, vol. 37, no. 7 (July), pp 72-76.
O. Etzioni, O. and D. S. Weld, 1995. Intelligent Agents on the Internet - Fact, Fiction, and Forecast, IEEE Expert, no. 4, pp. 44-49, (August).
R. Fikes, R. Engelmore, A. Farquhar, and W. Pratt, 1995. Network-Based Information Brokers. Knowledge System Laboratory, Stanford University.
Gilbert, Aparicio, et al. The Role of Intelligent Agents in the Information Infrastructure. IBM, U. S.
IITA, Information Infrastructure Technology and Applications, 1993. Report of the IITA Task Group High Performance Computing, Communications and Information Technology Subcommittee.
P. Janca, 1995. Pragmatic Application of Information Agents. BIS Strategic Decisions, Norwell, U. S., (May).
Ted G. Lewis, 1995-1996. SpinDoctor WWW pages.
National Research Council, 1994. Realizing the Information Future - The Internet and Beyond. Washington D. C.
H. S. Nwana, 1996. Software Agents: An Overview. Intelligent Systems Research, BT Laboratories, Ipswich, U. K.
P. Resnick, R. Zeckhauser and C. Avery, 1995. Roles for Electronic Brokers, Cambridge, Mass.: MIT.
M. Rohs, 1995. WWW-Unterstützung durch intelligente Agenten. Elaborated version of a presentation given as part of the Proseminar "World-Wide-Web", Fachgebiet Verteilte Systeme des Fachbereichs Informatik der TH Darmstadt.
SRI International. Exploring the World Wide Web Population's Other Half, (June).
M. Wooldridge and N. R. Jennings, 1995. Intelligent Agents: Theory and Practice, (January).
R. H. Zakon, 1996. Hobbes' Internet Timeline v2.3a.
Information Sources on the Internet
The @gency: A WWW page by Serge Stinckwich, with some agent definitions, a list of agent projects and laboratories, and links to agent pages and other agent-related Internet resources.Agent Info: A WWW page containing a substantial bibliography on and Web Links related to Interface Agents. It does provide some information on agents in general as well.
Agent Oriented Bibliography: Note that as this project is at beta stage, response times might be slow and the output is not yet perfect. Any new submissions are warmly welcomed.
Artificial Intelligence FAQ: Mark Kantrowitz' Artificial Intelligence Frequently Asked Questions contains information about AI resources on the Internet, AI Associations and Journals, answers to some of the most frequently asked questions about AI, and much more.
Global Intelligence Ideas for Computers: A WWW page by Eric Vereerstraeten about "assistants or agents [that] are appearing in new programs, [and that] are now wandering around the web to get you informed of what is going on in the world". It tries to give an impression of what the next steps in the development of these agents will be.
Intelligent Software Agents: These pages, by Ralph Becket, are intended as a repository for information about research into fields of AI concerning intelligent software agents.
Intelligent Software Agents: This is an extensive list that subdivides the various types of intelligent software agents into a number of comprehensive categories. Per category, organisations, groups, projects and (miscellaneous) resources are listed. The information is maintained by Sverker Janson.
Personal agents: A walk on the client side: A research paper by Sharp Laboratories. It outlines "the role of agent software in personal electronics in mediating between the individual user and the available services" and it projects " a likely sequence in which personal agent-based products will be successful". Other subjects that are discussed are "various standardisation and interoperability issues affecting the practicality of agents in this role".
Project Aristotle: Automated Categorization of Web Resources: This is "a clearinghouse of projects, research, products and services that are investigating or which demonstrate the automated categorization, classification or organization of Web resources. A working bibliography of key and significant reports, papers and articles, is also provided. Projects and associated publications have been arranged by the name of the university, corporation, or other organization, with which the principal investigator of a project is affiliated". It is compiled and maintained by Gerry McKiernan.
SIFT: SIFT is an abbreviation of "Stanford Information Filtering Tool", and it is a personalised Net information filtering service. "Everyday SIFT gathers tens of thousands of new articles appearing in USENET News groups, filters them against topics specified by you, and prepares all hits into a single web page for you." SIFT is a free service, provided as a part of the Stanford Digital Library Project.
The Software Agents Mailing List FAQ: A WWW page, maintained by Marc Belgrave, containing Frequently Asked Questions about this mailing list. Questions such as "how do I join the mailing list?", but also "what is a software agent?" and "where can I find technical papers and proceedings about agents?" are answered in this document.
UMBC AgentWeb: An information service of the UMBC's Laboratory for Advanced Information Technology, maintained by Tim Finin. It contains information and resources about intelligent information agents, intentional agents, software agents, softbots, knowbots, infobots, etcetera.
40. P. Resnick, P., R. Zeckhauser and C. Avery, 1995. Roles for Electronic Brokers.41. Quote taken from L. Daigle, 1995. Position Paper. ACM SigComm'95 - MiddleWare Workshop, (April).
43. Note that this client may be a human user, or another software program.
44. L. Daigle et al., 1995. Uniform Resource Agents (URAs). Internet-Draft.
45. Other names that are used to name this layer are information intermediaries, information brokers, but also a term such as (intelligent) middleware. Throughout this thesis these terms will be used interchangeably.
46. For instance, IBM is doing research into this subject in their InfoMarket project.
47. i.e. the list of offered services and information individual suppliers provide to the middle layer/middle layer agents.
48. Responses are joined when individual sources come up with the same item or answer. Of course, somewhere in the query results it should be indicated that some items (or answers) have been joined.
49. For instance, when information about second-hand cars is requested, by stating that only the ten cheapest cars or the ten cars best fitting the query, should be returned.
50. This can be very handy in areas where a lot of very specific jargon is used, such as in medicine or computer science. A query (of either a user of intermediary agent) could then use common terms, such as "LAN" and "IBM", whereas the agent of a database about computer networks would automatically translate this to a term such as "Coaxial IBM Token-ring network with ring topology".
51. This will happen only if this has been explicitly requested by the user agent, as normally this is a task for the user agent.
52. P. Resnick, P., R. Zeckhauser and C. Avery, 1995. Roles for Electronic Brokers.
53. Human information intermediaries are persons or organisations that can effectively and efficiently meet information needs or demands. The difference between information intermediaries and information brokers, is that the former (usually) only asks for a reimbursement of any expenses that were made to fulfil a certain information need/demand (which may include a modest hourly fee for the person working on the task). Information brokers are more expensive (their hourly fees usually start at a few hundred guilders), but they will usually be able to deliver results in a much shorter span of time. They can also offer many additional services, such as delivering the requested information as a complete report (with a nice lay-out, additional graphs, etcetera), or current awareness services.
54. See P. Resnick, P., R. Zeckhauser and C. Avery, 1995. Roles for Electronic Brokers. Two comments should be made by this list. The first is that they are about a special class of intermediaries: brokers. The second comment relates to this speciality: the given limitations are strongly focused on information and services that have to be paid for and/or that call for some form of negotiation, while in this thesis this aspect of information and services is left aside (i.e. "ignored") most of the time;
55. One intriguing class of mechanisms requires a broker because the budget balances only on average: the amount the producer receives in any single transaction may be more or less than the amount paid by the customer, and the broker pays or receives the difference.
56. For example, suppose a mediator's role is to inform a buyer and a seller whether a deal should go through, without revealing either's reservation price to the other, since such a revelation would influence subsequent price negotiations. An independent auditor can verify that a software mediator will reveal only the information it is supposed to; a human mediator's fairness is less easily verified.
57. See P. Resnick, P., R. Zeckhauser and C. Avery, 1995. Roles for Electronic Brokers.
58. D. Kuokka and L. Harada, 1992. "Integrating Information via Matchmaking," Small Journal Name, no. 9, pp 101-121.
59. Patil et al., 1992. "The DARPA Knowledge Sharing Effort: Progress report," In: Proceedings of the Third International Conference on Principles of Knowledge Representation and Reasoning.
60. As pointed out previously, one of the benefits of matchmaking is that it allows providers to take a more active role in information retrieval. Thus, just as requests can be viewed as an effort to locate an information provider, an advertisement can be viewed as an effort to locate a consumer's interests. This raises serious privacy considerations (imagine a consumer asking for a list of automobile dealerships only to be bombarded by sales offers from all of the dealerships). Fortunately, the various modes of matchmaking can include exchanges that preserve either party's anonymity.
61. So, to "actively seek" does not mean that producers will be able to find out just exactly which users are looking for which information. In Kuokka and Harada, op. cit., it is explicitly stated that their matchmaker will never offer this "service" to producers. More than that, they will not even allow producers to find out what exactly other producers are offering (i.e. they are not allowed to view an entire description of what other producers are offering), nor are they able to find out which producers are also active as searchers of information (i.e. are both offering as well as asking certain information and/or services from the Matchmaker).
62. So "Agent Trends & Developments - General remarks" may have been a good name for this chapter as well.
63. This group is comprised of mostly experienced, academic users, who like to experiment with and try out early (test)versions of agents or agent-based applications.
64. SRI International, 1995. Exploring the World Wide Web Population's Other Half, (June).
65. But the findings and conclusions of their research can very well be extended to allInternet users.
66. Java itself is not an agent-application. Yet, the Java Agent Template is available which "provides basic agent functionality packaged as a Java application. This agent can be executed as a stand alone application or as an applet via a WWW browser".
67. P. Janca, 1995. Pragmatic Application of Information Agents. BIS Strategic Decisions, (May).
68. i.e. they know exactly what domain they will be used in.
69. More about this will follow in the next chapter.
70. When, in this and the next chapter, something is being said about "the government" or "governments", the governments of the United States, various individual European countries and the European Union (as a whole) are meant. It were their policies that have been used for sections in chapters 5 and 6. For further and more detailed information, see a list of Information Policy Resources.
71. Throughout this thesis the National Information Infrastructure (NII) will be treated as being equal to the Internet, or rather: equal to the American part of the Internet. However, in policy plans of the United States, the NII is much more than the Internet alone. For simplicity's sake we will ignore that difference. See box 1.1 ("The NII: What is in a Name? A Range of Reactions") in "The Unpredictable Certainty: Information Infrastructure Through 2000".
72. ITA, Information Infrastructure Technology and Applications, 1993. Report of the IITA Task Group High Performance Computing, Communications and Information Technology Subcommittee.
73. SRI International, 1995. Exploring the World Wide Web Population's Other Half, (June).
74. A host is a service which offers information and/or Internet services such as an FTP archive or WWW-pages.
75. R. H. Zakon, 1996. Hobbes' Internet Timeline v2.3a. (February).
76. Backbones are large-capacity circuits at the heart of a network (in this case the Internet), carrying aggregated traffic over (relatively) long distances.
77. See Zakon, op. cit. Sun's JAVA technology was the other one.
78. It should be noted that the user-friendliness is strongly dependent on the program that is used to navigate the Internet: the so-called browser. The functionality of the various browsers can vary considerably. However, most WWW-users (about 80% at the beginning of 1996) use the popular Netscape browser which offers all of the functionality as is described above.
79. National Research Council, 1994. Realizing the Information Future - The Internet and Beyond.
81. Agents will help reduce the waste of bandwidth: they will not decrease the need for bandwidth.


Copyright © 1997, ƒ ¡ ® s † - m ¤ ñ d @ ¥